




01
什么是电商网页抓取?
电商网页抓取是从亚马逊、阿里巴巴、eBay,淘宝,京东,微店,1688等在线零售平台提取数据的过程。虽然可以手动复制数据,但通常使用自动化工具或脚本完成。
从电商网站提取的数据可帮助:
-
分析产品价格波动
-
跟踪评论评分
-
识别市场趋势
-
研究竞争对手
这些洞察支持明智决策和战略规划。
注意:电商数据抓取工具通常称为电商抓取器。
02
电商抓取工具的类型
以下是常见的电商抓取工具类型:
-
自定义脚本:使用Python或JavaScript等编程语言编写的定制脚本。
-
无代码抓取工具:无需编程即可提取数据的工具,适合非技术人员。
-
网页抓取API:通过接口以编程方式提供结构化数据,支持实时或大规模抓取。
-
浏览器扩展:直接在电商网页上收集数据的浏览器插件。
本文将重点介绍如何构建自定义电商抓取机器人。
03
从电商网站可以抓取的数据
电商抓取器通常可以提取以下数据:
产品详情:名称、描述、规格、图片
价格信息:当前价格、折扣、历史价格趋势
客户评论:评分、评论内容、反馈
分类与标签:产品分类与标签
卖家信息:名称、评分、联系方式
物流详情:运费、配送时间、政策
库存状态:库存量、缺货通知
营销数据:产品列表、定价策略、促销活动
现在,学习如何用Python构建电商抓取器!
04
如何构建电商抓取器
手动构建电商抓取器前,需熟悉目标网站结构。使用开发者工具(DevTools)检查目标页面:
-
理解页面结构
-
确定可提取的数据
-
选择抓取库
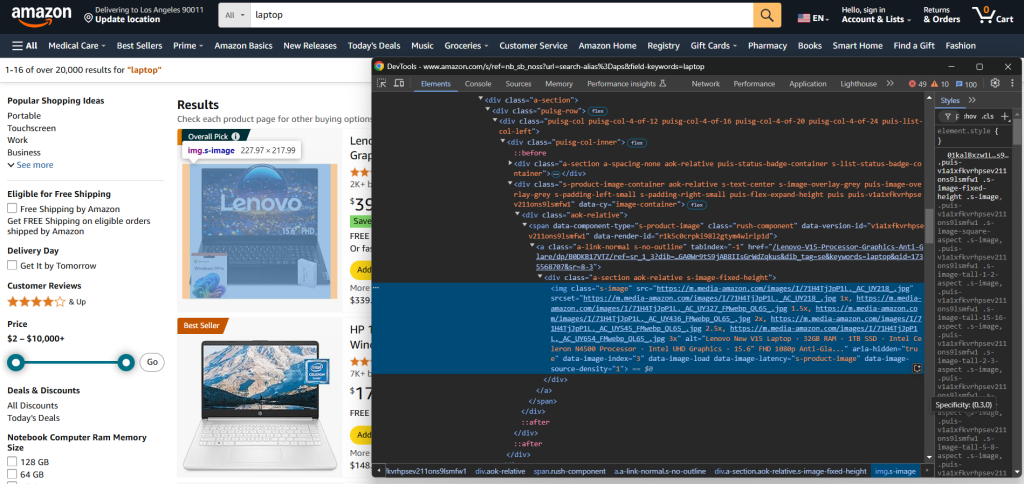
对于简单网站,以下Python库足够使用:
Requests:发送HTTP请求,获取网页原始HTML。
Beautiful Soup:解析HTML/XML文档,简化数据提取。
安装命令:
pip install requests beautifulsoup4
对于动态加载或依赖JavaScript渲染的网站(如亚马逊),需使用Selenium:
pip install selenium
抓取流程如下:
连接目标网站:使用Requests或Selenium获取并解析HTML。
选择目标元素:通过CSS选择器或XPath定位元素(如产品图片、价格)。
提取数据:从HTML元素中提取信息。
清洗数据:去除无关内容或格式化数据。
导出数据:将数据保存为JSON或CSV格式。

















 2209
2209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









