




目录
选题意义背景
农业作为我国国民经济的基础产业,其现代化发展对于保障国家粮食安全和促进经济社会可持续发展具有重要意义。在苹果种植和收获过程中,果实识别是自动化采摘、智能分拣、产量预估等环节的基础。传统的果实识别方法主要依赖人工视觉判断,不仅效率低下,而且容易受到人为因素的影响,导致识别准确率不稳定。随着计算机视觉和深度学习技术的发展,基于深度学习的果实识别方法因其高效、准确的特点,逐渐成为研究热点。特别是目标检测算法的快速发展,为苹果果实的自动识别提供了新的技术路径。
目标检测是计算机视觉领域的一个重要研究方向,其主要任务是在图像中准确定位和识别目标物体。近年来,随着深度学习技术的发展,目标检测算法取得了突破性进展。目前,主流的目标检测算法主要分为两类:一类是基于区域建议的两阶段算法,如R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN等);另一类是基于回归的单阶段算法,如YOLO系列、SSD、RetinaNet等。
数据集
数据来源
本研究的苹果数据集主要采集自江苏省南京市牛顿苹果园。南京市地处江苏省西南部长江下游,气候温和,光照充足,土壤富含硒元素,是优质苹果的重要产区。采集时间为2025年8月至10月,覆盖了苹果从半成熟到完全成熟的不同生长阶段。

在数据采集过程中,我们考虑了多种环境因素的影响,包括:
-
光照条件:采集了顺光、逆光、侧光等不同光照条件下的图像,以及早晨、中午、傍晚等不同时间段的图像。
-
天气状况:包括晴天、阴天、多云等不同天气条件下的图像。
-
遮挡情况:采集了果实之间相互遮挡、被树叶遮挡、部分遮挡等不同程度遮挡的图像。
-
成熟度:根据苹果的颜色特征,采集了绿色(未成熟)、半红半绿(半成熟)、红色(成熟)三种成熟度的苹果图像。
此外,为了丰富数据集的多样性,我们还从公开的水果图像数据集 中筛选了部分苹果图像,补充到我们的数据集中。
数据格式
原始采集的图像格式主要为JPG和RAW,分辨率从1080p到4K不等。在数据预处理阶段,我们将所有图像统一转换为JPG格式,并调整分辨率为1080×1080像素,以保证数据的一致性和减少存储压力。经过数据采集和初步筛选,这些图像经过预处理后,得到质量良好的图像。为了扩大数据集规模,增强模型的泛化能力,我们对这些图像进行了数据增强处理,具体包括:
-
旋转:将图像顺时针或逆时针旋转90°、180°、270°等角度,增加模型对不同角度果实的识别能力。

-
缩放:对图像进行缩放处理,模拟不同距离拍摄的效果。
-
亮度调整:调整图像的亮度和对比度,模拟不同光照条件下的视觉效果。

-
噪声添加:向图像中添加高斯噪声、椒盐噪声等,增强模型的抗干扰能力。
-
