




前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯融合CNN与机器视觉的智能数码字符检测技术研究
选题意义背景
随着工业4.0和智能制造的快速发展,工业自动化检测技术在现代制造业中的应用日益广泛,全球工业自动化市场规模持续扩大,其中机器视觉作为自动化检测的核心技术,市场增长率保持在15%以上。在电子产品制造领域,数码管作为一种常用的显示器件,广泛应用于各种仪表、控制面板和电子设备中。传统的数码管字符检测主要依靠人工目视检查,这种方式不仅效率低下,而且容易受到人为因素的影响,导致检测准确率不稳定。
机器视觉技术是一门涉及计算机科学、图像处理、模式识别、人工智能等多学科的交叉技术。随着深度学习技术的快速发展和嵌入式计算能力的显著提升,机器视觉技术在工业检测领域的应用越来越深入。特别是在字符识别方面,传统的基于规则的方法逐渐被基于深度学习的方法所取代,检测准确率和鲁棒性得到了极大提升。 开发一套基于机器视觉的自动检测系统,实现数码管字符的快速、准确识别和分类,对于提高产品质量和生产效率具有重要意义。
数据集
数据获取
本课题中使用的数码字符数据集主要通过以下两种方式获取:
-
人工标注方式:使用labelImg软件对采集到的数码管显示图像进行手工标注,生成XML格式的标注文件。标注过程中,标注人员需要为每个数码管字符绘制边界框,并标注对应的字符类别(0-9)。这种方式虽然效率较低,但标注质量高,为后续的模型训练提供了可靠的基础数据。
-
自动生成方式:利用图像处理算法对已标注的图像进行数据增强,自动生成更多的训练样本。具体包括:
- 旋转变换:对原始字符图像在(-10°,10°)范围内以中心点为原点进行旋转,模拟实际检测中数码管可能的倾斜情况
- 缩放变换:对字符图像进行不同比例的放大和缩小操作,模拟摄像机与目标物之间距离变化导致的图像尺寸差异
- 平移变换:对字符图像进行水平和垂直方向的平移,增强字符分割效果
- 形态学变换:使用不同尺寸的结构元素对字符图像进行腐蚀或膨胀操作,模拟不同光照条件下的字符显示效果
通过这两种方式相结合,最终构建了一个包含大量多样化样本的数码字符数据集,为后续的算法训练和测试提供了充分的数据支持。
数据格式
数据集的基本信息如下:
-
数据格式:
- 图像数据:采用单通道灰度图像格式,像素值范围为0-255
- 标注数据:XML格式,包含字符的位置信息(xmin, ymin, xmax, ymax)和类别信息(name)
- 训练数据:经过预处理和归一化后的28×28像素的图像数据,存储为numpy数组格式
-
数据规模:
- 原始采集图像:500张数码管显示模块的高清图像
- 标注字符数量:每张图像平均包含5个字符,总计约2500个标注字符
- 数据增强后:通过旋转、缩放、平移和形态学变换等操作,将数据集扩充至约25000个字符样本
- 训练集:20000个样本(80%)
- 验证集:2500个样本(10%)
- 测试集:2500个样本(10%)
数据规模的扩展对于提高模型的泛化能力和鲁棒性具有重要意义,特别是对于深度学习模型而言,充足的数据量是保证模型性能的关键因素之一。
本课题的研究对象是七段式数码管显示的阿拉伯数字字符,共包含10个类别,具体定义如下:
| 类别编号 | 字符 | 描述 |
|---|---|---|
| 0 | 0 | 数字0 |
| 1 | 1 | 数字1 |
| 2 | 2 | 数字2 |
| 3 | 3 | 数字3 |
| 4 | 4 | 数字4 |
| 5 | 5 | 数字5 |
| 6 | 6 | 数字6 |
| 7 | 7 | 数字7 |
| 8 | 8 | 数字8 |
| 9 | 9 | 数字9 |
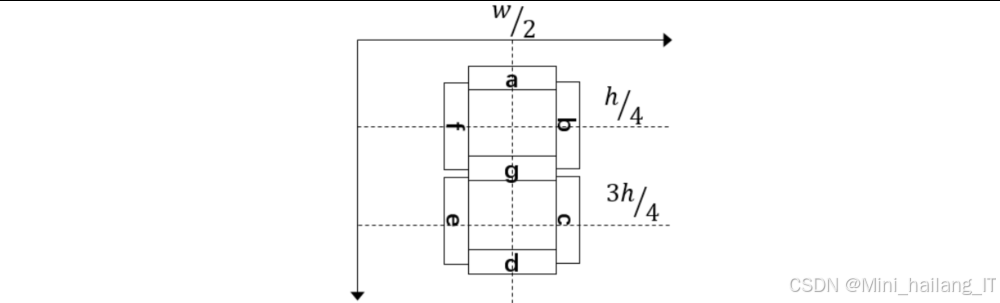
七段式数码管由七个不同位置的发光段组成,分别标记为a、b、c、d、e、f、g,不同的段组合可以显示不同的数字。每个数字的段码组合如下表所示:
| 数字 | a | b | c | d | e | f | g |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | 1 | 1 | 0 | 1 | 1 | 0 | 1 |
| 3 | 1 | 1 | 1 | 1 | 0 | 0 | 1 |
| 4 | 0 | 1 | 1 | 0 | 0 | 1 | 1 |
| 5 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| 6 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| 7 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 8 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 9 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
