 基于深度学习的微生物图像分类与目标检测毕设项目详解
基于深度学习的微生物图像分类与目标检测毕设项目详解





 本文介绍了如何通过机器视觉技术,尤其是基于ResNet50的改进和数据增强,进行微生物图像分类和目标检测的毕设项目。作者自行创建了数据集,采用迁移学习和注意力机制提升模型性能,同时展示了数据增强和模型训练的详细步骤。
本文介绍了如何通过机器视觉技术,尤其是基于ResNet50的改进和数据增强,进行微生物图像分类和目标检测的毕设项目。作者自行创建了数据集,采用迁移学习和注意力机制提升模型性能,同时展示了数据增强和模型训练的详细步骤。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器视觉的微生物图像分类
设计思路
一、课题背景
微生物是一类极小的生物体,包括细菌、真菌、病毒等。微生物在生态系统中起着重要的作用,对环境、农业、医学等领域都有着深远的影响。对微生物进行准确分类和鉴定对于研究微生物的特性、功能以及与环境、人类健康等的关联具有重要意义。传统的微生物分类和鉴定方法通常依赖于显微镜观察和人工判断,这种方式耗时、耗力,并且容易受主观因素影响,同时在大规模样本处理时存在一定的局限性。随着深度学习技术的发展,基于深度学习的微生物图像分类成为一种新的解决方案,具有更高的自动化程度和准确性。
二、数据集
2.1 数据集简历
由于网络上缺乏适用的微生物目标检测数据集,我决定自己进行野外采样和图像收集,创建一个全新的数据集。这个数据集包含了各种自然环境中的微生物目标照片,涵盖了不同种类和形态的微生物。通过现场采样和图像拍摄,我能够捕捉到真实的微生物样本和多样的生境条件,为我的研究提供更准确、可靠的数据基础。我相信这个自制的数据集将为微生物目标检测研究提供有力的支持,并为该领域的发展做出积极贡献。这一创新的数据集将为研究人员提供更好的训练和评估微生物目标检测算法的平台,推动微生物学和计算机视觉领域的交叉发展。
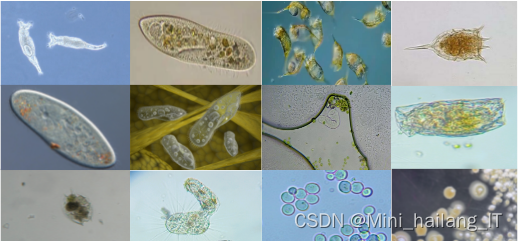
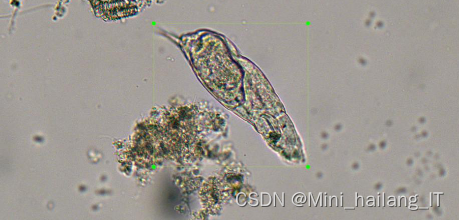
由于原始图像数据存在样本数量不均衡的问题,以及总体图像数量较少的限制,采用了图像数据增强技术来增加数据样本的多样性和数量。同时,为了进行目标微生物的标记,使用了LabelImg标注工具进行人工标注,通过绘制矩形框和输入类别名称来标记目标微生物,并生成相应的XML标签文件。这些标记数据将为目标检测模型的训练提供准确的类别和位置信息,以提高模型的性能和泛化能力。通过这些方法,本研究为微生物目标检测任务的数据集建立提供了有效的解决方案。
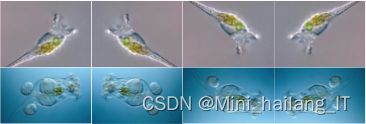
2.2 数据增强
原始图像数据集中存在样本数量不均衡的问题,整个数据集中图像数量只有700张,这对于深度学习网络的训练来说是远远不够的,可能导致模型的泛化能力和鲁棒性差。为了解决这些问题,采用了图像数据增强技术。通过角度翻转、亮度变换、添加高斯噪声、平移和旋转等方式对原始图像数据集进行增强处理。这样做可以在一定程度上弥补数据集样本不足的问题,使六类图像数量分布更均匀,并减小模型过拟合的概率。通过大量样本的训练,网络的泛化能力将更强,能够更好地适应实际应用场景。
相关代码示例:
import torch
import torchvision.transforms as transforms
# 定义图像数据增强的transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ColorJitter(brightness=0.2), # 亮度变换
transforms.GaussianBlur(kernel_size=3), # 添加高斯模糊
transforms.RandomAffine(degrees=15, translate=(0.1, 0.1), scale=(0.9, 1.1)), # 平移和旋转