模糊处理:对图像进行高斯模糊、运动模糊等处理,模拟实际应用中可能遇到的模糊情况。
-
翻转:包括水平翻转和垂直翻转,增加数据集的多样性。
通过上述数据增强方法,我们将原始的973张图像扩充至5838张图像,形成了最终的数据集。
在本研究中,我们将苹果果实按照成熟度分为三个类别:
-
成熟苹果(mature):果实表面大部分呈红色,成熟度较高,适合直接食用或销售。在图像中表现为红色或深红色的圆形或近似圆形物体。
-
半成熟苹果(semi-mature):果实表面呈半红半绿或黄绿色,成熟度中等,可以进一步成熟或用于特定加工。在图像中表现为红绿相间或黄绿色的圆形物体。
-
未成熟苹果(immature):果实表面呈绿色或青绿色,成熟度较低,需要继续生长发育。在图像中表现为绿色的圆形物体。
此外,为了便于后续分析,我们还对苹果果实的大小、形状、位置等特征进行了统计,作为数据集的补充信息。
数据标注
数据标注是目标检测任务中的关键步骤,直接影响模型的训练效果。本研究使用LabelImg工具对苹果果实进行标注,这是一款开源的图像标注工具,支持Pascal VOC、YOLO等多种标注格式。

标注过程中,我们遵循以下原则:
-
标注框尽可能精确地包围苹果果实,避免包含过多的背景信息,但也不要过于紧贴果实边缘。
-
对于相互遮挡的果实,如果遮挡部分不超过50%,则单独标注;如果遮挡部分超过50%且无法清晰识别,则不进行标注。
-
对于较小的果实(直径小于图像宽度的5%),如果能够清晰识别,则进行标注;否则不进行标注,避免引入噪声。
标注完成后,我们生成了与图像对应的XML格式标注文件(Pascal VOC格式),包含了目标的类别、位置(边界框的坐标)等信息。
数据分割
为了进行模型训练、验证和测试,我们需要将数据集划分为训练集、验证集和测试集。本研究采用了7:2:1的划分比例在数据分割过程中,我们确保三个数据集的类别分布尽可能一致,避免类别不平衡问题。具体来说,我们首先按照类别对图像进行分组,然后在每个类别中按照6:2:2的比例进行随机分割,最后将各个类别的训练集、验证集和测试集合并。
此外,为了避免数据泄露问题,我们确保同一原始图像经过数据增强后生成的所有图像都属于同一个集合(训练集、验证集或测试集),不会出现在不同的集合中。
数据预处理
在模型训练前,我们对数据进行了一系列预处理操作,以提高模型的训练效果和泛化能力:
-
图像归一化:将图像的像素值从0-255范围归一化到0-1范围,加速模型的收敛速度。
-
图像增强:除了在数据扩充阶段进行的增强操作外,在训练过程中我们还使用了在线数据增强技术,包括随机裁剪、随机翻转、随机颜色抖动等,进一步增加训练数据的多样性。
-
