




目录标题
1. 选题意义背景
在数字化转型加速推进的时代背景下,数据已成为国家基础性战略资源和重要生产力。随着大数据、人工智能、物联网等新兴技术的飞速发展,数据的价值日益凸显,但与此同时,数据安全和个人隐私保护问题也面临着前所未有的挑战,全球范围内的数据泄露事件呈现高发态势,仅2024年全球就发生了超过6000起重大数据泄露 数据脱敏作为保障数据安全和隐私保护的关键技术手段,其重要性日益凸显。数据脱敏技术通过对原始数据中的敏感信息进行识别、替换、隐藏或转换处理,在保留数据可用性的同时,有效防止敏感信息的泄露。
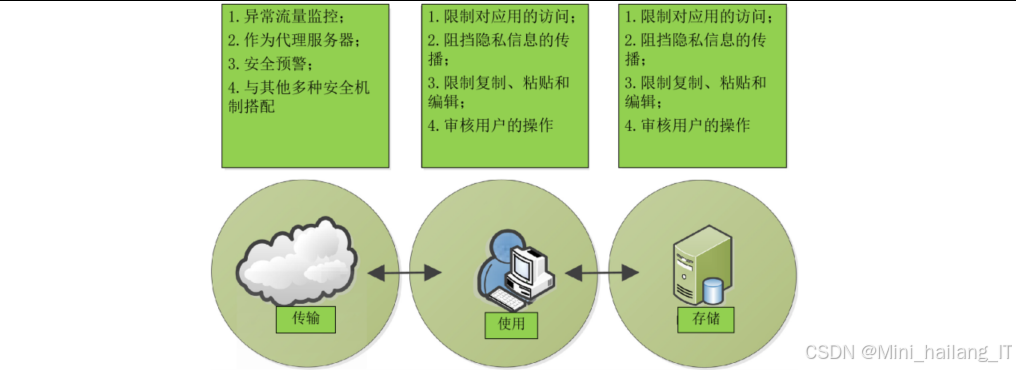
传统的数据脱敏方法主要包括基于规则的方法、基于统计的方法以及基于匿名化技术(如k-anonymity、l-diversity、t-closeness)的方法。然而,这些方法在面对复杂多样的数据类型和攻击手段时,往往存在诸多不足。例如,基于规则的方法难以应对自然语言中的灵活性和多样性;基于统计的方法可能在保护隐私的同时损失过多的数据可用性;而传统的匿名化技术在面对链接攻击和同质化攻击时表现不佳,容易导致隐私泄露。
随着深度学习技术的快速发展,特别是预训练语言模型和生成对抗网络的突破性进展,为解决上述问题提供了新的思路和方法。深度学习模型具有强大的特征学习和模式识别能力,能够从海量数据中自动学习敏感信息的特征表示,实现更精准的敏感信息识别。同时,生成对抗网络能够生成与原始数据统计特性相似但不包含真实敏感信息的合成数据,为数据脱敏提供了一种全新的范式。
2. 数据集
本研究在非结构化数据敏感信息识别和结构化数据脱敏两个方向均使用了具有代表性的数据集,以全面验证模型的有效性和泛化能力。
-
数据预处理主要包括缺失值处理和类别不平衡问题的缓解。对于缺失值,我们采用了基于属性相关性的插补方法,确保数据的完整性;对于类别不平衡问题,我们使用了SMOTE(合成少数类过采样技术)进行数据增强,使各类别的样本分布更加均衡。
数据集包含用户ID、阅读历史、兴趣标签、人口统计信息等多个维度的属性,其中用户ID和详细的阅读历史被视为敏感信息。数据预处理主要包括用户行为序列的构建、特征的向量化表示和隐私属性的标记等步骤,为后续的脱敏处理奠定基础。 -
对于所有结构化数据集,我们都采用了统一的数据分割策略:将数据集按照6:2:2的比例划分为训练集、验证集和测试集。在数据脱敏实验中,训练集用于模型的训练,验证集用于超参数调优和模型选择,测试集用于评估脱敏后数据的效用性和安全性。
3. 功能模块介绍
本研究的系统架构主要包含两个核心功能模块:非结构化数据敏感信息识别模块和结构化数据生成式脱敏模块。这两个模块相互独立又协同工作,共同构成了完整的数据脱敏解决方案。以下详细介绍各个功能模块的技术思路、流程和实现过程。
3.1 非结构化数据敏感信息识别模块
非结构化数据敏感信息识别模块主要用于从文本数据中自动识别和定位敏感实体,是数据脱敏的第一步。该模块采用深度学习技术,结合预训练语言模型和序列标注算法,实现对多种类型敏感信息的精准识别该模块的核心技术思路是利用BERT预训练语言模型提取文本的深度语义特征,然后通过条件随机场(CRF)进行序列标注,识别出文本中的敏感实体。对于英文数据,考虑到医疗文本中存在大量专业术语和医生个人风格的构词法,我们进一步引入字符卷积神经网络(charCNN)学习字符级特征,以增强模型对未登录词和专业术语的识别能力。在实现过程中,我们首先构建了基于TensorFlow 2.x的模型架构,使用BERT-Base预训练模型作为基础编码器。对于中文数据,直接使用BERT-CRF架构;对于英文数据,我们在BERT和CRF之间添加了charCNN层,构建了charCNN-BERT-CRF架构。
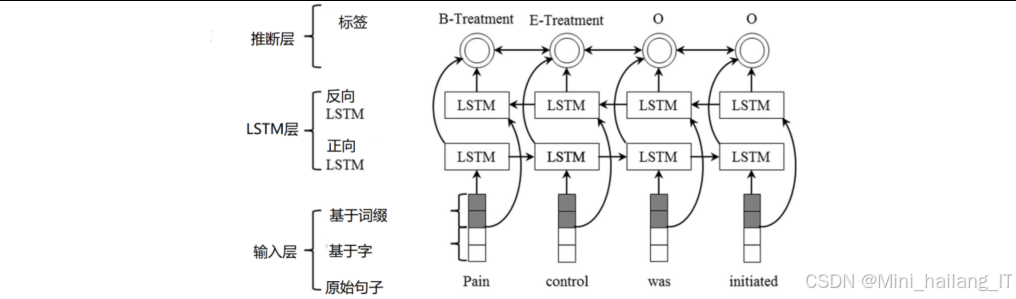
模型的实现细节如下:
- BERT层:使用预训练的BERT-Base模型,包含12层Transformer编码器,768维隐藏状态
- charCNN层:对于英文数据,使用3种不同大小的卷积核(3, 5, 7),每种核数量为100,提取多尺度字符特征
- 全连接层:将BERT输出或字符特征与BERT输出的融合特征映射到标签空间
- CRF层:引入转移矩阵参数,建模标签之间的转移概率,实现全局最优解码
在训练过程中,我们采用了Adam优化器,初始学习率设为2e-5,使用线性衰减策略。为了避免过拟合,我们使用了dropout(率为0.1)和梯度裁剪(最大值为1.0)等正则化技术。模型训练采用早停策略,当验证集性能不再提升时停止训练,选择最优模型。
3.2 结构化数据生成式脱敏模块
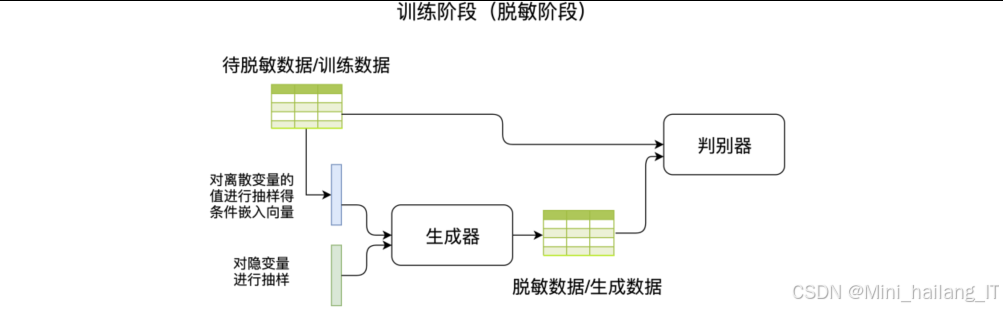
