




目录
选题意义背景
随着第五代移动通信技术(5G)与智能传感终端的快速发展与普及,位置感知服务已深度融入现代社会的方方面面,形成了覆盖智慧城市、智能交通、个性化推荐等多模态应用场景的服务生态体系,然而,位置隐私泄露的风险也随之显著增加,对用户个人隐私安全构成了严峻挑战。在当前位置服务生态中,用户面临的隐私威胁主要体现在以下几个方面:
- 基于地理位置的社交网络(LBSNs)通过采集和分析用户的位置轨迹,能够推断出用户的个人生活习惯、行为模式甚至健康状况等敏感信息。
- 位置数据的过度收集和不当使用已经引发了多起严重的隐私泄露事件。
- 攻击者可以利用先进的机器学习算法对匿名化处理后的位置数据进行去匿名化攻击,从而重新识别出特定用户的真实身份和行为模式。
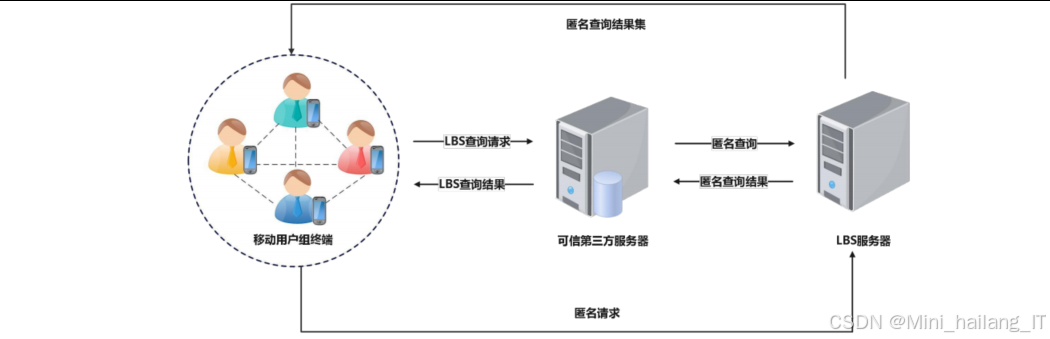
传统的位置隐私保护方法主要包括k-匿名、l-多样性、位置混淆和差分隐私等技术。然而,这些方法在实际应用中存在诸多局限性:k-匿名方法虽然能够提供一定程度的隐私保护,但在面对背景知识攻击时容易失效;l-多样性方法通过确保敏感属性的多样性来增强隐私保护,但未能充分考虑时空行为维度的关联风险;位置混淆方法通过降低位置精度来保护隐私,但会显著影响服务质量;传统的差分隐私方法虽然具有严格的数学安全保障,但在小样本情境下容易产生语义失真,且未能充分考虑用户的个性化隐私需求。
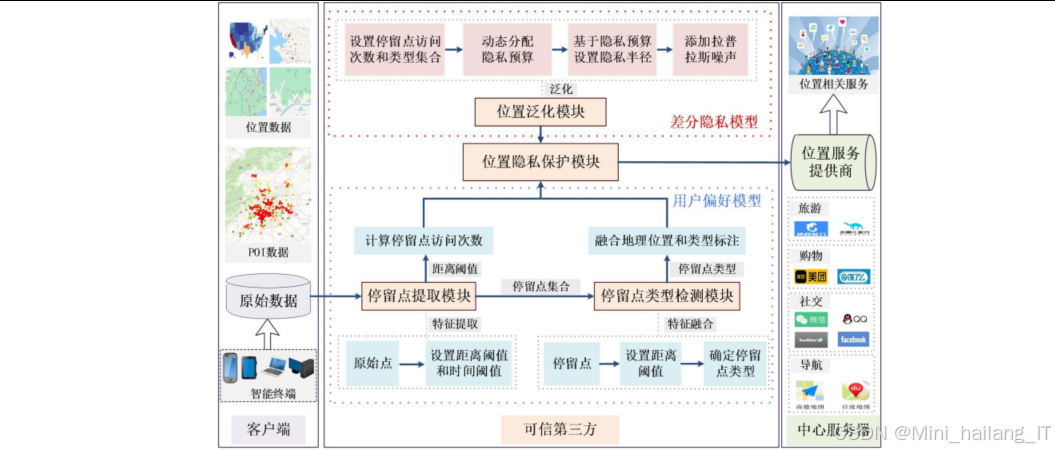
数据集
为了确保实验数据的质量和可用性,对原始数据进行了一系列预处理操作,主要包括数据清洗、停留点提取、特征工程和数据分割等步骤。
数据清洗:
- 异常值处理:删除GPS漂移导致的异常点(如超出正常地理范围的坐标点)
- 噪声过滤:通过滑动窗口平均法过滤短期噪声干扰
- 数据完整性检查:删除采样率过低或记录不完整的轨迹段
- 重复数据处理:合并时间和空间上高度重合的轨迹数据
停留点提取:
- 算法选择:基于时间阈值和距离阈值的停留点提取算法
- 参数设置:时间阈值Tth设为20分钟,距离阈值Dth设为200米
- 提取过程:遍历GPS轨迹点,当连续点集满足时间阈值和距离阈值时,将其识别为一个停留点
- 停留点表示:每个停留点表示为四元组(纬度、经度、到达时间、离开时间)
- 停留点聚合:将时间和空间上接近的停留点进行聚类合并,减少数据冗余
特征工程:
- 停留点特征提取:
- 停留持续时间:计算每个停留点的持续时间(离开时间-到达时间)
- 日周期特征:将一天划分为不同时段(如工作日/周末,白天/夜晚)
- 访问频率:统计用户在各停留点的访问次数和频率
- 语义特征构建:
- 基于POI的语义标注:将停留点与周边POI进行空间关联,获取语义类别标签
- 环境特征提取:分析停留点周边的POI分布情况,构建环境特征向量
- 图结构特征:
- 节点特征:将停留点作为图节点,节点特征包括时空属性和语义属性
- 边特征:基于地理邻近性和用户移动序列构建图的边关系
数据分割策略:
- 时间分割:将数据集按时间划分为训练集(70%)、验证集(15%)和测试集(15%)
- 用户分割:确保训练集、验证集和测试集中包含不同用户的数据,避免用户信息泄露
- 交叉验证:采用10折交叉验证方法评估模型性能,确保实验结果的可靠性和稳定性
功能模块
轨迹数据预处理模块
功能概述:该模块负责对原始GPS轨迹数据进行清洗、降噪和结构化处理,为后续模块提供高质量的输入数据,采用多阶段数据处理策略,结合时空过滤和异常检测技术,有效去除噪声数据,保留有意义的轨迹信息:
- 数据加载与解析:读取原始轨迹数据文件,解析GPS点的经纬度、时间戳和海拔等信息
- 异常点检测与过滤:
- 基于速度阈值的异常检测:计算相邻GPS点之间的移动速度,过滤超出正常速度范围(如>120km/h)的异常点
- 基于空间聚类的异常检测:使用DBSCAN算法识别空间离群点,过滤GPS漂移导致的错误位置
- 轨迹分段处理:根据时间间隔和空间距离,将连续轨迹分割为独立的轨迹段,便于后续处理
- 数据标准化:将经纬度坐标转换为统一坐标系,时间戳转换为标准格式
- 数据压缩:在保持轨迹形状的前提下,使用Douglas-Peucker算法对轨迹点进行压缩,减少数据量
停留点提取与语义标注模块
功能概述:该模块负责从处理后的轨迹数据中提取用户的停留点,并为每个停留点添加语义类别标签,为个性化隐私保护提供基础,结合时空聚类和POI数据关联分析,实现停留点的准确识别和语义理解:
-
停留点提取:
- 基于滑动窗口的停留点识别:设置时间阈值(20分钟)和距离阈值(200米),当窗口内的GPS点满足条件时,判定为一个停留点
- 停留点特征计算:计算每个停留点的中心坐标(经纬度平均值)、到达时间和离开时间
- 停留点合并:对空间和时间上接近的停留点进行聚类合并,减少冗余信息
-
POI数据处理:
- POI数据加载与索引:构建POI空间索引,提高查询效率
- POI类型层次划分:建立POI类型的层次化分类体系,支持多级语义标注
-
停留点语义标注:
- 空间范围查询:以停留点为中心,查询指定半径(如2000米)内的所有POI
- 类型权重计算:根据距离衰减模型计算不同POI类型的权重
- 语义类型确定:选择权重最高的POI类型作为停留点的语义标签
差分隐私保护模块
功能概述:该模块是系统的核心,负责实现差分隐私机制,在保护用户隐私的同时保持数据的可用性,采用梯度扰动和噪声注入两种差分隐私实现方式,针对不同的应用场景提供灵活的隐私保护策略
-
隐私预算分配:
- 全局隐私预算确定:根据应用场景和隐私需求,确定总的隐私预算ε
- 动态预算分配:基于用户访问频率和位置敏感度,为不同用户和不同位置动态分配隐私预算
-
梯度扰动实现:
- 梯度裁剪:在模型训练过程中,对梯度进行裁剪,限制梯度的敏感性
- 高斯噪声注入:向裁剪后的梯度添加高斯噪声,满足差分隐私要求
- 参数更新:使用扰动后的梯度更新模型参数,确保模型训练过程符合差分隐私
-
位置泛化实现:
- 拉普拉斯噪声机制:根据隐私预算和敏感度,计算拉普拉斯噪声参数
- 半径阈值确定:基于用户访问频率,动态确定位置泛化的半径阈值
- 噪声添加:向半径阈值添加拉普拉斯噪声,实现位置的差分隐私保护
关键技术点:
- 个性化隐私预算分配算法:根据用户偏好和位置重要性,实现更精准的隐私保护
- 噪声强度优化:在满足隐私要求的前提下,最小化噪声对数据可用性的影响
- 隐私-效用平衡机制:通过动态调整噪声参数,在隐私保护和数据效用之间取得最佳平衡
用户偏好建模与个性化隐私保护模块
功能概述:该模块负责分析用户的行为模式和隐私偏好,实现个性化的隐私保护策略。通过分析用户的访问频率、时间分布和位置类型偏好,构建用户偏好模型,并据此动态调整隐私保护参数。
-
用户偏好分析:
- 访问频率分析:统计用户在不同停留点的访问次数和频率
- 时间模式分析:分析用户访问停留点的时间分布特征
- 类型偏好分析:基于语义标签,分析用户对不同类型位置的偏好
-
偏好模型构建:
- 访问频率阈值确定:计算平均访问次数和标准差,确定高频和低频访问阈值
- 隐私敏感度评估:基于访问频率和位置类型,评估不同位置的隐私敏感度
- 用户偏好向量生成:构建包含访问频率、时间模式和类型偏好的多维偏好向量
-
个性化隐私保护策略:
- 针对高频访问位置:采用更强的隐私保护措施,如更大的噪声或更粗的泛化粒度
- 针对低频访问位置:采用相对较弱的隐私保护,保持较高的数据可用性
- 动态参数调整:根据用户偏好的变化,动态调整隐私保护参数
算法理论
差分隐私
差分隐私是本研究的核心理论基础,为位置隐私保护提供了严格的数学安全保障。差分隐私的核心思想是通过向数据或查询结果添加精心设计的噪声,使得单个数据记录的存在与否不会显著影响最终输出,从而保护个体隐私:
-
拉普拉斯机制:对于实值函数查询,拉普拉斯机制通过添加服从拉普拉斯分布的噪声实现差分隐私。
-
高斯机制:对于高维向量查询或梯度扰动,高斯机制通过添加高斯噪声实现差分隐私。噪声的方差σ²与全局敏感度Δf、隐私预算ε和松弛参数δ相关,计算公式为σ² = 2Δf²ln(1.25/δ)/ε²。在本研究的图自编码器训练过程中,高斯机制用于向梯度添加噪声,确保训练过程满足差分隐私。
-
隐私预算组合规则:
- 顺序组合:当对同一数据集执行多个差分隐私算法时,总隐私预算为各算法隐私预算之和
- 并行组合:当对不相交的数据子集执行差分隐私算法时,总隐私预算为各算法隐私预算的最大值
这些组合规则为本研究中动态隐私预算分配提供了理论依据,使得我们可以在不同处理阶段灵活分配隐私预算。
图自编码器理论
图自编码器是一种专门用于图数据学习的深度学习模型,能够有效捕捉图结构信息和节点特征。在本研究中,我们基于图注意力网络构建了图自编码器,用于位置数据的特征学习和表示。
-
编码器:将图数据映射到低维潜在空间,学习节点的低维表示
-
解码器:基于学习到的低维表示,重构原始图的结构和特征
GAT通过注意力机制实现对图中节点邻居的自适应加权聚合,有效解决了传统图卷积网络(GCN)在处理异构图和动态图时的局限性。GAT的关键计算步骤包括: -
特征变换:对每个节点的特征向量应用线性变换,得到节点的中间表示