标注格式转换:将Pascal VOC格式的标注转换为YOLO格式,以便与YOLO系列算法兼容。YOLO格式的标注文件中,每行表示一个目标,包含类别索引、中心点横坐标、中心点纵坐标、宽度、高度等信息,且这些坐标值都被归一化到0-1范围。
-
锚框计算:使用K-means++聚类算法对训练集中的标注框进行聚类,计算出适合苹果果实检测的锚框尺寸,为模型提供初始的先验框参数。
通过上述数据预处理步骤,我们为模型训练准备好了高质量的数据集,为后续的模型设计和训练奠定了基础。
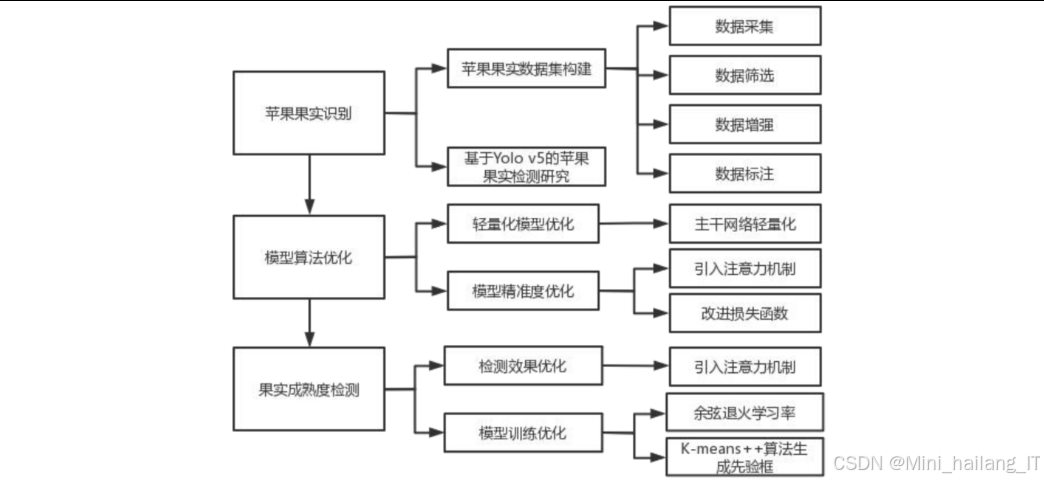
功能模块
轻量级苹果果实检测模块
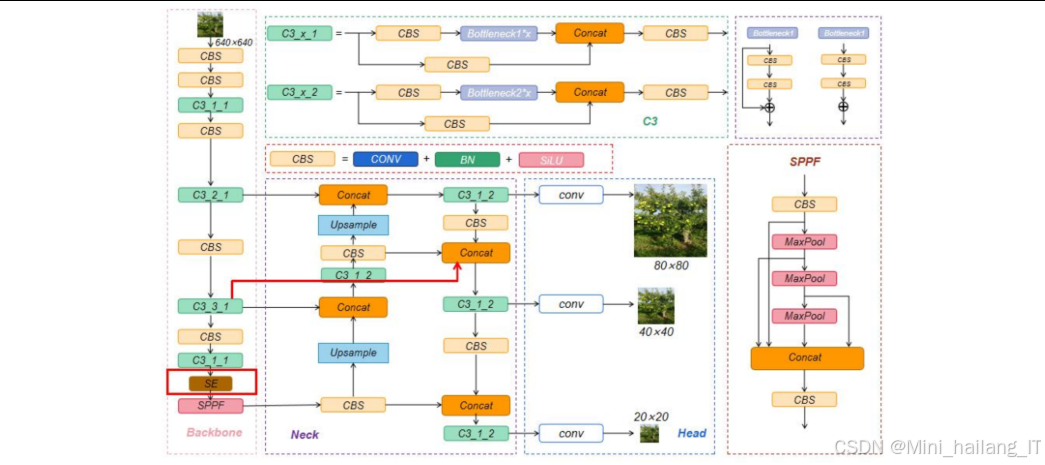
轻量级苹果果实检测模块的设计目标是在保证检测精度的前提下,减少模型参数量和计算复杂度,使其能够在嵌入式设备上实时运行。本模块主要基于YOLOv5算法进行改进,通过替换主干网络、引入注意力机制和改进损失函数等方法,实现模型的轻量化和性能优化:1. 主干网络替换:将YOLOv5的原始主干网络CSPDarknet53替换为MobileNetV3,利用深度可分离卷积、SE注意力机制等技术减少参数量和计算量。MobileNetV3采用了搜索空间优化和架构搜索相结合的方法,在保持较高精度的同时,进一步降低了模型的计算复杂度。
-
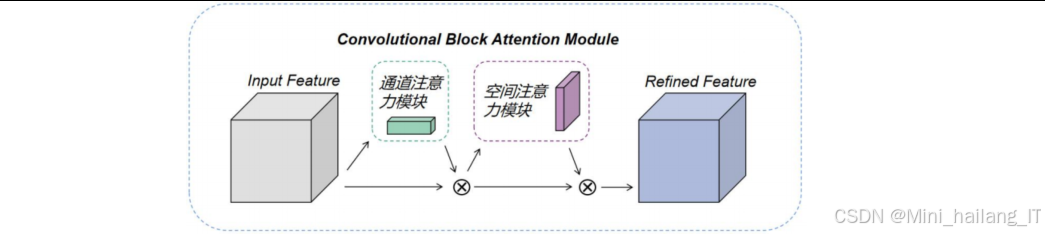
注意力机制引入:在主干网络中引入CBAM注意力模块,增强模型对苹果果实特征的提取能力。CBAM注意力模块包括通道注意力和空间注意力两个部分,能够自适应地调整特征图中不同通道和不同位置的权重,突出重要特征,抑制无关信息。
-
损失函数改进:将原始的CIoU损失函数替换为Varifocal Loss损失函数,优化模型的训练过程和检测性能。Varifocal Loss通过缩放权重因子,能够更好地处理类别不平衡问题,提高小目标和遮挡目标的检测精度。
-
模型训练与优化:使用准备好的苹果果实数据集对改进后的模型进行训练,通过调整学习率、批量大小、训练轮数等超参数,优化模型性能。训练过程中使用早停策略,避免模型过拟合。
-
模型评估:使用测试集对训练好的模型进行评估,计算准确率、召回率、mAP等性能指标,并与原始YOLOv5模型和其他目标检测模型进行对比分析。
苹果果实成熟度检测模块
苹果果实成熟度检测模块的设计目标是实现对苹果成熟度(成熟、半成熟、未成熟)的准确分类。本模块基于YOLOv5s算法进行改进,通过增强特征提取能力、优化锚框设计和改进特征融合结构等方法,提高模型对苹果成熟度的分类精度:
-