其中,1表示对应段点亮,0表示对应段熄灭。这种特殊的显示结构为字符识别提供了一定的几何特征基础。
数据分割策略
为了保证模型训练的有效性和评估的准确性,我们采用了科学的数据分割策略:
-
随机分层抽样:按照每个类别的样本数量比例,随机将数据集分为训练集、验证集和测试集。这样可以确保每个集合中各类别的分布相对均匀,避免因数据分布不均导致的模型训练偏差。
-
时间顺序分割:为了更好地模拟实际应用场景,我们还采用了基于时间顺序的数据分割方法,即使用早期采集的数据作为训练集,后期采集的数据作为测试集。这种方法可以更好地评估模型在面对新数据时的泛化能力。
-
交叉验证:在模型训练过程中,我们采用了5折交叉验证的方法,将训练集进一步划分为5个子集,依次使用其中4个子集作为训练数据,1个子集作为验证数据,最后取5次验证结果的平均值作为模型的最终性能指标。这种方法可以有效减少模型评估的随机性,提高评估结果的可靠性。
通过以上分割策略,我们可以全面评估模型的性能,并为模型选择和参数调优提供可靠的依据。
数据预处理
为了提高模型的训练效果和识别准确率,我们对原始数据进行了一系列预处理操作:
-
图像灰度化:将彩色图像转换为灰度图像,减少数据维度和计算量。灰度化采用加权平均法,计算公式为:Gray = 0.299×R + 0.587×G + 0.114×B。
-
图像去噪:使用中值滤波算法对灰度图像进行去噪处理,减少图像中的随机噪声和椒盐噪声。中值滤波的窗口大小为3×3,能够有效保留图像边缘信息的同时去除噪声。
-
图像二值化:将灰度图像转换为二值图像,突出字符区域,便于后续的字符分割和特征提取。通过对比平均灰度值法、双峰法和最大类间方差法(Otsu算法),我们最终选择了固定阈值200进行二值化处理,取得了较好的效果。
-
形态学处理:对二值图像进行形态学开运算,去除小的噪点和干扰,同时保持字符的基本形状不变。开运算使用3×3的结构元素,先腐蚀后膨胀。
-
字符分割:基于投影法进行字符分割,先进行竖直方向投影,找到字符间的间隙位置,将字符串分割成单个字符区域,然后进行水平方向投影,进一步精确字符的边界。
-
图像归一化:将分割后的单个字符图像归一化为28×28像素的标准尺寸,便于后续的特征提取和模型训练。归一化过程中使用了最近邻插值算法,在保证计算效率的同时,较好地保留了字符的特征信息。
-
数据标准化:对归一化后的图像数据进行标准化处理,将像素值从[0, 255]映射到[0, 1]区间,加速模型的收敛速度,提高训练效果。
通过以上预处理步骤,我们获得了高质量的训练数据,为后续的模型训练和测试奠定了坚实的基础。
功能模块
视觉检测单元是整个系统的核心,负责图像采集、处理和字符识别等关键任务。该模块基于STM32F7微控制器设计,主要功能包括:
-
图像采集:通过OV7725摄像头采集数码管显示字符的图像,并进行初步的图像缓存和预处理。摄像头采用手动可调焦镜头,确保图像清晰。
-
图像处理:对采集到的图像进行灰度化、滤波、二值化、形态学处理、字符分割等预处理操作,为后续的字符识别做准备。
-
字符识别:使用优化后的卷积神经网络算法对分割后的字符图像进行识别,输出识别结果。
-
通信控制:与机器人系统和测试工装进行通信,发送控制指令和接收状态信息。
-
数据存储:将检测结果和原始图像数据存储到SD卡中,便于后续分析和追溯。
-
实时操作系统:移植了Keil RTX5嵌入式实时操作系统,实现多任务管理和调度,确保系统的实时性和可靠性。
视觉检测单元的任务设计采用了模块化的方式,主要包括以下任务:
- 流程管理任务:负责协调各模块工作,处理通信和状态监控
- 图像采集预处理任务:负责图像的采集和预处理
- 字符识别任务:负责字符的分割和识别
- 结果分析任务:负责识别结果的分析和处理
- 数据存储任务:负责检测数据的存储和管理
上位机软件的用户界面设计简洁直观,操作方便,适合现场操作人员使用。同时,软件还提供了丰富的数据导出功能,支持将检测数据导出为Excel、CSV等格式,便于进一步的数据分析和处理。
算法理论
视觉系统标定
视觉系统标定是机器视觉应用中的关键步骤,直接影响到系统的测量精度和定位准确性。本系统的视觉标定主要包括摄像机标定和手眼标定两部分,摄像机标定的目的是建立摄像机图像坐标系与世界坐标系之间的映射关系,确定摄像机的内参和外参。
-
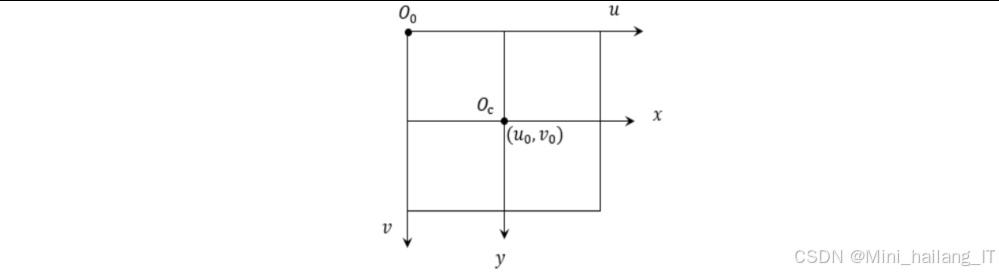
坐标系转换:
- 像素坐标系(u, v):图像传感器上的物理像素位置
- 图像坐标系(x, y):以图像中心为原点的二维坐标系
- 摄像机坐标系(Xc, Yc, Zc):以摄像机光心为原点的三维坐标系
- 世界坐标系(Xw, Yw, Zw):用户定义的三维坐标系
-
摄像机模型:采用针孔摄像机模型