transforms.ToTensor() # 转换为Tensor
])
# 加载原始图像数据集
dataset = MyDataset(image_paths, labels)
# 应用数据增强的transforms
augmented_dataset = AugmentedDataset(dataset, transform=transform)
# 创建数据加载器
dataloader = torch.utils.data.DataLoader(augmented_dataset, batch_size=16, shuffle=True)
# 在训练过程中使用数据加载器进行训练
for epoch in range(total_epochs):
for images, labels in dataloader:
# 训练代码...三、算法实现
3.1 微生物图像分类
对具有较深网络层数的ResNet50模型进行了改进,通过引入迁移学习方法和注意力机制模块来优化网络的结构和训练过程。这些改进旨在解决训练不稳定和分类准确率提升的问题。迁移学习利用预训练模型参数和知识,减少训练时间和数据需求,并提高模型的泛化能力。注意力机制模块使模型更加关注重要的特征和区域,提升分类准确性。通过这些改进,可以进一步提高ResNet50模型的分类效果,使其更稳定,并获得更高的准确率。这将为计算机视觉和深度学习领域的研究和应用提供更好的工具和方法。
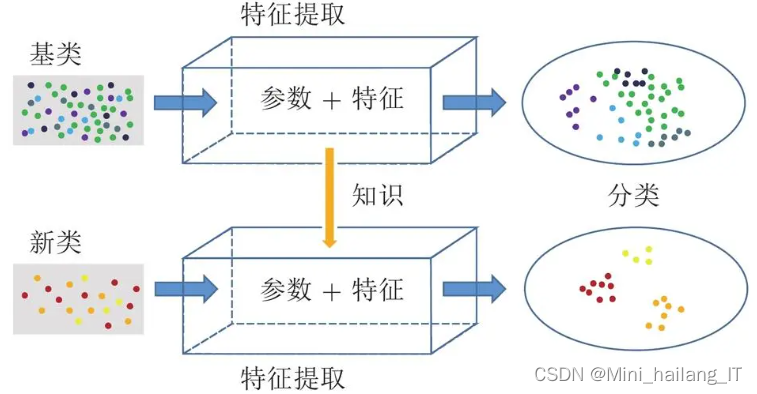
相对于AlexNet和VGGNet16在分类模块中采用了三层全连接层,ResNet50模型中只有一层全连接层,并使用全局平均池化层替代了两层全连接层。这样的设计减少了网络参数计算量,并获得了良好的性能。研究表明,在迁移学习中,全连接层可以充当"防火墙"的作用,特别是当目标领域的图像与源领域的图像存在较大差异时。考虑到微生物图像数据集与ImageNet数据集存在较大差异,为了获得更好的迁移学习效果,ResNet50的分类模块增加了一层全连接层。同时,还添加了批归一化(BN)层,以提高网络训练和收敛速度,并防止过拟合。注意力机制模块被添加在ResNet50的特征提取层输出的特征图后面,用于引入注意力权重。
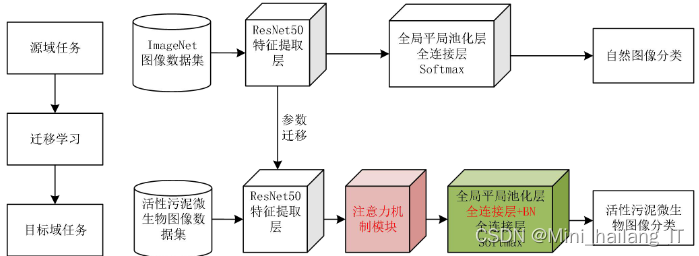
3.2 目标检测模型
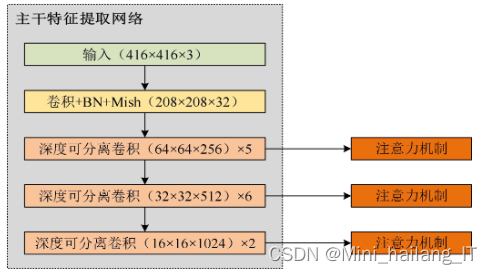
针对改进后的主干特征提取网络的特征提取能力进行了增强。通过在第5个、第11个和第13个深度可分离卷积层的输出特征图后面添加注意力机制模块,如SE和CBAM,以增强特征图中的重要信息。这样的设计能够自适应地调整特征图的权重,使模型更加关注具有较高判别能力的特征,从而提升特征提取能力。通过这种方式,模型在图像分类任务中表现出更好的性能,并在各种实际应用中具有更高的实用性。
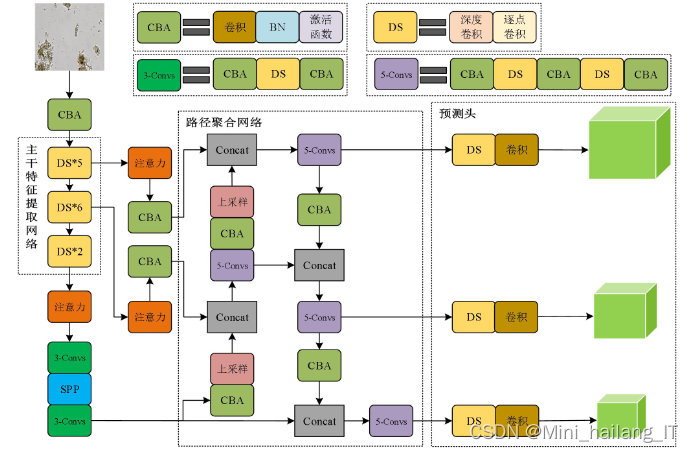
为了减少参数量和训练计算量,模型采用了MobileNet网络替换了CSPDarkNet主干网络,并将YOLOv4模型中的所有普通3×3卷积替换为深度可分离卷积。在特征提取后,通过添加注意力机制对特征进行加权,然后使用PANet特征融合网络模块将低层和高层特征图进行融合。最后,通过一系列卷积操作和全连接层进行目标分类和边框回归定位。这个改进的模型旨在提高污水活性污泥微生物目标检测的速度,并进一步提高检测的精确度。
3.3 模型训练
采用迁移学习的方式进行网络训练。首先,在自制数据集上对模型进行预训练,得到预训练网络的权重参数。然后,将预训练权重加载到模型中,并使用本文提供的活性污泥微生物目标检测数据集进行训练。
训练过程中,设置了总共100个迭代次数(epoch)。前50个epoch中,冻结特征提取层,只训练未冻结的网络部分,学习率设置为0.001,批量大小为16。在前50个epoch训练完成后,解冻特征提取层,训练整个网络的所有参数,学习率设置为0.0001,批量大小设置为8。这样的设置可以先让模型在固定的特征提取层上进行学习,然后逐渐调整整个网络的参数。
