




 本文介绍了如何利用大数据技术开发一个世界杯可视化系统,结合机器学习的预测模型,特别是聚类算法和决策树,对冠军进行预测。文章详细阐述了设计思路,包括数据收集、特征工程、算法应用,以及数据可视化的实践,如数据清洗、图表展示和交互式设计。
本文介绍了如何利用大数据技术开发一个世界杯可视化系统,结合机器学习的预测模型,特别是聚类算法和决策树,对冠军进行预测。文章详细阐述了设计思路,包括数据收集、特征工程、算法应用,以及数据可视化的实践,如数据清洗、图表展示和交互式设计。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长大数据毕设专题,本次分享的课题是
🎯基于大数据的世界杯可视化以及冠军预测系统
项目背景
随着大数据技术的日益成熟和体育产业的蓬勃发展,利用大数据对体育赛事进行分析和预测已成为研究热点。基于大数据的世界杯可视化以及冠军预测系统,不仅能为球迷提供更为直观、深入的比赛数据解读,还能辅助体育机构进行更为科学的赛事策划和决策。该系统通过收集、整合历届世界杯的海量数据,运用先进的数据挖掘和机器学习算法,对冠军归属进行预测,旨在揭示隐藏在数据背后的冠军密码,为世界杯赛事增添更多悬念和看点。
设计思路
预测系统利用机器学习算法和统计学方法对历史数据进行训练和学习,以预测未来的比赛结果。分类算法、回归算法和聚类算法是常用的预测模型,而特征工程和参数调优等技术则用于提高模型的准确性。冠军预测系统能够提供有价值的预测,但也需要谨慎对待其结果,因为比赛结果受到许多不可预测因素的影响。
聚类算法是一种无监督学习方法,它不需要预先定义聚类的数量或类别,而是通过数据之间的相似性来自动进行分类。这种方法的目的是将数据集中的对象按照它们的相似性特征进行分组,使得同一组(即聚类)内的对象尽可能相似,而不同组的对象尽可能不同。聚类算法在许多领域都有广泛的应用,例如数据挖掘、统计学、机器学习和模式识别等。在数据挖掘中,聚类算法可用于市场细分、客户分群、探索性数据分析等。在统计学中,聚类算法可以用于对数据进行探索性分析和描述性统计分析。在机器学习中,聚类算法可以用于无监督学习任务,例如异常检测、降维和归纳学习等。在模式识别中,聚类算法可以用于图像分割、语音识别和文本挖掘等。
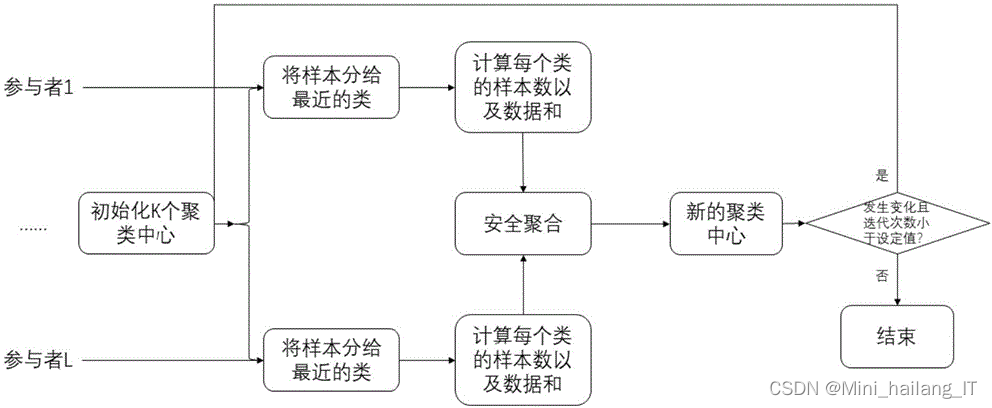
聚类算法有许多不同的实现方法,其中一些常见的算法包括K-means算法、层次聚类、DBSCAN、K-medoids、Mean Shift、OPTICS、BIRCH、谱聚类和模糊C-means等。这些算法都有各自的特点和适用场景,选择合适的算法取决于具体的数据集和问题需求。K-means算法是一种经典的聚类算法,其基本流程如下:首先,从数据集中随机选择K个对象作为初始质心,然后根据每个对象与质心的距离,将其分配到最近的质心的聚类中。接着,重新计算每个聚类的质心,即将每个聚类中所有对象的平均值作为新的质心。重复上述过程,直到质心不再发生明显变化或达到预设的迭代次数。K-means算法的目标是使得每个对象与其所属聚类的质心之间的距离之和最小化。该算法具有简单、高效的特点,适用于大规模数据的聚类分析。
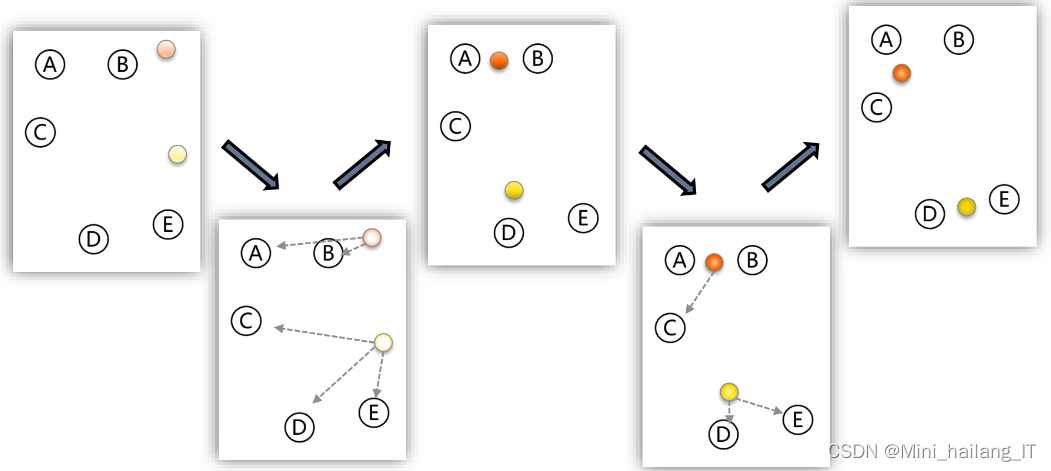
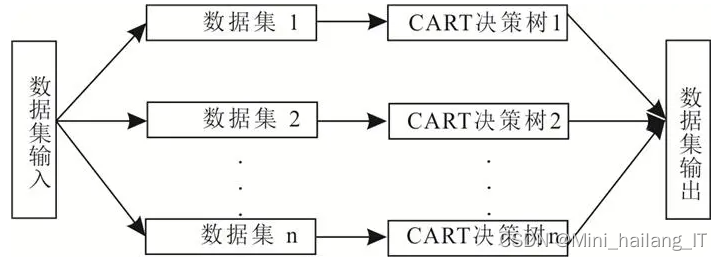
决策树算法是一种常用的分类方法,用于逼近离散函数值。它首先对数据进行处理,然后利用归纳算法生成可读的规则和决策树,最后使用决策树对新数据进行分析。决策树是通过一系列规则对数据进行分类的过程,本质上是一种通过树形图进行决策的预测模型。它表现的是对象属性与对象值之间的一种映射关系,是归纳学习和数据挖掘的重要方法。
决策树算法的构造包括两个主要步骤。第一步是决策树的生成,即由训练样本集生成决策树的过程。通常,训练样本数据集是根据实际需求和有一定综合程度的用于数据分析处理的数据集。第二步是决策树的剪枝,即对上一阶段生成的决策树进行检验、校正和修下的过程,主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除。
数据可视化是将大量复杂的数据转化为图形、图表或其他易于理解的视觉表示形式的过程。它的目标是让用户能够快速、准确地理解数据中的信息,发现数据中的模式、趋势和关联。以下是对您提到的几个关键点的详细解释:
选择各种图表、地图、热力图等展示数据:
- 图表:是最常见的可视化形式,包括条形图、折线图、饼图、散点图、柱状图等。每种图表都有其特定的用途,能够突出显示数据的不同方面。
- 地图:用于展示地理空间数据,可以通过颜色、大小或形状的变化来表示不同地区的数值差异,如人口密度图、选举结果图等。
- 热力图:是一种用颜色变化来表示数据值大小的可视化方法,常用于显示大量数据点的密度或强度,如网站点击热图、气象数据图等。