手眼标定的目的是建立摄像机坐标系与机器人末端执行器坐标系之间的变换关系。本系统采用Eye-to-Hand标定方式,即摄像机固定安装,不随机器人末端执行器运动。
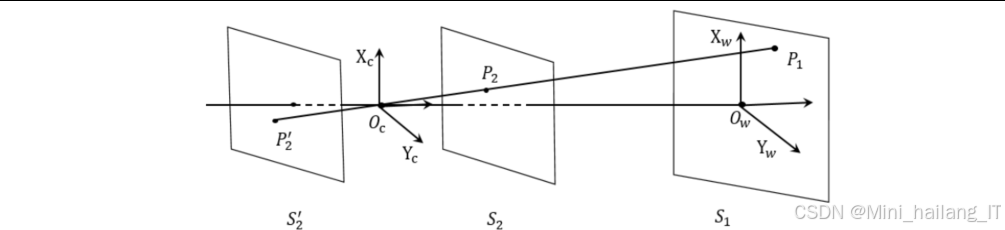
通过摄像机标定和手眼标定,我们建立了从图像像素到机器人坐标系的完整映射关系,为后续的精确定位和操作提供了基础。
图像预处理
图像预处理是字符识别的关键步骤,直接影响到后续识别的准确率。本系统采用了一系列图像处理算法,对采集到的原始图像进行处理,提取出清晰的字符区域。

灰度化是将彩色图像转换为灰度图像的过程,目的是减少数据维度和计算量。常用的灰度化方法包括最大值法、平均值法和加权平均法。本系统采用加权平均法,考虑了人眼对不同颜色的敏感度,
图像滤波的目的是去除图像中的噪声,提高图像质量。常用的滤波方法包括均值滤波、中值滤波和高斯滤波等。本系统采用中值滤波,能够有效去除椒盐噪声,同时保留图像的边缘信息。中值滤波的基本原理是用像素点邻域内的中值代替该像素点的值。
二值化是将灰度图像转换为二值图像的过程,目的是突出目标区域,便于后续的分割和特征提取。常用的二值化方法包括全局阈值法、局部阈值法和自适应阈值法等。本系统对比了平均灰度值法、双峰法和最大类间方差法(Otsu算法),最终选择了固定阈值200进行二值化处理,取得了较好的效果。
形态学处理是基于形状的图像处理技术,主要包括腐蚀、膨胀、开运算和闭运算等操作。本系统采用开运算(先腐蚀后膨胀)对二值图像进行处理,去除小的噪点和干扰,同时保持字符的基本形状不变。开运算使用3×3的结构元素。
字符分割是将字符串分割成单个字符的过程,是字符识别的前提。本系统采用基于投影的分割方法,具体步骤如下:
-
竖直投影:计算图像在竖直方向上的像素直方图,找到字符间的间隙位置,将字符串分割成单个字符区域。
-
水平投影:对分割后的单个字符区域进行水平投影,进一步精确字符的上下边界。
-
边界调整:根据投影结果,调整字符区域的边界,确保每个字符区域包含完整的字符信息。
图像归一化是将不同大小的字符图像转换为标准尺寸的过程,便于后续的特征提取和模型训练。常用的归一化方法包括最近邻插值、双线性插值和双三次插值等。本系统对比了最近邻插值和双线性插值两种算法,发现它们均能够满足归一化任务,且不会对字符特征造成破坏。考虑到计算效率和内存占用,最终选择了最近邻插值算法,将字符图像归一化为28×28像素的标准尺寸。
字符识别
本系统对比了四种不同的字符识别算法:基于几何特征的穿线识别法、模板匹配算法、三层全连接神经网络和卷积神经网络。通过实验分析,最终选择了识别准确率最高的卷积神经网络算法。
穿线识别法是一种基于数码管几何特征的识别方法。七段式数码管由七个不同位置的发光段组成,每个数字对应不同的段组合。穿线识别法通过在特定位置扫描字符图像,统计白色像素的数量,判断各段的点亮状态,从而识别字符。
模板匹配算法是一种基于图像相似度的识别方法。该方法预先建立字符模板库,然后计算待识别字符与模板的相似度,选择相似度最高的模板作为识别结果。常用的相似度度量方法包括绝对差总和、平方差总和和归一化积相关等。
三层全连接神经网络
三层全连接神经网络是一种经典的人工神经网络模型,包括输入层、隐含层和输出层。该模型通过反向传播算法训练,能够自动学习输入数据的特征,并建立输入与输出之间的映射关系。
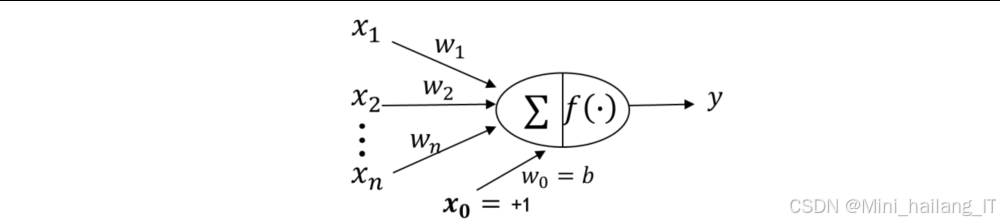
在本系统中,我们设计的三层全连接神经网络模型结构如下:
- 输入层:28×28=784个神经元,对应归一化后的字符图像
- 隐含层:128个神经元,使用ReLU激活函数
- 输出层:10个神经元,对应10个数字类别,使用Softmax激活函数
该模型的识别准确率约为90%,算法复杂度适中,但隐含层节点数的选择需要通过经验和实验确定,且对图像预处理的要求较高。
卷积神经网络
卷积神经网络(CNN)是一种专门用于图像处理的深度学习模型,具有局部连接、权值共享和池化等特点,能够有效提取图像的局部特征和全局特征。
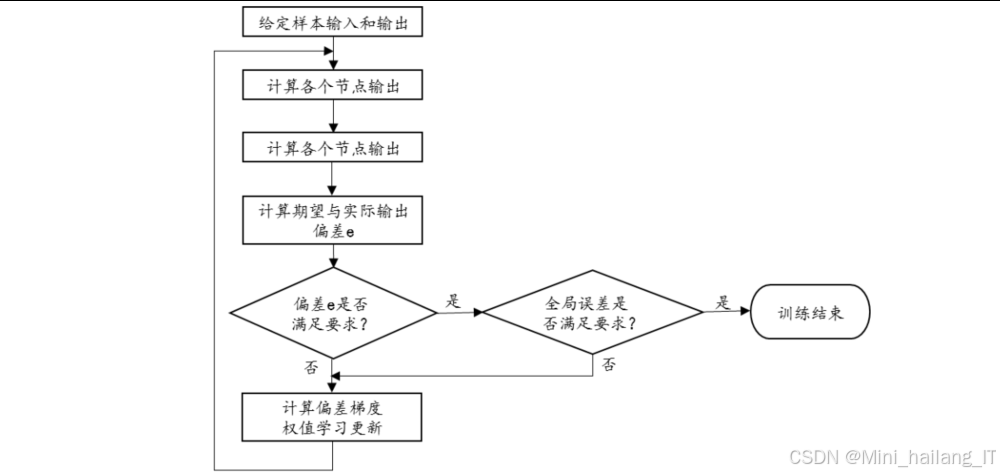
本系统设计了一个改进的LeNet-5卷积神经网络模型,结构如下:
- 输入层:28×28×1的灰度图像
- 卷积层1:3×3卷积核,12个特征图,ReLU激活函数
- 池化层1:2×2最大池化
- 卷积层2:3×3卷积核,24个特征图,ReLU激活函数
- 池化层2:2×2最大池化
- 卷积层3:3×3卷积核,48个特征图,ReLU激活函数,Dropout层(防止过拟合)
- 池化层3:2×2最大池化
- 全连接层1:96个神经元
- 输出层:10个神经元,对应10个数字类别,使用Softmax激活函数
核心代码介绍
图像预处理
图像预处理是字符识别的基础,以下代码展示了图像预处理的主要流程,包括灰度化、滤波、二值化和形态学处理等关键步骤。
// 图像预处理函数