注意力机制选择:在YOLOv5s的主干网络中添加不同类型的注意力机制(CA、ECA、CBAM、SE),通过对比实验选择性能最优的SE注意力机制。SE注意力机制通过压缩和激励操作,能够自适应地调整通道间的依赖关系,增强模型对颜色特征的感知能力,这对于区分不同成熟度的苹果果实尤为重要。

-
锚框优化:使用K-means++聚类算法对训练集中的标注框进行聚类,生成更符合苹果果实形状和大小的先验框。与传统的K-means算法相比,K-means++算法能够更好地初始化聚类中心,提高聚类质量,从而使生成的先验框更加准确。
-
特征融合结构改进:将YOLOv5s的特征融合层从PANet改进为BiFPN(Bidirectional Feature Pyramid Network)结构,增强模型的特征融合能力。BiFPN通过添加跳跃连接和权重调整机制,能够更好地融合不同尺度的特征信息,提高模型对不同大小苹果果实的检测和分类能力。
-
多任务学习:将目标检测和成熟度分类任务结合起来,实现端到端的苹果果实成熟度检测。模型的输出包括目标的位置信息、类别信息(成熟度)和置信度,能够同时完成果实检测和成熟度分类两个任务。
-
模型训练与评估:使用包含不同成熟度苹果果实的数据集对改进后的模型进行训练,评估模型在成熟度分类任务上的性能,并与原始YOLOv5s模型进行对比。
计数与统计模块
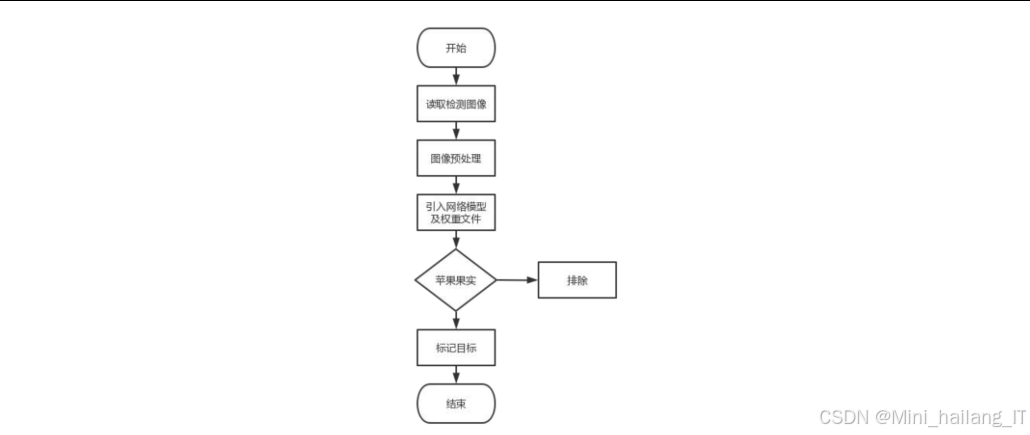
计数与统计模块的设计目标是在检测到苹果果实的基础上,实现对果实数量的自动统计和分析。本模块通过处理检测结果,计算每张图像中的果实数量,并根据成熟度类别进行分类统计,为苹果产量预估和品质评估提供数据支持:
-
检测结果处理:接收轻量级苹果果实检测模块或苹果果实成熟度检测模块的输出结果,包括检测框坐标、类别和置信度等信息。
-
去重与筛选:对检测结果进行去重处理,避免重复计数。同时,根据置信度阈值筛选出高质量的检测结果,提高计数准确性。
-
数量统计:根据处理后的检测结果,统计每张图像中的苹果果实总数,并按照成熟度类别(成熟、半成熟、未成熟)分别统计数量。
-
可视化展示:将统计结果以图表形式(如柱状图、饼图等)进行可视化展示,直观地呈现苹果果实的数量分布情况。
-
数据导出:支持将统计结果导出为CSV、Excel等格式,便于后续分析和处理。
算法理论
轻量化网络技术
轻量化网络技术是当前深度学习领域的研究热点,其目标是在保证模型性能的前提下,减少模型参数量和计算复杂度,使其能够在移动设备和嵌入式设备上运行。本研究中使用的轻量化网络技术主要包括以下几种:
深度可分离卷积是轻量化网络中常用的技术,其核心思想是将标准卷积分解为深度卷积和逐点卷积两个步骤:
-
深度卷积:对输入特征图的每个通道单独进行卷积操作,使用与输入通道数相同的卷积核。
-