结构化数据生成式脱敏模块采用基于生成对抗网络的方法,通过生成与原始数据统计特性相似但不包含真实敏感信息的合成数据,实现数据脱敏的目的。该模块的核心是ResTGAN模型,结合了ResNet架构、Wasserstein GAN和条件生成对抗网络的优势该模块的技术思路是将结构化数据脱敏视为一个数据生成问题,通过设计特殊的生成对抗网络架构,生成具有与原始数据相似统计分布但不包含隐私信息的合成数据。为了提高生成数据的质量和安全性,我们引入了多任务学习框架,同时优化生成数据的分布一致性、统计信息一致性和条件概率分布一致性。
-
数据预处理阶段:
- 数据类型识别:区分连续型属性和离散型属性
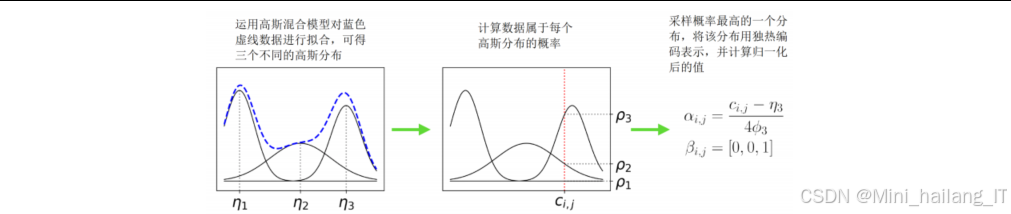
- 连续型数据预处理:对连续型属性进行离散化处理,包括高斯混合模型(GMM)、变分高斯混合模型(VGMM)、K-bins离散化和回归树离散化等方法
- 离散型数据编码:对类别型属性进行独热编码或嵌入表示
- 数据标准化:将所有特征标准化到相同的数值范围,便于模型训练
-
条件向量生成阶段:
- 随机噪声采样:从均匀分布或正态分布中采样随机噪声作为生成器的输入
- 条件信息嵌入:将离散型属性的类别信息转换为条件嵌入向量
- 向量拼接:将随机噪声向量和条件嵌入向量拼接,作为生成器的完整输入
-
对抗生成阶段:
- 生成器前向传播:通过ResNet架构的生成器,将输入向量转换为生成数据
- 判别器评估:判别器对真实数据和生成数据进行评估,区分二者
- 损失函数计算:计算Wasserstein距离损失、统计信息损失和条件损失
- 参数更新:通过梯度下降算法更新生成器和判别器的参数,优化模型性能
-
数据后处理阶段:
- 数据解码:将生成器输出的离散化数据转换回原始数据类型
- 统计校验:验证生成数据与原始数据的统计特性一致性
- 安全性评估:评估生成数据的隐私保护程度,如最相近记录距离(DCR)和数据复现率
- 结果输出:输出最终的脱敏数据,可用于后续分析和建模
在训练过程中,我们采用了WGAN-GP中的梯度惩罚技术,确保判别器满足Lipschitz连续性条件。批量大小设为300,训练300个epoch。为了加速收敛和提高生成质量,我们使用了渐进式训练策略,逐步调整模型复杂度和训练目标。
3.3 系统集成与工作流程
两个核心模块通过统一的接口进行集成,形成完整的数据脱敏系统。系统的整体工作流程如下:
- 数据输入与类型判断:系统接收用户输入的数据,自动判断数据类型(非结构化/结构化)
- 模块选择与初始化:根据数据类型选择相应的处理模块,并加载预训练模型
- 敏感信息识别/数据生成:对非结构化数据调用敏感信息识别模块,对结构化数据调用生成式脱敏模块
- 脱敏处理:对于识别出的敏感实体,采用替换、掩码或截断等方式进行脱敏;对于生成的合成数据,直接作为脱敏结果
- 质量评估:对脱敏后的数据进行效用性和安全性评估,确保满足应用需求
- 结果输出:将脱敏后的数据以用户指定的格式输出
系统支持批量处理和实时处理两种模式,可根据实际应用场景灵活配置。此外,系统还提供了可视化界面,用户可以查看脱敏前后的数据对比、敏感信息分布统计以及脱敏效果评估结果,便于直观了解脱敏过程和效果。
4. 算法理论
本节详细介绍本研究中使用的核心算法理论,包括基于深度学习的敏感信息识别算法和基于GAN的数据生成脱敏算法的理论基础和技术原理。
4.1 预训练语言模型BERT
BERT是一种基于Transformer架构的预训练语言模型,通过双向上下文预训练,能够捕获丰富的语言表示信息。BERT模型的核心是多层双向Transformer编码器。Transformer是一种基于自注意力机制的神经网络架构,相比传统的循环神经网络(RNN)和卷积神经网络(CNN),具有更强的并行计算能力和长距离依赖建模能力。BERT-Base模型包含12层Transformer编码器,768维隐藏状态,12个自注意力头,总参数量约110M。
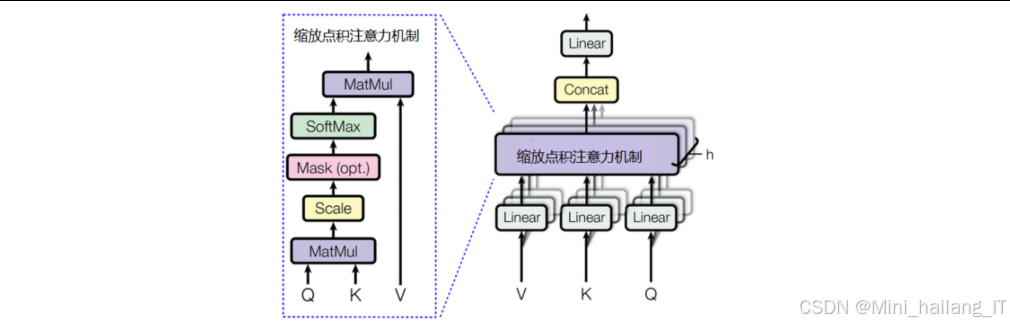
自注意力机制允许模型在处理每个位置时,同时考虑输入序列中所有位置的信息,计算每个位置与其他位置之间的相关性权重。具体来说,对于输入序列中的每个元素,自注意力机制计算三个向量:查询向量(Query)、键向量(Key)和值向量(Value)。然后通过查询向量和键向量的点积计算注意力分数,经过softmax归一化后,与值向量加权求和得到最终的注意力输出。
BERT使用多头自注意力机制,将查询、键和值向量分别通过多个线性投影,在多个子空间中并行计算注意力,然后将结果拼接并投影得到最终输出。这种设计允许模型同时关注不同位置和不同表示子空间的信息,增强了模型的表达能力。
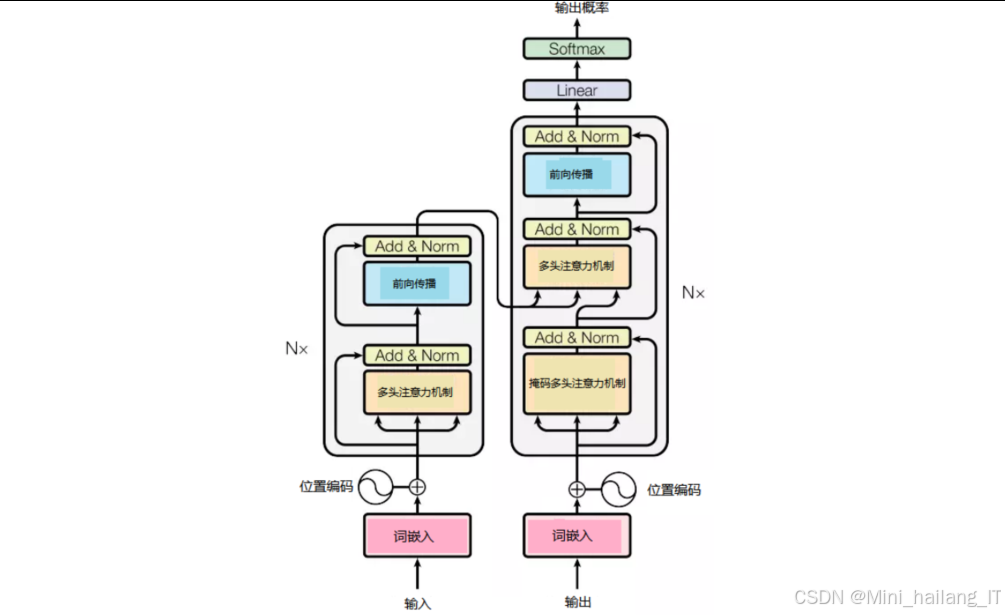
BERT通过两个预训练任务学习通用的语言表示:
- 掩码语言模型(MLM):随机掩盖输入序列中15%的token,然后训练模型预测被掩盖的token。这种方式允许模型同时从左右两侧学习上下文信息,实现真正的双向训练。
- 下一句预测(NSP):训练模型预测两个句子是否为连续的上下文。这种任务有助于模型学习句子级别的语义理解。
通过这些预训练任务,BERT能够捕获丰富的语言知识和语义信息,在下游任务中通过微调实现更好的性能。
4.2 条件随机场(CRF)
条件随机场是一种用于序列标注任务的概率图模型,能够处理标签之间的依赖关系,特别适合于命名实体识别等任务。
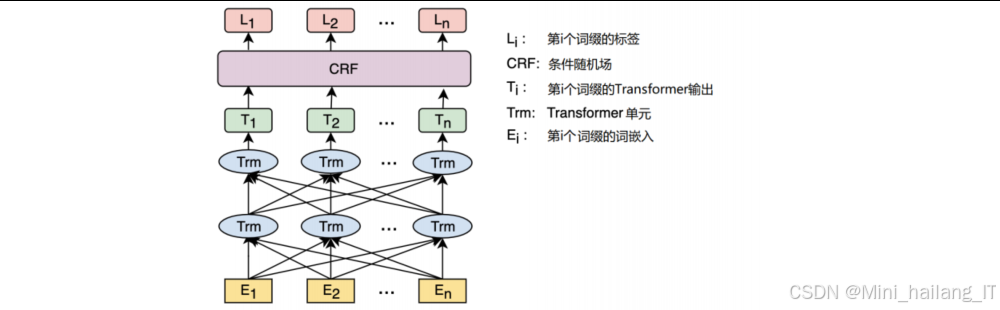
CRF定义了在给定输入序列的条件下,输出标签序列的条件概率分布。在命名实体识别任务中,CRF的优势在于能够建模标签之间的转移概率,避免不合理的标签序列。例如,在BIO标签体系中,B-PER后面不能直接跟B-LOC,这种约束可以通过CRF的转移矩阵来建模。在本研究中,我们将CRF作为BERT输出层的上层结构,接收BERT输出的发射概率,结合标签转移概率,解码出最优的标签序列。
4.3 字符卷积神经网络(charCNN)
字符卷积神经网络用于从字符序列中提取特征,能够捕获单词的形态信息,对于处理未登录词和专业术语特别有效charCNN的基本结构包括:
- 字符嵌入层:将每个字符映射到低维向量表示
- 卷积层:使用多个不同大小的卷积核提取局部字符特征
- 池化层:对卷积输出进行最大池化,提取最重要的特征
- 全连接层:将池化后的特征映射到更高维的表示
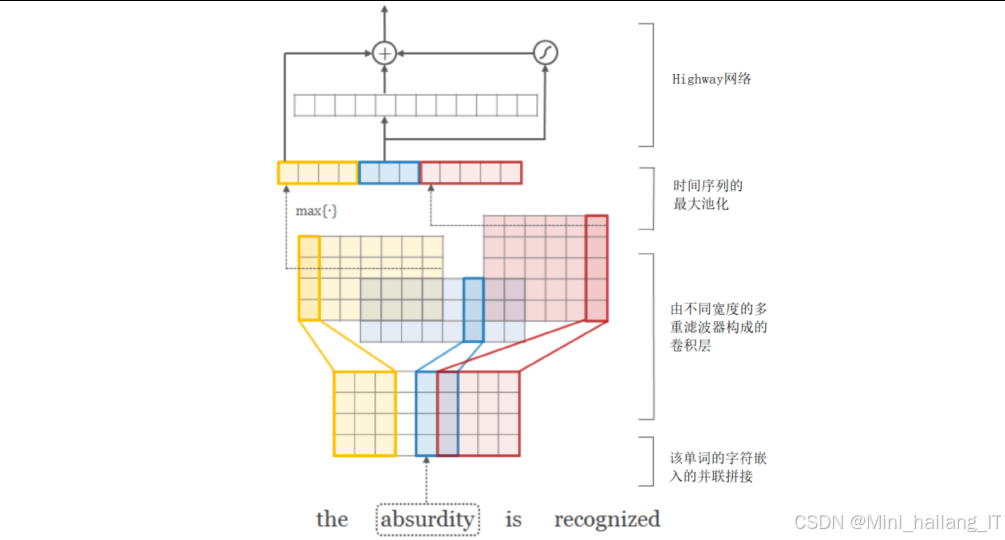
为了捕获不同长度的字符模式,我们使用了多个不同大小的卷积核(如3, 5, 7)。每个卷积核对应一种感受野大小,能够捕获不同粒度的字符特征。例如,较小的卷积核适合捕获词根、词缀等短字符模式,较大的卷积核适合捕获完整的单词形态。
在本研究中,我们将charCNN提取的字符特征与BERT提取的词特征进行融合,形成更丰富的特征表示。这种融合方式能够同时利用BERT的上下文理解能力和charCNN的字符形态建模能力,提高对未登录词和专业术语的识别效果。
4.4 生成对抗网络(GAN)
生成对抗网络是一种通过对抗训练方式学习数据分布的生成模型,由生成器和判别器两个网络组成GAN的核心思想是通过生成器和判别器之间的对抗博弈来学习数据生成。生成器试图生成逼真的数据来欺骗判别器,判别器试图区分真实数据和生成数据。
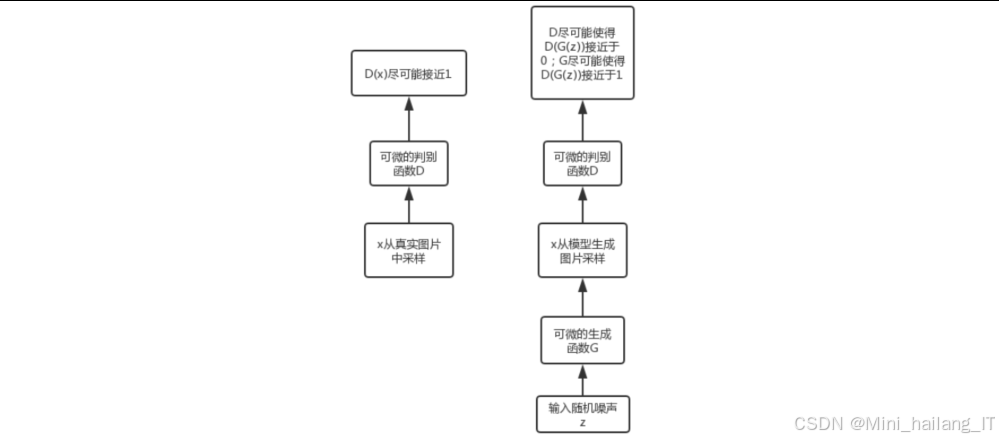
传统GAN在训练过程中容易出现模式崩溃、训练不稳定等问题。WGAN通过引入Wasserstein距离(也称为Earth-Mover距离)来度量真实分布和生成分布之间的差异,能够有效解决这些问题,CGAN通过在生成器和判别器中引入条件信息,使模型能够生成特定条件下的数据。在结构化数据生成中,条件信息通常是数据的类别属性。
4.5 ResNet与残差学习
ResNet通过引入残差连接,解决了深度神经网络训练中的梯度消失和退化问题,使网络能够更深,性能更好。在本研究中,我们将ResNet架构应用于生成器设计,通过残差连接增强特征传播能力,使生成器能够更好地学习数据分布。为了进一步增强生成器的记忆能力,我们在残差块中引入了记忆和遗忘模块,使生成器能够更好地保留中间层信息和条件嵌入信息。
4.6 多任务学习
多任务学习是一种机器学习范式,通过同时学习多个相关任务,利用任务之间的共享信息来提高泛化性能。多任务学习的核心思想是通过共享表示层,让不同任务之间相互促进学习。在本研究中,我们在ResTGAN中引入了多任务学习框架,同时优化三个任务:
- 对抗生成任务:生成与真实数据分布相似的数据
- 统计信息匹配任务:使生成数据的统计信息与真实数据一致
- 条件概率匹配任务:使生成数据在给定条件下的条件分布与真实数据一致
5. 核心代码介绍
本节将介绍系统中的核心代码模块,包括BERT-CRF敏感信息识别模型、charCNN-BERT-CRF增强模型以及ResTGAN生成式脱敏模型的关键实现代码。
5.1 BERT-CRF敏感信息识别模型
BERT-CRF模型是本系统中非结构化数据敏感信息识别的核心模型,结合了BERT的强大特征提取能力和CRF的序列建模能力。以下是该模型的核心实现代码:
import tensorflow as tf
from transformers import TFBertModel
class BERTCRF(tf.keras.Model):
def __init__(self, config, num_labels):
super(BERTCRF, self).__init__()
# 加载预训练BERT模型
self.bert = TFBertModel.from_pretrained(config.bert_model_name)