void ImagePreprocess(uint8_t* srcImage, uint8_t* dstImage, int width, int height) {
uint8_t* grayImage = (uint8_t*)malloc(width * height);
uint8_t* binaryImage = (uint8_t*)malloc(width * height);
// 1. 灰度化处理
RGB2Gray(srcImage, grayImage, width, height);
// 2. 中值滤波去噪
MedianFilter(grayImage, grayImage, width, height, 3);
// 3. 二值化处理(固定阈值200)
Threshold(grayImage, binaryImage, width, height, 200, 255);
// 4. 形态学开运算(先腐蚀后膨胀)
Erode(binaryImage, binaryImage, width, height, 3);
Dilate(binaryImage, dstImage, width, height, 3);
free(grayImage);
free(binaryImage);
}
// RGB转灰度函数
void RGB2Gray(uint8_t* src, uint8_t* dst, int width, int height) {
int i, j, index;
for (i = 0; i < height; i++) {
for (j = 0; j < width; j++) {
index = i * width + j;
// 加权平均法:Gray = 0.299*R + 0.587*G + 0.114*B
dst[index] = (uint8_t)(0.299 * src[index*3] + 0.587 * src[index*3+1] + 0.114 * src[index*3+2]);
}
}
}
// 中值滤波函数
void MedianFilter(uint8_t* src, uint8_t* dst, int width, int height, int kernelSize) {
int i, j, k, l;
int offset = kernelSize / 2;
uint8_t* buffer = (uint8_t*)malloc(kernelSize * kernelSize);
for (i = offset; i < height - offset; i++) {
for (j = offset; j < width - offset; j++) {
// 收集邻域像素
int idx = 0;
for (k = -offset; k <= offset; k++) {
for (l = -offset; l <= offset; l++) {
buffer[idx++] = src[(i + k) * width + (j + l)];
}
}
// 冒泡排序找中值
for (k = 0; k < idx - 1; k++) {
for (l = 0; l < idx - k - 1; l++) {
if (buffer[l] > buffer[l + 1]) {
uint8_t temp = buffer[l];
buffer[l] = buffer[l + 1];
buffer[l + 1] = temp;
}
}
}
// 取中值
dst[i * width + j] = buffer[idx / 2];
}
}
free(buffer);
}
这段代码实现了图像预处理的主要功能。首先,通过RGB2Gray函数将彩色图像转换为灰度图像,采用加权平均法,考虑了人眼对不同颜色的敏感度。然后,使用中值滤波算法去除图像噪声,该算法能够有效保留图像边缘信息的同时去除椒盐噪声。接着,进行二值化处理,使用固定阈值200将灰度图像转换为二值图像,突出字符区域。最后,通过形态学开运算(先腐蚀后膨胀)进一步去除小的噪点和干扰,为后续的字符分割做准备。
字符分割
基于投影法的字符分割和图像归一化功能。首先,通过计算图像在竖直方向上的投影,找到字符间的间隙位置,从而将字符串分割成单个字符区域。然后,对于每个分割出的字符区域,进一步计算其在水平方向上的边界,得到完整的字符包围框。最后,使用最近邻插值算法将分割出的字符图像归一化为28×28像素的标准尺寸,便于后续的字符识别。字符分割是将字符串分割成单个字符的关键步骤,以下代码展示了基于投影法的字符分割实现。
// 字符分割函数,返回分割后的字符数量
int CharacterSegmentation(uint8_t* binaryImage, int width, int height, charInfo_t* charInfo, int maxCharNum) {