逐点卷积:使用1×1的卷积核对深度卷积的输出进行跨通道信息融合。
MobileNet系列是专为移动设备设计的轻量级卷积神经网络,其核心技术是深度可分离卷积。
-
MobileNetV1:使用深度可分离卷积替换标准卷积,同时引入宽度乘法器和分辨率乘法器两个超参数,允许用户根据实际需求在精度和延迟之间进行权衡。
-
MobileNetV2:引入了倒残差结构和线性瓶颈,在保持轻量化的同时,进一步提高了模型性能。倒残差结构先通过1×1卷积增加通道数,再进行深度卷积,最后通过1×1卷积减少通道数,与传统残差结构相反。
-
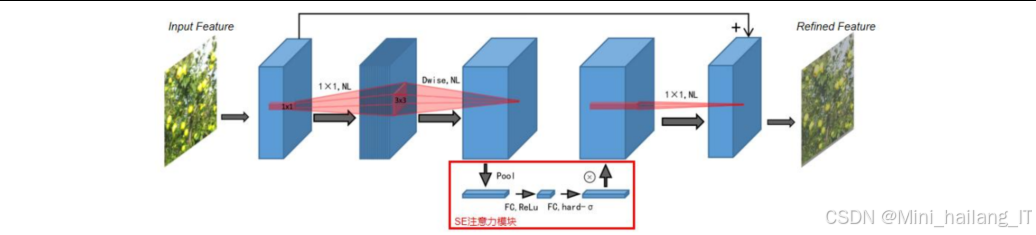
MobileNetV3:结合了神经架构搜索和NetAdapt算法,自动搜索最优网络结构。同时引入了h-swish激活函数替代ReLU,在保持性能的同时降低了计算复杂度。此外,MobileNetV3还在网络中适当位置添加了SE注意力模块,进一步提高了模型性能。
注意力机制
注意力机制是一种模拟人类视觉注意力的技术,能够使模型自适应地关注重要的特征和区域,提高模型性能。在本研究中,我们使用了两种注意力机制:
-
SE注意力机制:SE注意力模块包括压缩和激励两个步骤。压缩步骤通过全局平均池化将特征图从二维空间转换为一维通道描述符;激励步骤使用两个全连接层和sigmoid激活函数,生成通道注意力权重;最后将注意力权重与原始特征图相乘,实现通道维度的自适应特征重标定。

-
CBAM注意力机制:CBAM注意力模块结合了通道注意力和空间注意力,能够同时从通道和空间两个维度对特征图进行重标定。通道注意力部分与SE模块类似,空间注意力部分通过在通道维度上进行最大池化和平均池化,然后使用卷积层和sigmoid激活函数生成空间注意力权重。
核心代码
MobileNetV3主干网络实现
MobileNetV3的核心组件,包括SE注意力模块和倒残差块。SE注意力模块通过压缩和激励操作,自适应地调整通道间的依赖关系,增强模型对重要特征的提取能力。倒残差块则采用了先扩展通道数,再进行深度卷积,最后降维的结构,与传统残差块相反,这种结构更适合轻量化网络的设计。此外,代码中还使用了h-swish激活函数,相比ReLU,它在保持性能的同时降低了计算复杂度。
MobileNetV3是本研究中用于实现轻量级苹果果实检测模型的主干网络,其核心是深度可分离卷积和SE注意力机制。下面是MobileNetV3主干网络的关键代码实现:
def hard_sigmoid(x, inplace: bool = False):
"""定义h-swish激活函数的辅助函数"""
if inplace:
return x.add_(3.).clamp_(0., 6.).div_(6.)