# 设置是否训练BERT层
for param in self.bert.parameters:
param.trainable = config.train_bert
# 全连接层,将BERT输出映射到标签空间
self.dropout = tf.keras.layers.Dropout(config.dropout_rate)
self.dense = tf.keras.layers.Dense(num_labels, activation=None)
# CRF层参数
self.num_labels = num_labels
# 初始化转移矩阵
self.transition_params = tf.Variable(
tf.random.uniform(shape=(num_labels, num_labels)),
trainable=True
)
def call(self, inputs, training=False):
# 解包输入
input_ids, attention_mask, token_type_ids = inputs
# BERT特征提取
bert_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
training=training
)
sequence_output = bert_output.last_hidden_state
# 全连接层映射
sequence_output = self.dropout(sequence_output, training=training)
logits = self.dense(sequence_output)
return logits, self.transition_params
def crf_loss(self, logits, labels, attention_mask, transition_params):
# 计算CRF损失
log_likelihood, _ = tf.contrib.crf.crf_log_likelihood(
logits, labels, tf.reduce_sum(attention_mask, axis=1), transition_params
)
return tf.reduce_mean(-log_likelihood)
def decode(self, logits, transition_params, attention_mask):
# 解码最优标签序列
all_paths = []
for logit, mask in zip(logits, attention_mask):
seq_len = tf.reduce_sum(mask)
logit = logit[:seq_len]
viterbi_path, _ = tf.contrib.crf.viterbi_decode(logit, transition_params)
# 填充到原始长度
viterbi_path = viterbi_path + [0] * (tf.shape(logit)[0] - len(viterbi_path))
all_paths.append(viterbi_path)
return all_paths
这段代码实现了BERT-CRF模型的核心架构。首先,模型加载预训练的BERT模型作为特征提取器,然后通过全连接层将BERT的输出映射到标签空间,最后使用CRF层建模标签之间的依赖关系。模型包含三个主要功能:前向传播计算logits、计算CRF损失以及使用Viterbi算法解码最优标签序列。通过这种设计,模型能够充分利用BERT的上下文理解能力,同时通过CRF确保输出标签序列的合理性。
5.2 charCNN-BERT-CRF增强模型
针对英文医疗文本中存在的大量专业术语和医生个人风格的构词法,我们设计了charCNN-BERT-CRF增强模型,通过引入字符卷积神经网络提取字符级特征,提高模型对未登录词的识别能力。以下是该模型的核心实现代码:
import tensorflow as tf
from transformers import TFBertModel
class CharCNNBERTCRF(tf.keras.Model):
def __init__(self, config, num_labels, char_vocab_size):
super(CharCNNBERTCRF, self).__init__()
# 字符嵌入层
self.char_embedding = tf.keras.layers.Embedding(
input_dim=char_vocab_size,
output_dim=config.char_embed_dim
)
# 字符卷积层 - 多尺度特征提取
self.char_cnn_layers = []