-
注意力系数计算:通过计算节点间的注意力分数,确定不同邻居的重要性
-
注意力加权聚合:基于注意力分数,对邻居节点的特征进行加权聚合
DP-GAE算法原理
基于差分隐私的位置图自动编码方法(DP-GAE)将差分隐私机制与图自编码器相结合,实现了对位置图数据的隐私保护和特征学习。通过在图自编码器的训练过程中引入差分隐私机制,对模型梯度添加噪声,确保即使攻击者能够获取模型参数,也无法推断出训练数据中的单个位置记录。
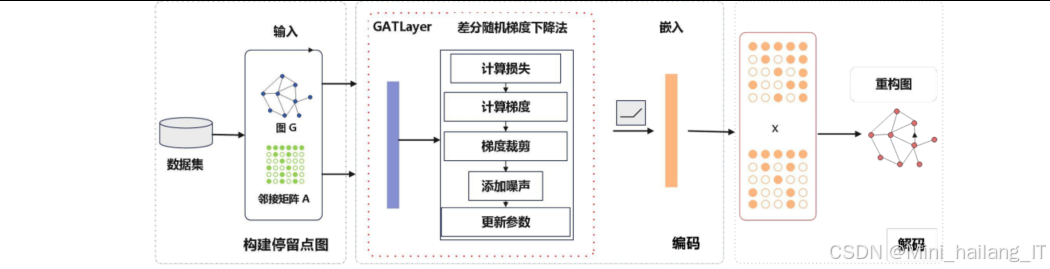
- 图结构构建:将用户的停留点作为图节点,基于地理邻近性和用户移动序列构建边关系
- 差分隐私保护的编码器:使用GAT作为编码器,在训练过程中通过梯度裁剪和噪声注入实现差分隐私
- 解码器:设计与编码器对称的解码结构,重构节点特征和图结构
- 损失函数设计:综合考虑节点特征重构损失和图结构重构损失,优化模型参数
UPDP-LPP算法原理
融合用户偏好与差分隐私的位置隐私保护方法(UPDP-LPP)进一步考虑了用户的个性化隐私需求,实现了更灵活、更精准的位置隐私保护。
-
用户偏好建模理论:通过分析用户的访问频率、时间模式和位置类型偏好,构建用户的偏好模型。高频访问的位置通常对用户更为重要,需要更强的隐私保护。
-
个性化隐私预算分配理论:基于用户偏好,为不同位置动态分配隐私预算,实现个性化的隐私保护。隐私预算分配遵循以下原则:
- 高频访问位置获得更多的隐私预算,对应更强的隐私保护
- 低频访问位置获得较少的隐私预算,在保护基本隐私的同时保持较高的数据效用
-
位置泛化与差分隐私融合理论:结合位置泛化技术和差分隐私机制,通过向位置半径添加拉普拉斯噪声,实现位置的差分隐私保护。噪声的尺度由分配给该位置的隐私预算决定。
核心代码
差分隐私梯度下降实现
差分隐私随机梯度下降(DP-SGD)算法,是DP-GAE模型训练过程中的核心组件。该算法通过梯度裁剪和噪声注入两个关键步骤实现差分隐私保护:首先,对计算得到的梯度进行裁剪,限制其L2范数不超过预设阈值C,这一步是为了控制梯度的敏感度;然后,向裁剪后的梯度添加服从高斯分布的随机噪声,噪声的标准差根据隐私预算ε、松弛参数δ、批量大小和总样本数动态计算。这种实现方式确保了在模型训练过程中,即使攻击者能够访问训练后的模型参数,也无法推断出训练数据中单个样本的信息,从而提供了严格的差分隐私保证。
def dp_sgd_update(params, gradients, epsilon, delta, batch_size, C, total_samples):
"""
实现差分隐私随机梯度下降更新
参数:
- params: 模型参数列表
- gradients: 计算得到的梯度
- epsilon: 隐私预算
- delta: 松弛参数
- batch_size: 批量大小
- C: 梯度裁剪阈值
- total_samples: 总样本数
返回:
- 更新后的模型参数
"""
# 计算采样率
sampling_rate = batch_size / total_samples
# 计算噪声标准差
sigma = (C * np.sqrt(2 * np.log(1.25 / delta))) / (epsilon * sampling_rate)
# 对每个参数进行梯度裁剪和噪声注入
updated_params = []
for param, grad in zip(params, gradients):
# 梯度裁剪
clipped_grad = clip_grad_norm(grad, C)
# 添加高斯噪声
noise = np.random.normal(0, sigma, size=grad.shape)
noisy_grad = clipped_grad + noise
# 参数更新(这里假设学习率为0.01,实际应用中可能需要调整)
updated_param = param - 0.01 * noisy_grad
updated_params.append(updated_param)
return updated_params
def clip_grad_norm(grad, max_norm):
"""
梯度裁剪,将梯度的L2范数限制在max_norm以内
"""
grad_norm = np.linalg.norm(grad)
if grad_norm > max_norm:
return grad * (max_norm / grad_norm)
return grad
图注意力网络编码器实现