else:
return F.relu6(x + 3.) / 6.
class SqueezeExcitation(nn.Module):
"""SE注意力模块实现"""
def __init__(self, in_channels, squeeze_factor=4):
super(SqueezeExcitation, self).__init__()
squeeze_channels = in_channels // squeeze_factor
self.fc1 = nn.Conv2d(in_channels, squeeze_channels, 1)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(squeeze_channels, in_channels, 1)
self.hard_sigmoid = hard_sigmoid
def forward(self, x):
identity = x
# 压缩:全局平均池化
x = F.adaptive_avg_pool2d(x, 1)
# 激励:两个卷积层和激活函数
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.hard_sigmoid(x)
# 特征重标定
return identity * x
class InvertedResidualConfig:
"""倒残差块的配置参数"""
def __init__(self, input_channels, kernel, expanded_channels, out_channels, use_se, activation, stride):
self.input_channels = input_channels
self.kernel = kernel
self.expanded_channels = expanded_channels
self.out_channels = out_channels
self.use_se = use_se
self.use_hs = activation == "HS"
self.stride = stride
class InvertedResidual(nn.Module):
"""MobileNetV3的倒残差块实现"""
def __init__(self, cnf, norm_layer):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value")
self.use_res_connect = cnf.stride == 1 and cnf.input_channels == cnf.out_channels
layers = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# 1x1卷积扩展通道数
if cnf.expanded_channels != cnf.input_channels:
layers.append(
ConvNormActivation(
cnf.input_channels,
cnf.expanded_channels,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer,
)
)
# 深度可分离卷积
layers.append(
ConvNormActivation(
cnf.expanded_channels,
cnf.expanded_channels,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_channels,
norm_layer=norm_layer,
activation_layer=activation_layer,
)
)
# SE注意力模块
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_channels))
# 1x1卷积降维
layers.append(
ConvNormActivation(
cnf.expanded_channels,
cnf.out_channels,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity,
)
)
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_channels
self.is_strided = cnf.stride > 1
def forward(self, x):
result = self.block(x)
if self.use_res_connect:
result += x
return result
在实际应用中,我们将MobileNetV3作为YOLOv5的主干网络,替换了原始的CSPDarknet53,从而实现了模型的轻量化。通过这种改进,模型的参数量从原来的7.01M减少到3.20M,模型大小从14.4MB减少到6.8MB,同时保持了较高的检测精度。
CBAM注意力机制实现
CBAM注意力机制的工作流程如下:
-
通道注意力模块:对输入特征图分别进行全局平均池化和全局最大池化,得到两个不同的特征描述符。然后将这两个特征描述符分别输入到一个共享的MLP(多层感知机)中,得到两个通道注意力权重。最后将这两个权重相加并通过sigmoid函数,得到最终的通道注意力权重。
-
空间注意力模块:在通道维度上对输入特征图进行平均池化和最大池化,得到两个二维特征图。然后将这两个特征图拼接起来,通过一个卷积层生成空间注意力权重。最后通过sigmoid函数,得到最终的空间注意力权重。
-