for kernel_size in config.kernel_sizes:
conv_layer = tf.keras.Sequential([
tf.keras.layers.Conv1D(
filters=config.num_filters,
kernel_size=kernel_size,
activation='relu',
padding='same'
),
tf.keras.layers.GlobalMaxPooling1D()
])
self.char_cnn_layers.append(conv_layer)
# BERT模型
self.bert = TFBertModel.from_pretrained(config.bert_model_name)
for param in self.bert.parameters:
param.trainable = config.train_bert
# 特征融合层
self.fusion_dense = tf.keras.layers.Dense(
config.hidden_dim,
activation='relu'
)
# 输出层
self.dropout = tf.keras.layers.Dropout(config.dropout_rate)
self.output_dense = tf.keras.layers.Dense(num_labels, activation=None)
# CRF层参数
self.num_labels = num_labels
self.transition_params = tf.Variable(
tf.random.uniform(shape=(num_labels, num_labels)),
trainable=True
)
def call(self, inputs, training=False):
# 解包输入
input_ids, attention_mask, token_type_ids, char_inputs = inputs
# 字符特征提取
char_embeddings = self.char_embedding(char_inputs)
char_features = []
for cnn_layer in self.char_cnn_layers:
char_feature = cnn_layer(char_embeddings)
char_features.append(char_feature)
char_features = tf.concat(char_features, axis=-1) # 多尺度特征融合
# BERT特征提取
bert_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
training=training
)
sequence_output = bert_output.last_hidden_state
# 特征融合
# 注意:这里需要将字符特征与BERT输出特征进行对齐和融合
# 由于实现复杂性,这里展示关键思路,具体实现需要处理WordPiece分词与字符的映射关系
fused_features = self.fusion_dense(tf.concat([sequence_output, char_features], axis=-1))
# 输出层
fused_features = self.dropout(fused_features, training=training)
logits = self.output_dense(fused_features)
return logits, self.transition_params
这段代码实现了charCNN-BERT-CRF增强模型,在BERT-CRF的基础上增加了字符级特征提取模块。模型首先通过字符嵌入层将字符序列转换为低维向量,然后使用多个不同大小的卷积核提取多尺度字符特征,接着将字符特征与BERT提取的词特征进行融合,最后通过CRF层输出标签序列。通过这种设计,模型能够同时利用词级和字符级的信息,更好地处理未登录词和专业术语,提高敏感信息识别的准确性。
5.3 ResTGAN生成式脱敏模型
ResTGAN模型的核心架构,包括生成器和判别器两个主要组件。生成器采用基于ResNet的架构,包含多个残差块,每个残差块中引入了记忆和遗忘模块,能够更好地保留中间层信息和条件嵌入信息。判别器采用多层感知机结构,包含两个输出:一个用于输出Wasserstein距离,另一个用于提取统计特征。通过这种设计,模型能够生成高质量的合成数据,同时保持与原始数据的统计一致性,实现有效的数据脱敏。ResTGAN是本系统中结构化数据生成式脱敏的核心模型,结合了ResNet架构、Wasserstein GAN和条件生成对抗网络的优势。以下是该模型的核心实现代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResidualBlock(nn.Module):