训练算法的流程如下:
1. 读取网络模型。
2. 使用预训练权重加载网络参数。
3. 读取图像数据集,并进行预处理,如Mosaic数据增强和调整图像尺寸为416×416。
4. 设置训练参数:
- 设定总迭代次数为100。
- 在前50个epoch中,冻结特征提取层,只训练未冻结的网络部分。
- 学习率设置为0.001,批量大小设置为16。
5. 开始训练网络,进行迭代优化:
- 对于每个epoch:
- 使用训练数据进行前向传播,计算损失,并进行反向传播更新参数。
- 记录并保存训练集的损失。
- 在每个epoch结束后,计算验证集的损失。
- 检查验证集损失,如果不再显著减小或出现过拟合,停止训练。
6. 训练完成后,保存最优的网络权重文件。相关代码示例:
import torch
import torchvision
from torch.utils.data import DataLoader
# 读取网络模型
model = torchvision.models.resnet18(pretrained=False)
# 使用预训练权重加载网络参数
pretrained_weights = torch.load("pretrained_weights.pth")
model.load_state_dict(pretrained_weights)
# 读取图像数据集并进行预处理
dataset = MyDataset(image_paths, annotations, transform=preprocessing_transform)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# 设置训练参数
total_epochs = 100
learning_rate_1 = 0.001
learning_rate_2 = 0.0001
# 冻结特征提取层,只训练未冻结的网络部分
for param in model.features.parameters():
param.requires_grad = False
# 定义优化器和损失函数
optimizer = torch.optim.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=learning_rate_1)
criterion = torch.nn.CrossEntropyLoss()
# 开始训练网络
for epoch in range(total_epochs):
for images, labels in dataloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 在每个epoch结束后进行验证集损失的计算
validation_loss = calculate_validation_loss(model, validation_dataset)
# 判断是否停止训练
if validation_loss no longer decreases or overfitting occurs:
break
# 解冻特征提取层,训练整个网络的所有参数
for param in model.parameters():
param.requires_grad = True
# 调整学习率和批量大小
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate_2)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 3294
3294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