int* verticalProjection = (int*)malloc(width * sizeof(int));
int charCount = 0;
int i, j;
// 1. 计算竖直方向投影
memset(verticalProjection, 0, width * sizeof(int));
for (i = 0; i < height; i++) {
for (j = 0; j < width; j++) {
if (binaryImage[i * width + j] == 255) {
verticalProjection[j]++;
}
}
}
// 2. 基于竖直投影分割字符
int startPos = -1;
for (j = 0; j < width; j++) {
// 检测字符起始位置
if (startPos == -1 && verticalProjection[j] > 0) {
startPos = j;
}
// 检测字符结束位置
else if (startPos != -1 && verticalProjection[j] == 0) {
// 确保分割的区域有足够的宽度
if (j - startPos > 5) {
// 计算字符的水平边界
charInfo[charCount].x = startPos;
charInfo[charCount].width = j - startPos;
// 计算字符的垂直边界
int top = height, bottom = 0;
for (i = 0; i < height; i++) {
for (int k = startPos; k < j; k++) {
if (binaryImage[i * width + k] == 255) {
if (i < top) top = i;
if (i > bottom) bottom = i;
}
}
}
charInfo[charCount].y = top;
charInfo[charCount].height = bottom - top + 1;
charCount++;
if (charCount >= maxCharNum) {
break;
}
}
startPos = -1;
}
}
// 处理最后一个字符
if (startPos != -1 && width - startPos > 5) {
// 计算字符的水平边界
charInfo[charCount].x = startPos;
charInfo[charCount].width = width - startPos;
// 计算字符的垂直边界
int top = height, bottom = 0;
for (i = 0; i < height; i++) {
for (int k = startPos; k < width; k++) {
if (binaryImage[i * width + k] == 255) {
if (i < top) top = i;
if (i > bottom) bottom = i;
}
}
}
charInfo[charCount].y = top;
charInfo[charCount].height = bottom - top + 1;
charCount++;
}
free(verticalProjection);
return charCount;
}
// 图像归一化函数
void ImageNormalize(uint8_t* srcImage, uint8_t* dstImage, int srcWidth, int srcHeight,
int srcX, int srcY, int charWidth, int charHeight, int normWidth, int normHeight) {
// 最近邻插值算法
float scaleX = (float)charWidth / normWidth;
float scaleY = (float)charHeight / normHeight;
for (int i = 0; i < normHeight; i++) {
for (int j = 0; j < normWidth; j++) {
int srcI = (int)(i * scaleY) + srcY;
int srcJ = (int)(j * scaleX) + srcX;
// 边界检查
if (srcI >= 0 && srcI < srcHeight && srcJ >= 0 && srcJ < srcWidth) {
dstImage[i * normWidth + j] = srcImage[srcI * srcWidth + srcJ];
} else {
dstImage[i * normWidth + j] = 0;
}
}
}
}