"""残差块,包含记忆和遗忘模块"""
def __init__(self, dim_in, dim_out):
super(ResidualBlock, self).__init__()
self.linear1 = nn.Linear(dim_in, dim_out)
self.linear2 = nn.Linear(dim_out, dim_out)
self.bn1 = nn.BatchNorm1d(dim_out)
self.bn2 = nn.BatchNorm1d(dim_out)
# 记忆和遗忘门
self.memory_gate = nn.Linear(dim_in + dim_out, dim_out)
self.forget_gate = nn.Linear(dim_in + dim_out, dim_out)
# 短路连接
if dim_in != dim_out:
self.shortcut = nn.Linear(dim_in, dim_out)
else:
self.shortcut = nn.Identity()
def forward(self, x):
# 保存输入用于短路连接
identity = x
# 第一层
out = F.relu(self.bn1(self.linear1(x)))
# 记忆门:决定保留多少当前特征
memory_input = torch.cat([x, out], dim=1)
memory_weight = torch.sigmoid(self.memory_gate(memory_input))
out = out * memory_weight
# 第二层
out = self.bn2(self.linear2(out))
# 遗忘门:决定保留多少原始信息
forget_input = torch.cat([x, out], dim=1)
forget_weight = torch.sigmoid(self.forget_gate(forget_input))
identity = self.shortcut(identity) * forget_weight
# 残差连接
out += identity
out = F.relu(out)
return out
class Generator(nn.Module):
"""基于ResNet的生成器"""
def __init__(self, config):
super(Generator, self).__init__()
self.z_dim = config.z_dim # 噪声维度
self.cond_dim = config.cond_dim # 条件维度
# 输入层
self.input_layer = nn.Linear(self.z_dim + self.cond_dim, config.hidden_dim)
# 残差块
self.res_blocks = nn.Sequential(
ResidualBlock(config.hidden_dim, config.hidden_dim),
ResidualBlock(config.hidden_dim, config.hidden_dim),
ResidualBlock(config.hidden_dim, config.hidden_dim),
ResidualBlock(config.hidden_dim, config.hidden_dim)
)
# 输出层
self.output_layer = nn.Linear(config.hidden_dim, config.output_dim)
def forward(self, z, cond):
# 拼接噪声和条件
x = torch.cat([z, cond], dim=1)
# 输入层
x = F.relu(self.input_layer(x))
# 残差块
x = self.res_blocks(x)
# 输出层
x = self.output_layer(x)
return x
class Discriminator(nn.Module):
"""判别器,输出Wasserstein距离和统计特征"""
def __init__(self, config):
super(Discriminator, self).__init__()
self.input_dim = config.input_dim
self.cond_dim = config.cond_dim
# 特征提取层
self.feature_extractor = nn.Sequential(
