




 本文介绍了基于深度学习的微博谣言检测系统,包括课题背景、DSACNN模型的理论原理,以及注意力机制在模型中的应用。模型利用预训练的情感词向量和注意力机制提高了模型的性能,尤其是在小数据集上的表现。评估指标包括准确率和宏平均F1值。
本文介绍了基于深度学习的微博谣言检测系统,包括课题背景、DSACNN模型的理论原理,以及注意力机制在模型中的应用。模型利用预训练的情感词向量和注意力机制提高了模型的性能,尤其是在小数据集上的表现。评估指标包括准确率和宏平均F1值。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的微博谣言检测系统
设计思路
一、课题背景与意义
微博谣言早期检测系统的背景和意义源于社交媒体平台上谣言的广泛传播和对社会的潜在危害。随着社交媒体的普及和信息传播的快速性,谣言可以在短时间内迅速扩散,对公众产生负面影响,包括误导和恐慌等。因此,建立谣言早期检测系统具有重要意义。
二、算法理论原理
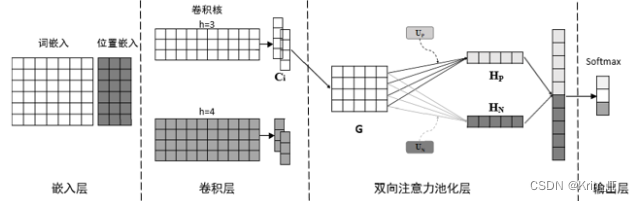
DSA-CNN是一种基于卷积神经网络的模型,结合了双向情感词注意力机制,共分为四层结构:嵌入层、卷积层、注意力池化层和输出层。
- 嵌入层:将句子转换为词向量矩阵和位置向量矩阵。这一层的目的是将文本表示为向量形式,以便后续的卷积操作。
- 卷积层:通过不同尺寸的卷积核提取局部特征,生成特征图。卷积层能够捕捉文本中的局部信息,对不同大小的特征进行提取。
- 注意力池化层:将注意力机制用于对CNN模型池化层的改进,并基于训练得到的双向情感词向量,采用注意力机制获得卷积特征图中重要的正向和负向情感特征。通过注意力机制,模型可以关注句子中与情感相关的重要信息。
- 输出层:使用Softmax函数获得分类结果。将经过注意力池化层处理后的特征进行拼接,然后经过Softmax函数进行分类概率的计算,得到最终的分类结果。
相关代码示例:
model = DSA_CNN_Model()
# 定义损失函数和优化器
criterion = CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(num_epochs):
# 前向传播
output = model.forward(input_data)
# 计算损失
loss = criterion(output, target_labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出训练信息
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
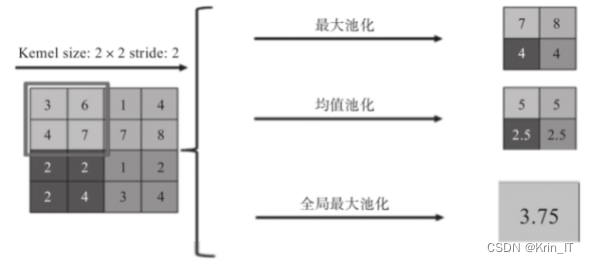
在文本分类中,传统的CNN池化层常用的方法是最大池化和平均池化。然而,最大池化方法只关注最显著的影响因素,忽略了其他因素的影响,而平均池化方法对所有信息进行同等处理,无法区分不同情感特征词的重要性。这些池化方法都有可能丢失上下文中的信息,对语义特征的提取产生影响。
为了更有效地提取文本特征,注意力机制被引入到CNN池化层的改进中。注意力机制可以计算一组特征中的不同重要程度,并根据查询向量给予更大的权重。将注意力机制应用于CNN池化层改进中,可以对不同影响的特征进行有效区分。相比于最大池化,基于注意力的池化方法包含了更多文本信息。
相关代码示例:
import torch
import torch.nn as nn
class AttentionPooling(nn.Module):
def __init__(self, input_size, query_size):
super(AttentionPooling, self).__init__()
self.linear = nn.Linear(input_size, query_size)
self.softmax = nn.Softmax(dim=1)
def forward(self, features):
# features: 输入的特征图,形状为(batch_size, num_features, feature_size)
# 计算查询向量
query = self.linear(features) # (batch_size, num_features, query_size)
# 计算注意力分数
attention_scores = self.softmax(query) # (batch_size, num_features, query_size)
# 加权池化
pooled_features = torch.bmm(attention_scores.transpose(1, 2), features) # (batch_size, query_size, feature_size)
# 返回注意力池化后的特征
return pooled_features在常见的文本分类模型中,注意力机制的查询向量通常与网络权重向量类似,随机初始化并进行训练。然而,这种方法受到初始化效果的影响,并增加了过拟合的风险。提出了双向情感词向量的概念,通过情感词典的构造和训练得到,综合考虑了积极和消极情感词的总体情感信息,并以词向量的形式表示。将双向情感词向量作为注意力机制的查询向量,可以在向量空间中与情感特征有较高的相似度,从而在短文本中从积极和消极情感两个方向挖掘更多信息,减轻了随机初始化的影响,防止过拟合。
