




 本文介绍了一种基于机器学习的虚假新闻判别系统,利用Transformer、VisionTransformer和SwinTransformer等技术提取多模态特征。设计思路包括社交上下文特征的处理和编码,以及模型的训练策略。作者还分享了数据集的创建过程和模型训练方法,旨在帮助大学生高效完成毕业设计项目。
本文介绍了一种基于机器学习的虚假新闻判别系统,利用Transformer、VisionTransformer和SwinTransformer等技术提取多模态特征。设计思路包括社交上下文特征的处理和编码,以及模型的训练策略。作者还分享了数据集的创建过程和模型训练方法,旨在帮助大学生高效完成毕业设计项目。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于机器学习的虚假新闻判别真伪系统
项目背景
虚假新闻的盛行给个人和社会带来了严重的负面影响。首先,它浪费了人们的时间和精力,因为人们需要花费大量的时间来辨别真假信息,同时被虚假新闻误导,导致资源的浪费。其次,虚假新闻对个人心理造成负面影响,包括冷漠心理、恐慌心理和焦虑心理。人们可能感到无助和困惑,失去对事实的信任,甚至对信息变得冷漠。此外,虚假新闻还会侵害个人的隐私权、肖像权和名誉权,对受害人的生活造成不可挽回的影响。
设计思路
基于缩放点积注意力机制的Transformer模型在自然语言处理和计算机视觉领域得到了广泛应用。在虚假新闻检测任务中,特征提取是一个关键步骤,而预训练模型在这方面展现出了强大的处理能力。注意力机制能够融合不同模态的特征,得到包含多模态信息的联合表示。
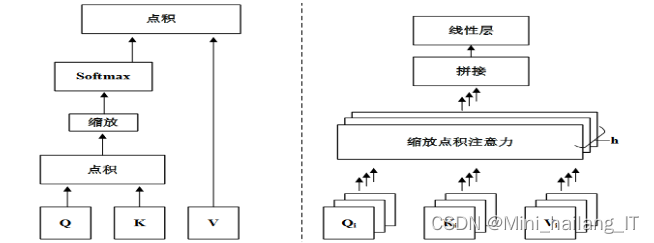
虚假新闻检测模型将采用先进的技术,其中包括Vision Transformer、Masked Autoencoders和Swin Transformer模型。Vision Transformer将图像视为由单词组成的序列,并将其作为Transformer编码器的输入。Masked Autoencoders在预训练阶段使用未被遮掩的图像碎片来预测被遮掩的碎片,以学习图像的全局上下文信息。
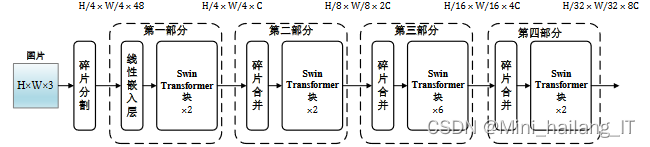
将图像视为单词序列并直接应用标准的Transformer编码器在计算机视觉任务中面临两个挑战。首先,不同的视觉元素具有巨大的尺寸差异。其次,某些密集预测任务要求处理高分辨率图像,而标准Transformer模型难以处理高像素图像。为了解决这些问题,Swin Transformer采用了基于窗口的多头注意力机制。它将特征图均匀划分为多个不重叠的窗口,并在每个窗口内进行自注意力操作,以捕捉窗口之间的依赖关系。此外,Swin Transformer还使用基于"转移窗口"的多头注意力机制,在不同窗口之间移动并建立相邻窗口之间的关联。通过多个Swin Transformer块的堆叠,Swin Transformer模型具有了捕捉全局上下文的能力。
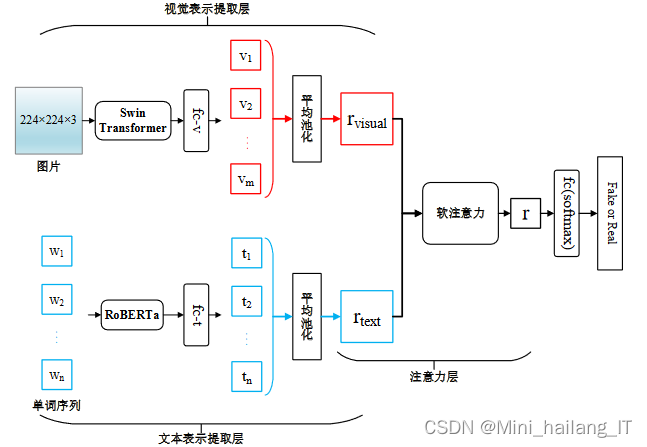