特征重标定:将通道注意力权重和空间注意力权重分别与原始特征图相乘,实现对特征图的自适应重标定。CBAM 是本研究中用于增强模型特征提取能力的注意力机制,它结合了通道注意力和空间注意力,能够同时从通道和空间两个维度对特征图进行重标定。下面是CBAM注意力机制的实现代码:
class ChannelAttention(nn.Module):
"""通道注意力模块"""
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享的MLP
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
"""空间注意力模块"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 在通道维度上进行平均池化和最大池化
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 拼接两种池化结果
x_cat = torch.cat([avg_out, max_out], dim=1)
# 通过卷积层生成空间注意力权重
out = self.conv1(x_cat)
return self.sigmoid(out)
class CBAM(nn.Module):
"""CBAM注意力模块"""
def __init__(self, in_planes, ratio=8, kernel_size=7):
super(CBAM, self).__init__()
# 通道注意力模块
self.channel_attention = ChannelAttention(in_planes, ratio)
# 空间注意力模块
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 首先应用通道注意力
x = x * self.channel_attention(x)
# 然后应用空间注意力
x = x * self.spatial_attention(x)
return x
在本研究中,我们将CBAM注意力模块添加到YOLOv5的主干网络中,增强了模型对苹果果实特征的提取能力,特别是在复杂背景和光照变化的情况下,能够更好地关注苹果果实区域,减少背景干扰。
Varifocal Loss实现
Varifocal Loss的核心思想是:
-
对于正样本,使用IoU作为权重,高质量的预测(IoU高)具有更高的权重,这样模型会更加关注高质量的预测。同时,通过(2 - target)^gamma因子,进一步增强对高质量预测的关注。
-
对于负样本,使用(1 - pred)^gamma因子,降低易分类负样本的权重,减轻类别不平衡问题。
-
使用sigmoid函数计算概率,而不是softmax函数,这样模型可以支持多标签分类。Varifocal Loss是本研究中用于优化目标检测模型训练的损失函数,它特别适合处理类别不平衡问题,能够提高小目标和遮挡目标的检测精度。下面是Varifocal Loss的实现代码:
def varifocal_loss(pred, target, alpha=0.75, gamma=2.0, iou_weighted=True, reduction='mean'):
"""
Varifocal Loss
参考论文: https://arxiv.org/abs/2008.13367
参数:
pred: 预测的类别概率,形状为 [N, C, H, W] 或 [N, C]
target: 目标标签,形状与pred相同,包含类别索引和IoU信息
alpha: 正样本的权重因子,默认为0.75
gamma: 聚焦参数,默认为2.0
iou_weighted: 是否使用IoU作为正样本的权重,默认为True
reduction: 损失聚合方式,可选 'mean', 'sum', 'none'
"""
# 确保pred和target的形状一致
assert pred.shape == target.shape
# 分离正样本和负样本
pos_inds = target > 0
neg_inds = target == 0
# 正样本损失计算
pos_pred = pred[pos_inds]
pos_target = target[pos_inds]
if iou_weighted:
# 使用IoU作为正样本的权重
weight = alpha * pos_target ** gamma
else:
weight = alpha * (2 - pos_target) ** gamma
# 正样本的损失:-weight * target * log(sigmoid(pred))
pos_loss = -weight * pos_target * F.logsigmoid(pos_pred)
# 负样本损失计算
neg_pred = pred[neg_inds]
# 负样本的损失:-(1 - alpha) * (1 - target) * log(1 - sigmoid(pred))
neg_loss = -(1 - alpha) * torch.pow(1 - neg_pred, gamma) * F.logsigmoid(-neg_pred)
# 聚合损失
loss = torch.cat([pos_loss, neg_loss], dim=0)
if reduction == 'mean':
return loss.mean()
elif reduction == 'sum':
return loss.sum()
else:
return loss
在本研究中,我们将Varifocal Loss应用于苹果果实检测模型的训练中,替代了原始的交叉熵损失函数。实验结果表明,Varifocal Loss能够有效地提高模型的检测精度,特别是在小目标和遮挡目标的检测方面,同时加快了模型的收敛速度。