基于图注意力网络(GAT)的编码器,是DP-GAE模型的核心组件之一。GAT通过注意力机制学习节点间的重要性关系,能够有效捕捉图结构中的复杂依赖。该实现包含两个主要类:GraphAttentionLayer实现了单个图注意力层,GAT类则组合多个图注意力层构建完整的编码器。
import torch
import torch.nn as nn
import torch.nn.functional as F
class GraphAttentionLayer(nn.Module):
def __init__(self, in_features, out_features, dropout=0.5, alpha=0.2, concat=True):
super(GraphAttentionLayer, self).__init__()
self.dropout = dropout
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.concat = concat
# 初始化权重矩阵
self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
# 初始化注意力参数
self.a = nn.Parameter(torch.zeros(size=(2*out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414)
# LeakyReLU激活函数
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, input, adj):
# 线性变换
h = torch.mm(input, self.W)
N = h.size()[0]
# 计算注意力系数
a_input = torch.cat([h.repeat(1, N).view(N*N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2*self.out_features)
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
# 掩码操作,仅考虑存在的边
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
# 注意力加权聚合
h_prime = torch.matmul(attention, h)
# 输出处理
if self.concat:
return F.elu(h_prime)
else:
return h_prime
class GAT(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):
super(GAT, self).__init__()
self.dropout = dropout
# 多头注意力层
self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
# 输出层
self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False)
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training)
# 多头注意力特征融合
x = torch.cat([att(x, adj) for att in self.attentions], dim=1)
x = F.dropout(x, self.dropout, training=self.training)
# 输出层
x = F.elu(self.out_att(x, adj))
return x
在GraphAttentionLayer中,首先通过线性变换将节点特征映射到新的空间,然后计算节点对之间的注意力系数,接着通过掩码操作只考虑图中存在的边,最后基于注意力权重对邻居节点特征进行加权聚合。GAT类通过多头注意力机制,使用多个注意力层并行处理输入特征,然后将结果拼接,从而捕获不同视角的图结构信息。这种设计使得编码器能够更全面地学习位置图数据的结构特征和语义关系,为后续的差分隐私保护和数据重构提供高质量的特征表示。
用户偏好分析与个性化隐私保护
基于用户偏好的个性化隐私保护方法(UPDP-LPP)的核心功能,包括用户偏好分析和个性化隐私预算分配。代码分为三个主要函数:
analyze_user_preferences函数负责分析用户的停留点数据,确定每个停留点的语义类型和访问频率。它通过计算停留点与周边POI的距离关系,为每个停留点分配最可能的类型标签,并统计各类位置的访问次数,从而构建用户的偏好模型。
personalized_privacy_protection函数是UPDP-LPP的核心,它根据用户偏好实现个性化的隐私保护。首先,它基于访问频率统计确定高频和低频访问的阈值;然后,根据访问频率为不同类型的位置分配不同的隐私预算;接着,根据访问频率确定基础半径阈值,并添加与隐私预算相关的拉普拉斯噪声;最后,在同类型的停留点中选择候选点进行位置泛化。
personalize_location函数实现了位置泛化的具体逻辑,它根据噪声半径和位置类型,在所有停留点中查找符合条件的候选点,并随机选择一个作为泛化后的位置。
import numpy as np
def analyze_user_preferences(stay_points, poi_data, theta_distance=2000):
"""
分析用户偏好,确定停留点类型和访问频率
参数:
- stay_points: 停留点集合,每个停留点包含(lat, lon, arvT, levT)
- poi_data: POI数据,包含各类POI的位置和类型信息
- theta_distance: 距离阈值,用于POI匹配
返回:
- user_preferences: 用户偏好字典,包含停留点类型和访问频率
"""
stay_point_types = {}
visit_counts = {}
# 为每个停留点确定类型
for idx, sp in enumerate(stay_points):
sp_lat, sp_lon = sp[0], sp[1]
type_candidates = {}
# 查找周边POI
for poi_type, pois in poi_data.items():
distances = []
for poi in pois:
poi_lat, poi_lon = poi[0], poi[1]
# 计算距离
dist = calculate_distance(sp_lat, sp_lon, poi_lat, poi_lon)
if dist < theta_distance:
distances.append(dist)
if distances:
# 计算加权平均距离
weights = [1.0/d for d in distances] if 0 not in distances else [1.0 for _ in distances]
total_weight = sum(weights)
weighted_avg_dist = sum(w*d for w, d in zip(weights, distances)) / total_weight
type_candidates[poi_type] = weighted_avg_dist
# 选择距离最近的POI类型
if type_candidates:
sp_type = min(type_candidates, key=type_candidates.get)
stay_point_types[idx] = sp_type
# 更新访问计数
if sp_type in visit_counts:
visit_counts[sp_type] += 1
else:
visit_counts[sp_type] = 1
return {
'stay_point_types': stay_point_types,
'visit_counts': visit_counts
}
def personalized_privacy_protection(stay_points, user_preferences, epsilon_total):
"""
基于用户偏好的个性化隐私保护
参数:
- stay_points: 停留点集合
- user_preferences: 用户偏好信息
- epsilon_total: 总隐私预算
返回:
- protected_points: 隐私保护后的停留点集合
"""
stay_point_types = user_preferences['stay_point_types']
visit_counts = user_preferences['visit_counts']
# 计算访问频率统计信息
visit_freqs = list(visit_counts.values())