虚假新闻检测模型的整体结构分为三层:嵌入层、编码器层和全连接层。嵌入层中,将社交上下文特征序列𝑆 = [𝑠1, 𝑠2, … , 𝑠𝑛]转化为对应的社交上下文特征嵌入序列𝑋 = [𝑥[𝐶𝐿𝑆], 𝑥1, 𝑥2, … , 𝑥𝑛]。首先,利用全连接层将每个社交上下文特征𝑠𝑖转化为维度固定为𝑑 × 1的社交上下文特征嵌入𝑒𝑖。编码器层用于捕捉社交上下文特征嵌入之间的相互关系,并输出每个社交上下文特征嵌入对应的特征表示。具体的编码器结构可能采用多个Transformer编码器组成。全连接层利用从编码器层中得到的特征表示来预测虚假新闻的概率。这个全连接层具有Sigmoid激活函数,输出虚假新闻的概率值。
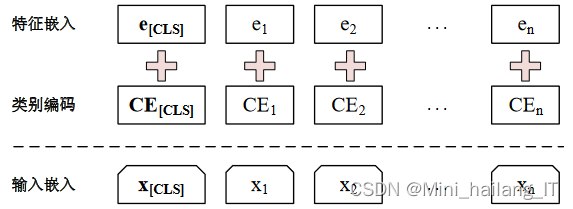
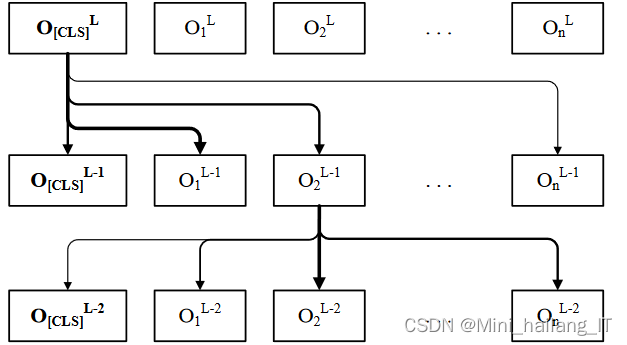
编码器层使用基于自注意力机制的Transformer编码器来处理从嵌入层中得到的社交上下文特征嵌入。这一层的目标是通过自注意力机制捕捉社交上下文特征之间的相互关系,并选择出对虚假新闻检测有利的关键特征。在编码器的每一层中,特征表示𝑜𝑖𝐿−2与每个特征表示𝑜𝑗𝐿−2进行相似度计算,并使用Softmax函数得到特征表示之间的相似度得分。然后,根据得分对第𝐿−2层中的特征表示𝑜𝑗𝐿−2进行加权求和,得到一个带有全局社交上下文信息的特征表示𝑜𝑖𝐿−1。这个过程能够捕捉特征表示𝑜𝑖𝐿−2与其他特征表示之间的相互关系。利用多头注意力机制,社交上下文特征之间进行交互,而可学习的特殊向量能够从社交上下文特征中选择出对虚假新闻检测有利的关键特征。
数据集
由于网络上缺乏现有的合适数据集,我决定自己进行网络爬取,收集了大量虚假新闻的样本,从而创建了一个全新的数据集。这个数据集涵盖了各种虚假新闻的文本内容,包括误导性标题、不实的事实陈述和误导性的论证。通过网络爬取,我能够获取到广泛的来源和多样的虚假新闻样本,这将为我的虚假新闻检测研究提供更准确、可靠的数据。我相信这个自制的数据集将为虚假新闻检测领域的研究提供有力的支持,并促进该领域的发展。
数据集预处理工作主要包括社交上下文信息、文本内容和图片的处理。针对社交上下文信息,根据字段的类型进行不同的处理方式。连续变量字段根据相关性分组,将多个字段的值聚合为一个向量作为社交上下文特征;离散变量字段则使用独热编码,将每个字段单独作为一个社交上下文特征。对于文本内容,可能涉及清除噪声、分词、移除停用词等处理,以便后续使用。至于图片,可能需要进行图像解码、尺寸调整、特征提取等处理。通过这些预处理步骤,能够提取出有用的信息并为虚假新闻检测模型提供更准确、可靠的数据。
模型训练
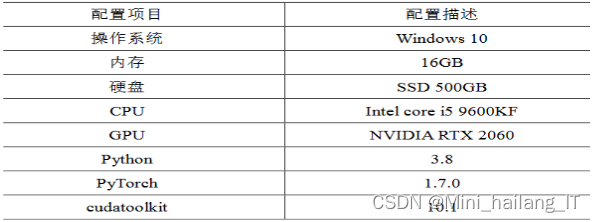
为了构建虚假新闻检测模型,本文使用了PyTorch 1.7.0机器学习库[65]。该机器学习库所采用的cudatoolkit版本是10.1。为了提高模型的学习效率,采用了一块NVIDIA RTX 2060型号的GPU进行模型训练。通过使用这样的GPU加速训练过程,可以提升模型训练的速度和效率,从而更快地得到模型的结果。这样的配置使得本文能够在相对较短的时间内完成模型训练,并为虚假新闻检测提供准确的结果。
在模型训练过程中,首先需要将准备好的数据集划分为训练集和验证集。训练集用于模型参数的更新和优化,而验证集则用于监控模型的性能并进行超参数调整。