此外,为了进一步提高训练效果,我们还将Varifocal Loss与CIoU损失函数结合使用,分别用于类别预测和边界框回归,共同优化模型性能。这种组合损失函数的使用,使得模型在保持高检测精度的同时,还能够准确地定位苹果果实的位置。
重难点和创新点
本研究在基于改进YOLO算法的苹果果实识别与成熟度检测方面,具有以下几个创新点:
轻量级苹果果实检测模型设计
本研究提出了一种基于MobileNetV3和CBAM注意力机制的轻量级苹果果实检测模型,具有以下创新点:
-
主干网络优化:将MobileNetV3作为YOLOv5的主干网络,利用深度可分离卷积、SE注意力机制等技术,在保持较高特征提取能力的同时,显著减少了模型参数量和计算复杂度。
-
注意力机制融合:在主干网络中引入CBAM注意力模块,增强了模型对苹果果实特征的提取能力,特别是在复杂背景和光照变化的情况下,能够更好地关注果实区域,减少背景干扰。
-
损失函数改进:采用Varifocal Loss损失函数代替传统的交叉熵损失函数,更好地处理类别不平衡问题,提高小目标和遮挡目标的检测精度。
实验结果表明,改进后的轻量级模型参数量仅为3.20M,模型大小约为6.8MB,在RTX 3090 GPU上的推理速度达到82.2FPS,平均准确率达到90.8%,实现了高精度和轻量化的良好平衡。
苹果果实成熟度检测方法
本研究提出了一种基于改进YOLOv5s的苹果果实成熟度检测方法,具有以下创新点:
-
注意力机制选择:通过对比实验,选择了SE注意力机制作为最佳的特征增强方法,SE注意力机制能够自适应地调整通道间的依赖关系,增强模型对颜色特征的感知能力,这对于区分不同成熟度的苹果果实尤为重要。
-
锚框优化:使用K-means++聚类算法对训练集中的标注框进行聚类,生成更符合苹果果实形状和大小的先验框,提高了模型的定位精度。
-
特征融合结构改进:将YOLOv5s的特征融合层从PANet改进为BiFPN结构,通过添加跳跃连接和权重调整机制,增强了不同尺度特征之间的信息流动,提高了模型对不同大小苹果果实的检测和分类能力。
总结
本研究针对苹果果实识别和成熟度检测的需求,基于改进YOLO算法,设计并实现了轻量级苹果果实检测模型和苹果果实成熟度检测模型,主要工作总结如下:
-
提出了一种轻量级的苹果果实检测模型,在保持高检测精度的同时,显著减小了模型体积,提高了计算效率,为嵌入式设备上的实时检测提供了可能。
-
提出了一种准确的苹果果实成熟度检测方法,能够有效区分不同成熟度的苹果果实,为苹果的自动分拣和品质评估提供了技术支持。
-
构建了一个完整的苹果果实识别与成熟度检测系统,验证了模型在实际应用中的有效性和可行性。
未来的研究方向包括:
-
扩展数据集,增加不同品种、不同生长环境的苹果图像,提高模型的泛化能力。
-
进一步优化模型结构,探索更高效的轻量化方法,提高模型在资源受限设备上的性能。
参考文献
[1] Tang Y, Chen M, Wang C, et al. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review[J]. Frontiers in Plant Science, 2020, 11: 583458.
[2] Mureşan H, Oltean M. Fruit recognition from images using deep learning[J]. arXiv preprint arXiv:2112.12062, 2021.
[3] Hussain D, Hussain I, Ismail M, et al. A Simple and Efficient Deep Learning-Based Framework for Automatic Fruit Recognition[J]. Computational Intelligence and Neuroscience, 2022, 2022: 6538117.
[4] Gao F, Fu L, Zhang X, et al. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN[J]. Computers and Electronics in Agriculture, 2020, 176: 105634.
[5] Wang Y, Yi Y, Wang X, et al. Fig Fruit Recognition Method Based on Yolo v54 Deep Learning[A]. 2021 18th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON)[C]. 2021: 303-306.
[6] Lin T-Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327.
[7] Zhang H, Wang Y, Dayoub F, et al. VarifocalNet: An IoU-Aware Dense Object Detector[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 8514-8523.
[8] Hou Q, Zhou D, Feng J. Coordinate Attention for Efficient Mobile Network Design[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13713-13722.


















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