字符分割是字符识别的关键步骤,直接影响到后续识别的准确率。本代码通过投影法实现字符分割,具有计算简单、分割效果好等优点。同时,图像归一化确保了不同大小的字符图像能够被统一处理,提高了识别的一致性和准确率。
卷积神经网络
构建了轻量级卷积神经网络推理流程,网络架构精心设计为 3 个卷积层、3 个池化层与 2 个全连接层的组合,核心采用 ReLU 激活函数引入非线性特征表达能力,搭配 2×2 最大池化算法实现特征维度压缩与关键信息保留。推理过程始于输入数据预处理,将 8 位灰度图像精准转换为 CMSIS-NN 库兼容的 Q7 定点格式,为嵌入式平台的高效运算奠定基础。随后通过三层卷积操作逐步完成特征提取:第一层 3×3 卷积核捕捉低级视觉特征,第二层深化特征表达,第三层提炼高级语义特征,每轮卷积后均紧跟 ReLU 激活与最大池化步骤,既避免梯度消失问题,又有效降低特征图尺寸与计算复杂度,最终通过全连接层将高维卷积特征映射至目标类别空间,再经简化 Softmax 操作(取最大值索引)快速输出识别结果。卷积神经网络是本系统的核心算法,以下代码展示了基于CMSIS-NN库的卷积神经网络实现。
// CNN模型结构定义
typedef struct {
// 卷积层参数
q7_t conv1_weights[CONV1_KERNEL_SIZE * CONV1_KERNEL_SIZE * CONV1_IN_CHANNELS * CONV1_OUT_CHANNELS];
q7_t conv1_bias[CONV1_OUT_CHANNELS];
q7_t conv2_weights[CONV2_KERNEL_SIZE * CONV2_KERNEL_SIZE * CONV2_IN_CHANNELS * CONV2_OUT_CHANNELS];
q7_t conv2_bias[CONV2_OUT_CHANNELS];
q7_t conv3_weights[CONV3_KERNEL_SIZE * CONV3_KERNEL_SIZE * CONV3_IN_CHANNELS * CONV3_OUT_CHANNELS];
q7_t conv3_bias[CONV3_OUT_CHANNELS];
// 全连接层参数
q7_t fc1_weights[FC1_IN_FEATURES * FC1_OUT_FEATURES];
q7_t fc1_bias[FC1_OUT_FEATURES];
q7_t fc2_weights[FC2_IN_FEATURES * FC2_OUT_FEATURES];
q7_t fc2_bias[FC2_OUT_FEATURES];
// 缩放参数
q31_t conv1_scale;
q31_t conv2_scale;
q31_t conv3_scale;
q31_t fc1_scale;
q31_t fc2_scale;
} CNN_Model_t;
// 字符识别函数
int CharacterRecognition(uint8_t* inputImage, CNN_Model_t* model) {
// 定义各层的输入输出缓冲区
q7_t conv1_output[CONV1_OUT_HEIGHT * CONV1_OUT_WIDTH * CONV1_OUT_CHANNELS];
q7_t pool1_output[POOL1_OUT_HEIGHT * POOL1_OUT_WIDTH * POOL1_OUT_CHANNELS];
q7_t conv2_output[CONV2_OUT_HEIGHT * CONV2_OUT_WIDTH * CONV2_OUT_CHANNELS];
q7_t pool2_output[POOL2_OUT_HEIGHT * POOL2_OUT_WIDTH * POOL2_OUT_CHANNELS];
q7_t conv3_output[CONV3_OUT_HEIGHT * CONV3_OUT_WIDTH * CONV3_OUT_CHANNELS];
q7_t pool3_output[POOL3_OUT_HEIGHT * POOL3_OUT_WIDTH * POOL3_OUT_CHANNELS];
q7_t fc1_output[FC1_OUT_FEATURES];
q7_t output[FC2_OUT_FEATURES];
// 输入数据转换为Q7格式
q7_t input[INPUT_HEIGHT * INPUT_WIDTH * INPUT_CHANNELS];
for (int i = 0; i < INPUT_HEIGHT * INPUT_WIDTH * INPUT_CHANNELS; i++) {
input[i] = (q7_t)((inputImage[i] / 255.0f) * 127.0f);
}
// 第一层卷积
arm_convolve_HWC_q7_RGB(input, INPUT_HEIGHT, INPUT_WIDTH, INPUT_CHANNELS,