avg_visits = np.mean(visit_freqs)
std_visits = np.std(visit_freqs)
theta_max = avg_visits + std_visits
theta_min = max(1, avg_visits - std_visits)
# 计算每种类型的隐私预算
privacy_budgets = {}
total_weight = sum(v for v in visit_counts.values())
for sp_type, count in visit_counts.items():
# 高频访问类型分配更多隐私预算
weight = count / total_weight
privacy_budgets[sp_type] = epsilon_total * weight
protected_points = []
for idx, sp in enumerate(stay_points):
if idx not in stay_point_types:
# 没有类型信息的停留点,使用默认保护
protected_points.append(sp)
continue
sp_type = stay_point_types[idx]
visit_count = visit_counts[sp_type]
epsilon = privacy_budgets[sp_type]
# 根据访问频率确定基础半径
if visit_count > theta_max:
base_radius = 500 # 高频访问,更大的基础半径
elif visit_count < theta_min:
base_radius = 100 # 低频访问,更小的基础半径
else:
base_radius = 300 # 中频访问,中等基础半径
# 计算噪声敏感度(与访问频率相关)
noise_sensitivity = base_radius / visit_count if visit_count > 0 else base_radius
# 添加拉普拉斯噪声
noise = np.random.laplace(0, noise_sensitivity/epsilon)
noisy_radius = max(0, base_radius + noise)
# 执行位置泛化(这里简化实现,实际需要在同类型POI中选择)
protected_sp = personalize_location(sp, noisy_radius, sp_type, stay_points, stay_point_types)
protected_points.append(protected_sp)
return protected_points
def personalize_location(sp, radius, sp_type, all_stay_points, stay_point_types):
"""
根据噪声半径和类型进行位置泛化
"""
# 查找同类型且在半径范围内的候选停留点
candidates = []
sp_lat, sp_lon = sp[0], sp[1]
for idx, candidate_sp in enumerate(all_stay_points):
if idx != sp_idx and idx in stay_point_types and stay_point_types[idx] == sp_type:
dist = calculate_distance(sp_lat, sp_lon, candidate_sp[0], candidate_sp[1])
if dist <= radius:
candidates.append(candidate_sp)
# 如果有候选点,随机选择一个;否则返回原始点
if candidates:
return random.choice(candidates)
else:
return sp
这种实现方式充分考虑了用户的个性化偏好,为不同重要性的位置提供差异化的隐私保护,在保护关键位置隐私的同时,最大限度地保持了数据的可用性,实现了隐私保护和数据效用的最佳平衡。
创新点
** 基于差分隐私的位置图自动编码方法(DP-GAE)**
本研究的第一个主要创新点是提出了基于差分隐私的位置图自动编码方法(DP-GAE),将图自编码器与差分隐私机制有机结合,实现了对位置图数据的有效保护和利用。
创新内容:
- 图注意力机制与差分隐私的融合:创新性地将图注意力网络(GAT)作为编码器,通过注意力机制捕捉图中的复杂关系,同时通过梯度扰动实现差分隐私保护