支持交互式操作和动态更新:
- 交互式操作:允许用户与可视化结果进行互动,如放大、缩小、拖动、筛选数据、切换视图等。这种交互性可以增强用户的参与感和理解深度。
- 动态更新:意味着可视化结果可以实时地反映数据的变化。当数据源更新时,图表、地图等也会相应地自动更新,确保用户看到的是最新信息。
提供多种数据可视化工具和模板:
- 可视化工具:是一系列软件或库,它们提供了创建各种图表和图形的功能。例如,Tableau、Power BI、D3.js、Matplotlib等都是流行的数据可视化工具。
- 模板:是预先设计好的可视化布局和样式,用户可以在模板的基础上快速生成自己的可视化报告,而无需从头开始设计。模板通常包含了颜色方案、字体、图表类型等设计元素。
import pandas as pd
import matplotlib.pyplot as plt
world_cup_data = pd.read_csv('world_cup_data.csv')
# 你可以根据需要筛选和排序数据
world_cup_data = world_cup_data.sort_values(by='year')
# 创建一个条形图,显示每个国家赢得世界杯的次数
winners = world_cup_data['winners']
plt.bar(winners.index, winners)
plt.xlabel('Countries')
plt.ylabel('World Cup Wins')
plt.title('World Cup Winners')
plt.show()为了构建这个世界杯可视化及冠军预测系统,我发现网络上缺乏合适的世界杯赛事数据集。因此,我决定亲自采集和整理数据,制作了一个全新的世界杯赛事数据集。我收集了历届世界杯的比赛数据、球队信息、球员表现等多维度数据,并进行了清洗和格式化处理。通过这个过程,我能够捕捉到世界杯赛事的全方位信息和历史变迁趋势,为我的研究提供了准确、可靠的数据基础。我相信这个自制的数据集将为世界杯赛事的可视化和冠军预测研究提供有力支持,并为该领域的发展做出积极贡献。
# 世界杯数据爬取函数
def fetch_world_cup_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
table = soup.find('table', {'class': 'match-table'}) # 根据实际的表格类名调整
rows = table.find_all('tr')
data = []
for row in rows:
cols = row.find_all('td')
cols = [element.text.strip() for element in cols]
data.append([element for element in cols if element]) # 移除非字符串元素
return data
# 清洗数据函数
def clean_world_cup_data(data):
cleaned_data = []
for row in data:
# 根据实际数据结构调整清洗逻辑
cleaned_row = {
'year': int(row[0]), # 假设年份是整数,需要转换为整数类型
'country': row[1], # 国家名称
'winners': row[2], # 获胜者名称(可能是国家或队伍)
'participants': row[3] # 参赛队伍数量或其他相关信息
}
cleaned_data.append(cleaned_row)
return cleaned_data 海浪学长项目示例:
 更多帮助
更多帮助

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