model->conv1_weights, CONV1_OUT_CHANNELS, CONV1_KERNEL_SIZE,
CONV1_PADDING, CONV1_STRIDE, model->conv1_bias, model->conv1_scale,
conv1_output, CONV1_OUT_HEIGHT, CONV1_OUT_WIDTH, NULL);
// ReLU激活
arm_relu_q7(conv1_output, CONV1_OUT_HEIGHT * CONV1_OUT_WIDTH * CONV1_OUT_CHANNELS);
// 第一层池化
arm_max_pool_q7_HWC(conv1_output, CONV1_OUT_HEIGHT, CONV1_OUT_WIDTH, CONV1_OUT_CHANNELS,
POOL1_KERNEL_SIZE, POOL1_PADDING, POOL1_STRIDE, POOL1_OUT_HEIGHT, POOL1_OUT_WIDTH,
pool1_output);
// 第二层卷积
arm_convolve_HWC_q7_RGB(pool1_output, POOL1_OUT_HEIGHT, POOL1_OUT_WIDTH, POOL1_OUT_CHANNELS,
model->conv2_weights, CONV2_OUT_CHANNELS, CONV2_KERNEL_SIZE,
CONV2_PADDING, CONV2_STRIDE, model->conv2_bias, model->conv2_scale,
conv2_output, CONV2_OUT_HEIGHT, CONV2_OUT_WIDTH, NULL);
// ReLU激活
arm_relu_q7(conv2_output, CONV2_OUT_HEIGHT * CONV2_OUT_WIDTH * CONV2_OUT_CHANNELS);
// 第二层池化
arm_max_pool_q7_HWC(conv2_output, CONV2_OUT_HEIGHT, CONV2_OUT_WIDTH, CONV2_OUT_CHANNELS,
POOL2_KERNEL_SIZE, POOL2_PADDING, POOL2_STRIDE, POOL2_OUT_HEIGHT, POOL2_OUT_WIDTH,
pool2_output);
// 第三层卷积
arm_convolve_HWC_q7_RGB(pool2_output, POOL2_OUT_HEIGHT, POOL2_OUT_WIDTH, POOL2_OUT_CHANNELS,
model->conv3_weights, CONV3_OUT_CHANNELS, CONV3_KERNEL_SIZE,
CONV3_PADDING, CONV3_STRIDE, model->conv3_bias, model->conv3_scale,
conv3_output, CONV3_OUT_HEIGHT, CONV3_OUT_WIDTH, NULL);
// ReLU激活
arm_relu_q7(conv3_output, CONV3_OUT_HEIGHT * CONV3_OUT_WIDTH * CONV3_OUT_CHANNELS);
// Dropout层(在推理阶段直接跳过)
// 第三层池化
arm_max_pool_q7_HWC(conv3_output, CONV3_OUT_HEIGHT, CONV3_OUT_WIDTH, CONV3_OUT_CHANNELS,
POOL3_KERNEL_SIZE, POOL3_PADDING, POOL3_STRIDE, POOL3_OUT_HEIGHT, POOL3_OUT_WIDTH,
pool3_output);
// 展开特征图(为全连接层做准备)
q7_t flattened[POOL3_OUT_HEIGHT * POOL3_OUT_WIDTH * POOL3_OUT_CHANNELS];
memcpy(flattened, pool3_output, sizeof(flattened));
// 第一层全连接
arm_fully_connected_q7_opt(flattened, model->fc1_weights,
POOL3_OUT_HEIGHT * POOL3_OUT_WIDTH * POOL3_OUT_CHANNELS,
FC1_OUT_FEATURES, model->fc1_scale, model->fc1_bias, fc1_output, NULL);
// ReLU激活
arm_relu_q7(fc1_output, FC1_OUT_FEATURES);
// 第二层全连接(输出层)
arm_fully_connected_q7_opt(fc1_output, model->fc2_weights, FC1_OUT_FEATURES,