情感词向量的训练是一个非监督学习过程,需要使用大量包含情感信息的文本语料。为了获取这些语料,可以使用爬虫技术在网络上爬取包含情感的文本。通常,电商平台和社交媒体平台是包含大量情感语料的良好来源,因此可以选择这些平台进行数据爬取。
获取到的情感语料库需要进行预处理。一种常用的预处理方法是使用分词工具,例如jieba库,对文本进行分词操作。在此过程中,还需要将融合情感词典添加到jieba的自定义词典中,以确保能够准确地划分情感词。对于每一条语料,如果句子中存在情感词典中的积极情感词,则将其替换为"<pos>"标记;同样地,将所有消极情感词替换为"<neg>"标记。
相关代码示例:
import jieba
# 加载自定义词典
jieba.load_userdict('emotion_dict.txt')
# 情感词典
emotion_dict = {
'积极情感词1': '<pos>',
'积极情感词2': '<pos>',
'消极情感词1': '<neg>',
'消极情感词2': '<neg>'
}
# 定义文本预处理函数
def preprocess_text(text):
# 分词
words = jieba.lcut(text)
# 替换情感词
for i, word in enumerate(words):
if word in emotion_dict:
words[i] = emotion_dict[word]
# 拼接处理后的文本
processed_text = ' '.join(words)
return processed_textWord2Vec是一种神经网络算法,用于将文本词汇转换为向量表示。它包括CBOW和Skip-gram两种模型,CBOW根据临近词预测中心词,而Skip-gram根据中心词预测临近词。通过训练神经网络,Word2Vec可以生成高维空间中的词向量,将文本信息转化为可计算的向量形式,以便进行后续的文本分析和语义相关性计算等任务。
相关代码示例:
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
# 读取语料文件
corpus_file = 'corpus.txt'
# 训练Word2Vec模型
model = Word2Vec(sentences=LineSentence(corpus_file),
sg=1, # 使用Skip-gram模型
size=100, # 特征向量维度
window=5, # 上下文窗口大小
min_count=5, # 词频阈值,低于该阈值的词将被忽略
workers=4) # 并行训练的线程数
# 保存训练好的模型
model.save('word2vec.model')
# 加载已保存的模型
model = Word2Vec.load('word2vec.model')
# 获取词向量
word_vector = model.wv['word']
# 计算词语之间的相似度
similarity = model.wv.similarity('word1', 'word2')
# 寻找与目标词最相似的词语
similar_words = model.wv.most_similar('target_word', topn=5)
# 获取模型中的所有词汇
vocabulary = model.wv.vocab三、检测的实现
谣言数据来源于微博社区管理中心。微博社区管理中心是微博平台专门用于维护平台网络秩序和治理违规行为的官方网站,接受并处理网民的举报,并进行公开审核,受到大众监督。在微博平台上,所有被举报处理的微博谣言都会被公开在微博社区管理中心的不实信息中。谣言数据取自于处于公示阶段的近三年数据,共爬取了其中已发布谣言的原微博4000多条。为了保证所收集的谣言数据有一定的关注度,剔除了其中转发评论过少的数据和重复数据,最终剩下3850条谣言数据。
评价指标选择了准确率(Accuracy)和宏平均F1值(Macro F1)。准确率和宏平均F1值是根据真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)进行计算得出的。简而言之,准确率衡量了模型正确分类的比例,宏平均F1值综合了模型在各个类别上的精确度和召回率。
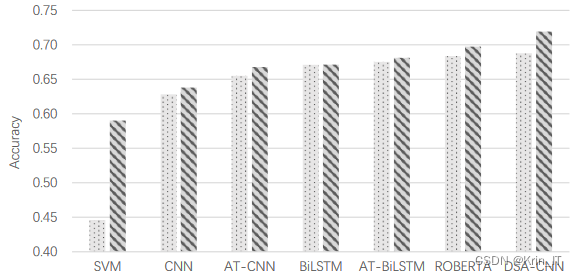
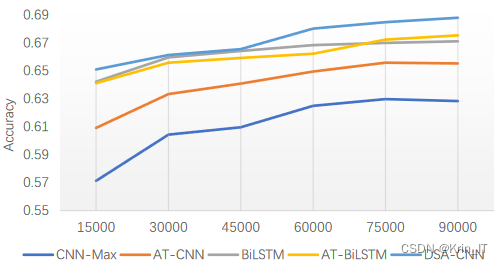
改进后的模型模型在实验中始终表现最好,无论是在小数据集还是大数据集上都具有良好的学习能力。在小数据集上,DSA-CNN的学习能力与两个LSTM模型基本相当,优于其他CNN模型,这表明通过预训练的情感词向量和注意力机制使得CNN在小数据集上也能提取一定的特征。随着数据集的增大,DSA-CNN模型的准确率也逐步提升,并获得一定的改善,这说明更大的数据量使得网络能够学习到更多的知识。
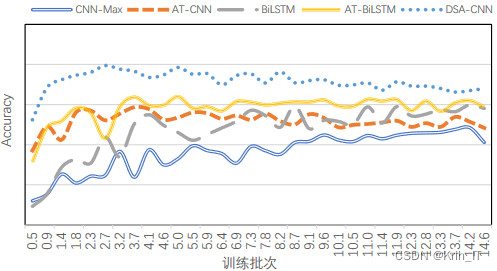
改进后的模型在池化层采用预训练的情感词向量作为查询向量,减少了随机初始化的影响,使得收敛速度相比AT-CNN进一步提升。在实际操作中可以提前结束神经网络的训练过程。总的来说,训练速度是评价模型质量的重要因素之一,注意力机制和预训练的情感词向量能够显著提高模型的训练速度和收敛性能。
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