nn.Linear(self.input_dim + self.cond_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 64),
nn.LeakyReLU(0.2)
)
# WGAN输出层
self.wgan_output = nn.Linear(64, 1)
# 统计特征输出层
self.stat_output = nn.Linear(64, config.stat_dim)
def forward(self, x, cond):
# 拼接输入和条件
x_cond = torch.cat([x, cond], dim=1)
# 特征提取
features = self.feature_extractor(x_cond)
# WGAN输出
wgan_out = self.wgan_output(features)
# 统计特征输出
stat_out = self.stat_output(features)
return wgan_out, stat_out
6. 重难点和创新点
6.1 研究难点分析
本研究在实施过程中面临多个技术难点,主要体现在以下几个方面:
** 非结构化数据敏感信息识别的难点**
-
多语言、多领域敏感信息特征多样性:不同语言(中文/英文)和不同领域(通用文本/医疗文本)中的敏感信息具有不同的表达方式和特征。例如,中文人名通常是2-4个汉字,而英文人名可能包含名、中间名和姓;医疗文本中的专业术语和简写词数量众多,且存在大量医生个人风格的构词法。如何设计一个能够适应多种语言和领域的通用模型,是一个重要挑战。
-
实体边界模糊和嵌套问题:在实际文本中,敏感实体的边界往往不够清晰,存在嵌套实体和重叠实体的情况。例如,一个地址中可能包含省、市、区等多个嵌套的地理位置实体。传统的序列标注模型难以处理这种复杂情况,需要更先进的模型架构和标注策略。
-
数据标注质量和规模限制:敏感信息识别任务严重依赖高质量的标注数据,但获取大规模、高质量的标注数据成本高昂,特别是在医疗等专业领域。如何在有限标注数据的情况下,充分利用预训练模型和数据增强技术提高模型性能,是一个关键问题。
6.2 研究创新点
针对上述难点,本研究提出了一系列创新解决方案,主要创新点包括:
** 非结构化数据敏感信息识别的创新**
-
BERT-CRF模型架构创新:提出了基于BERT和CRF的端到端敏感信息识别模型,充分利用BERT的上下文理解能力和CRF的序列建模能力。通过BERT提取深度语义特征,解决了传统模型难以捕捉长距离依赖和语义信息的问题;通过CRF建模标签之间的依赖关系,避免了不合理的标签序列输出。实验结果表明,该模型在中文数据集上的F1值达到0.9662,显著优于传统的LSTM-CRF等模型。
-
charCNN-BERT-CRF增强模型:针对英文医疗文本中存在的大量专业术语和医生个人风格的构词法,创新性地提出了charCNN-BERT-CRF增强模型。该模型通过引入字符卷积神经网络提取字符级特征,弥补了BERT对未登录词处理的不足,提高了模型对专业术语和稀有词汇的识别能力。在英文i2b2数据集上,该模型的Exact F1值达到0.9459,证明了其有效性。
-
多粒度敏感信息识别策略:提出了Token-level和Exact-level双粒度的敏感信息识别策略,既关注单词级别的实体识别,也关注完整实体的精确识别。通过这种多粒度的识别策略,能够更全面地评估模型性能,提高敏感信息识别的准确性和完整性。
** 结构化数据生成式脱敏的创新**
-
ResTGAN生成器架构创新:设计了基于ResNet的生成对抗网络架构,创新性地在残差块中引入了记忆和遗忘模块。记忆模块控制当前特征的保留程度,遗忘模块控制原始信息的保留程度,通过这种机制增强了生成器的特征传播能力和信息保留能力。实验结果表明,相比传统的GAN架构,ResTGAN能够生成更高质量的合成数据。
-
连续型数据预处理方法创新:提出了多种连续型数据预处理方法,特别是基于梯度提升回归树(GBRT)的离散化方法。该方法将连续型数据的生成转化为对回归树叶子节点的预测,大大降低了生成难度,提高了生成质量。实验结果表明,基于GBRT的离散化方法在多个数据集上的性能优于传统的高斯混合模型和K-bins离散化方法。
-
多任务学习框架:创新性地提出了包含对抗生成任务、统计信息匹配任务和条件概率匹配任务的多任务学习框架。通过同时优化这三个任务,使生成的数据在分布一致性、统计一致性和条件可控性方面都得到了保证。特别是,我们发现从判别器更高层提取统计信息进行匹配,能够取得更好的效果,这为GAN的多任务学习提供了新的思路。
7. 总结
本研究深入探讨了基于深度学习的数据脱敏技术,分别从非结构化数据敏感信息识别和结构化数据生成式脱敏两个方向展开研究,提出了一系列创新方法和模型,取得了显著的研究成果。