FC2_OUT_FEATURES, model->fc2_scale, model->fc2_bias, output, NULL);
// Softmax激活(简化版,直接取最大值索引作为识别结果)
int maxIndex = 0;
int16_t maxValue = output[0];
for (int i = 1; i < FC2_OUT_FEATURES; i++) {
if (output[i] > maxValue) {
maxValue = output[i];
maxIndex = i;
}
}
return maxIndex; // 返回识别的数字(0-9)
}
充分发挥 CMSIS-NN 库的嵌入式优化特性与定点运算的资源高效性,实现了神经网络在中端嵌入式处理器上的高性能运行。库中针对性优化的arm_convolve_HWC_q7_RGB卷积函数、arm_max_pool_q7_HWC池化函数及arm_fully_connected_q7_opt全连接函数,从底层计算逻辑上提升了运算效率,适配嵌入式平台的硬件架构特点;而采用 Q7 定点运算替代传统浮点运算,不仅大幅削减了计算量,更显著降低了内存占用与功耗消耗,完美契合 STM32F7 等中端处理器的资源约束。整套实现将复杂的神经网络推理流程与嵌入式平台的硬件特性深度适配,通过合理的网络结构设计、标准化的预处理流程及优化的底层函数调用,在保证识别精度的前提下,实现了推理速度与资源占用的最优平衡,为嵌入式场景下的图像识别应用提供了高效、可靠的解决方案。
重难点和创新点
在算法设计和优化方面,本系统有以下创新点:
-
改进的卷积神经网络模型:针对数码字符识别的特点,设计了一个轻量级的卷积神经网络模型,在保持高识别准确率的同时,大幅减少了计算量和参数数量。
- 增加卷积层数量,减少全连接层数量,充分利用卷积操作的权值共享特性,减少参数数量
- 引入Dropout层,提高模型的泛化能力,防止过拟合
- 使用较小的卷积核(3×3),在保持感受野的同时减少计算量
-
嵌入式平台的神经网络优化:针对资源受限的嵌入式平台,提出了一系列优化策略,实现了卷积神经网络的高效运行。
- 使用CMSIS-NN库,充分利用ARM Cortex-M系列处理器的特性
- 定点化处理,将浮点运算转换为定点运算
- 内存优化,采用内存复用、数据压缩等技术
- 算法层面的优化,如计算复用、查表法等
-
多算法融合策略:结合穿线识别法和卷积神经网络的优点,提出了一种多算法融合的字符识别策略。
- 使用穿线识别法进行初步的字符完整性检查,快速筛选出明显不合格的字符
- 对疑似正常的字符,使用卷积神经网络进行精确识别
- 通过双算法验证,提高识别结果的可靠性
总结
本课题成功设计并实现了一套基于机器视觉的数码字符检测系统,该系统融合图像处理、深度学习等多个领域的技术,实现了数码管字符的自动识别和筛选功能。系统对比了四种不同的字符识别算法:基于几何特征的穿线识别法、模板匹配算法、三层全连接神经网络和卷积神经网络。 为了在资源受限的嵌入式平台上高效运行卷积神经网络,系统采用了一系列优化技术,包括定点化处理、CMSIS-NN库优化、内存优化和算法优化等。
当然,本系统还有一些需要改进和完善的地方。例如,目前系统只能识别数字字符,未来可以扩展到更多类型的字符识别;系统的鲁棒性还可以进一步提高,以适应更复杂的工业环境;可以考虑引入更多的智能算法,如迁移学习、联邦学习等,进一步提高系统的性能和适应性。
参考文献
[1] Chen Y, Jiang H, Li C, et al. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks[J]. IEEE Transactions on Geoscience & Remote Sensing, 2020, 58(1): 623-634.
[2] Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023.
[3] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 2021, 109(5): 786-815.
[4] Lai L, Suda N, Chandra V, et al. CMSIS-NN: efficient neural network kernels for ARM Cortex-M CPUs[J]. arXiv: Neural and Evolutionary Computing, 2020.
[5] He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 42(1): 185-197.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