训练过程采用反向传播算法,该算法通过计算损失函数在模型参数上的梯度,然后根据梯度对参数进行调整。通过不断迭代和更新参数,模型逐渐优化,使损失函数的值逐渐减小。
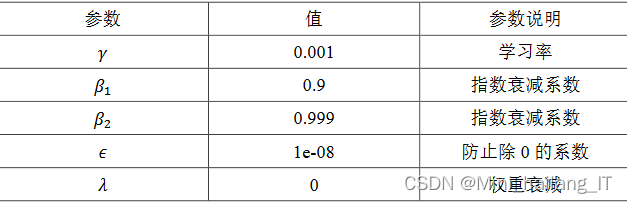
每个训练迭代中,模型根据训练集中的样本进行前向传播,计算模型的输出并与真实标签进行比较。然后,通过反向传播算法计算梯度,并使用优化算法(如随机梯度下降)对模型参数进行更新。此过程重复进行,直到训练集中的所有样本都被使用过一次,这被称为一个训练周期(epoch)。
for epoch in range(num_epochs):
# 模型训练阶段
model.train()
for inputs, labels in train_loader:
# 将输入数据和标签送入模型
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 清零梯度
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 更新模型参数
optimizer.step()在训练过程中,使用验证集来评估模型在未见过的数据上的性能。通过计算验证集上的损失值和其他评估指标,可以监控模型的泛化能力和性能,并进行超参数的调整。超参数包括学习率、批次大小、正则化参数等,它们的调整可以影响模型的性能和收敛速度。
model.eval()
with torch.no_grad():
total_correct = 0
total_samples = 0
for inputs, labels in valid_loader:
# 将输入数据送入模型
outputs = model(inputs)
# 计算预测结果
_, predicted = torch.max(outputs.data, 1)
# 统计正确预测的数量
total_correct += (predicted == labels).sum().item()
total_samples += labels.size(0)通常情况下,训练过程需要进行多个训练周期,直到模型达到预期的性能水平或收敛。在每个训练周期结束时,可以保存模型的参数以备后续使用。
class FakeNewsClassifier(nn.Module):
def __init__(self):
super(FakeNewsClassifier, self).__init__()
# 定义模型的层和参数
def forward(self, x):
# 定义前向传播过程
return x
# 创建模型实例
model = FakeNewsClassifier()
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 划分数据集为训练集和验证集
train_dataset = ...
valid_dataset = ...
# 定义训练参数
num_epochs = 10
batch_size = 32通过以上训练过程的迭代和调优,模型逐渐学习到数据集中的模式和特征,并能够准确地分类或预测新的样本。

















 3294
3294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