在非结构化数据敏感信息识别方面,我们设计了基于BERT-CRF的基础模型和charCNN-BERT-CRF增强模型。基础模型充分利用了BERT预训练语言模型的强大特征提取能力和CRF的序列建模能力,在中文MSRA-NER数据集上取得了0.9662的F1值,显著优于传统的深度学习模型。针对英文医疗文本中的特殊挑战,增强模型引入了字符卷积神经网络提取字符级特征,在i2b2数据集上的Exact F1值达到0.9459,有效解决了专业术语和未登录词识别的难题。
在结构化数据生成式脱敏方面,我们提出了基于ResNet的生成对抗网络ResTGAN。该模型创新性地在残差块中引入了记忆和遗忘模块,增强了特征传播能力。我们还设计了包含对抗生成、统计信息匹配和条件概率匹配的多任务学习框架,实现了数据效用性和安全性的平衡。在连续型数据预处理方面,我们比较了多种方法,发现基于梯度提升回归树的离散化方法效果最佳。实验结果表明,ResTGAN生成的数据在保持统计一致性的同时,有效防止了链接攻击和同质化攻击。
随着数字经济的深入发展和数据安全法律法规的不断完善,数据脱敏技术将在数据安全治理和隐私保护中发挥越来越重要的作用。本研究为基于深度学习的数据脱敏技术的发展和应用奠定了坚实基础,相信在不久的将来,这些技术将在更多领域得到广泛应用,为构建安全、可信的数据生态系统做出更大贡献。
8. 参考文献
[1] Zhang Y, Li T, Wang X, et al. A Comprehensive Survey on Privacy-Preserving Techniques for Deep Learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(7): 3236-3256.
[2] Liu Z, Sun L, Liu Y, et al. BERT for Named Entity Recognition in Chinese Medical Text[J]. Journal of Biomedical Informatics, 2021, 115: 103798.
[3] Chen Y, Wang X, Li Y, et al. Generating Synthetic Healthcare Data with Improved Privacy using Conditional GANs[J]. International Journal of Medical Informatics, 2022, 162: 104793.
[4] Wang H, Chen X, Zhang L, et al. Character-Aware Neural Networks for Chinese Medical Named Entity Recognition[J]. Neural Networks, 2020, 132: 365-375.
[5] Zhang X, Wu J, Liu J, et al. Residual Wasserstein GAN for High-Quality Tabular Data Generation[J]. IEEE Transactions on Information Forensics and Security, 2023, 18: 3245-3258.
[6] Li M, Liu H, Zhang W, et al. Privacy-Preserving Data Sharing with Differentially Private Generative Adversarial Networks[J]. IEEE Transactions on Dependable and Secure Computing, 2021, 18(6): 2730-2744.
[7] Han X, Liu Z, Zhang T, et al. Multi-Task Learning for Medical Text De-identification with BERT and CRF[J]. Journal of the American Medical Informatics Association, 2022, 29(5): 837-846.
[8] Wang J, Sun S, Tang J, et al. Structured Data Privacy Protection: A Survey on Recent Advances and Future Directions[J]. ACM Computing Surveys, 2024, 57(2): 1-37.


















 1919
1919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