- 多级隐私保护策略:在图嵌入的不同层次实施不同强度的隐私保护,针对包含敏感信息的层加强保护
- 结构化损失函数设计:设计了同时考虑节点特征重构和图结构重构的复合损失函数,在保护隐私的同时保持图的结构信息
- 理论隐私保证:通过理论证明,DP-GAE能够满足(ε, δ)-差分隐私,为位置数据提供严格的隐私保护
创新价值:DP-GAE方法不仅实现了对位置数据的隐私保护,还能有效学习图结构的表示特征,为位置推荐、异常检测等下游任务提供高质量的特征输入,填补了图神经网络在位置隐私保护领域应用的研究空白。
** 融合用户偏好与差分隐私的位置隐私保护方法(UPDP-LPP)**
本研究的第二个主要创新点是提出了融合用户偏好与差分隐私的位置隐私保护方法(UPDP-LPP),实现了个性化的位置隐私保护。
创新内容:
- 用户偏好驱动的隐私保护框架:建立了以用户偏好为核心的隐私保护框架,根据用户对不同位置的重视程度提供差异化保护
- 动态隐私预算分配算法:设计了基于访问频率和位置类型的动态隐私预算分配算法,为高频访问的重要位置分配更多隐私预算
- 自适应半径阈值与噪声机制:根据用户偏好动态调整位置泛化的半径阈值,并添加与隐私预算相关的拉普拉斯噪声
- 语义感知的位置泛化:在同类型位置中进行泛化,保持位置的语义信息,提高数据效用
创新价值:UPDP-LPP方法改变了传统差分隐私保护中"一刀切"的做法,实现了从静态统一保护到动态个性化保护的转变,在保护用户关键隐私的同时,最大限度地保持了数据的可用性,为位置服务提供了更灵活、更精准的隐私保护解决方案。
** 基于语义空间信息的停留点类型检测算法**
本研究的第三个主要创新点是提出了基于语义空间信息的停留点类型检测算法,通过融合轨迹数据和POI数据,实现了对停留点语义的准确理解。
创新内容:
- 空间关联度计算模型:设计了综合考虑距离和分布密度的空间关联度计算模型,更准确地识别停留点的语义类型
- 多维度特征融合:融合时空特征和POI分布特征,构建多维度的特征表示,提高类型检测准确性
- 自适应类型阈值:根据不同地区和不同类型POI的分布特征,动态调整类型判断的阈值参数
- 层次化类型分类:采用层次化的类型分类体系,支持从大类到小类的多级语义标注
创新价值:该算法不仅提高了停留点语义理解的准确性,还为个性化隐私保护策略的制定提供了重要依据,使隐私保护能够更好地适应不同语义类型位置的特点和需求。
** 隐私-效用平衡优化方法**
本研究的第四个主要创新点是提出了一种隐私-效用平衡优化方法,通过理论分析和实验验证,确定了最优的隐私保护参数,实现了隐私保护和数据效用的最佳平衡。
创新内容:
- 多目标优化框架:建立了同时考虑隐私保护水平和数据效用的多目标优化框架
- 隐私-效用折衷曲线分析:通过系统实验,绘制了不同参数设置下的隐私-效用折衷曲线,为参数选择提供了直观参考
- 自适应参数调整机制:设计了基于用户反馈和系统性能监测的自适应参数调整机制,动态优化隐私保护参数
- 领域特定的效用度量:针对位置服务的特点,设计了专门的效用度量指标,更准确地评估数据在实际应用中的可用性
总结
本研究针对位置服务中的隐私保护问题,深入探讨了基于用户偏好与差分隐私的位置隐私保护方法,提出了两种创新的隐私保护算法:基于差分隐私的位置图自动编码方法和融合用户偏好与差分隐私的位置隐私保护方法。通过系统的理论研究和实验验证,本研究取得了以下主要成果:
-
基于差分隐私的位置图自动编码方法(DP-GAE),将图注意力网络与差分隐私机制有机结合。该方法通过在图自编码器的训练过程中引入差分隐私,对梯度进行裁剪和噪声注入,实现了对位置图数据的隐私保护。
-
融合用户偏好与差分隐私的位置隐私保护方法(UPDP-LPP),实现了个性化的位置隐私保护。该方法通过分析用户的访问频率和位置类型偏好,动态分配隐私预算,为不同重要性的位置提供差异化的隐私保护。实验结果表明,UPDP-LPP在保护用户隐私和保持数据效用方面均优于传统方法,能够在提高隐私保护水平的同时,保持较高的数据效用和计算效率。特别是对于高频访问的重要位置,UPDP-LPP能够提供更强的隐私保护,而对于低频访问的位置,则保持较高的数据可用性,实现了隐私保护和数据效用的最佳平衡。
第四,本研究设计了基于语义空间信息的停留点类型检测算法,通过融合轨迹数据和POI数据,实现了对停留点语义的准确理解。该算法通过计算停留点与周边不同类型POI的空间关联度,确定其语义类型,为个性化隐私保护策略的制定提供了重要依据。实验表明,该算法能够有效识别用户的重要位置(如家庭、工作场所),为后续的隐私保护提供了准确的语义信息。
第五,本研究通过系统的实验评估,全面比较了所提出方法与现有方法在隐私保护水平、数据效用和计算效率三个维度的性能。实验结果表明,DP-GAE和UPDP-LPP在各项指标上均优于传统方法,特别是在隐私-效用平衡方面表现突出。
尽管本研究取得了显著成果,但仍存在一些局限性和未来研究方向。首先,可以进一步探索更高效的图神经网络结构与差分隐私机制的融合方式,以提升隐私保护效果和数据处理效率;其次,可以研究如何通过智能化手段动态调整隐私参数,以更好地适应不同用户的偏好变化和服务场景的需求;第三,可以将研究成果应用于更复杂的实际场景,如大规模位置社交网络、智慧城市等,评估其可扩展性和鲁棒性;最后,可以研究如何将技术创新与隐私法规和伦理框架相结合,确保技术应用的合规性和社会接受度。
总之,本研究通过创新的方法设计和系统的实验验证,为位置隐私保护领域提供了新的思路和技术方案,有望在未来的位置服务中得到广泛应用,为保护用户隐私和促进位置服务健康发展做出贡献。
参考文献
[1] Jiang H, Li J, Zhao P, et al. Location privacy-preserving mechanisms in location-based services: A comprehensive survey[J]. ACM Computing Surveys, 2021, 54(1): 1-36.
[2] Wang Y, Zhang J, Ma Z, et al. Location-Aware and Privacy-Preserving Data Cleaning for Intelligent Transportation[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25: 20405-20418.
[3] Cai Z, Zheng X, Wang J, et al. Private data trading towards range counting queries in internet of things[J]. IEEE Transactions on Mobile Computing, 2022, 22(8): 4881-4897.
[4] Yang X, Huang W, Ye M. Dynamic personalized federated learning with adaptive differential privacy[J]. Advances in Neural Information Processing Systems, 2023, 36: 72181-72192.
[5] Li X, Xu L, Zhang H, et al. Differential privacy preservation for graph auto-encoders: A novel anonymous graph publishing model[J]. Neurocomputing, 2023, 521: 113-125.
[6] Jiang H, Pei J, Yu D, et al. Applications of differential privacy in social network analysis: A survey[J]. IEEE transactions on knowledge and data engineering, 2021, 35(1): 108-127.
[7] Ma B, Wang X, Ni W, et al. Personalized location privacy with road network-indistinguishability[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(11): 20860-20872.
[8] Wang B, Li H, Ren X, et al. An efficient differential privacy-based method for location privacy protection in location-based services[J]. Sensors, 2023, 23(11): 5219.


















 3755
3755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









