



在大模型“群雄争霸”的今天,一边是OpenAI推出的GPT-4.5,另一边是Anthropic发布的Claude4,这两个模型几乎成了“你用哪个我也得试试”的双雄。但问题是:到底谁更强?该怎么选?
如果你也曾在开发选型、内容生成、智能客服、代码助手等实际场景中纠结过——本文将带你深入剖析两者异同,并顺带分享一个能真正解决“到底选谁”的实用工具。
一、GPT-4.5vs Claude4:到底差在哪?哪家强?
让我们从几个核心维度来看看它们的“真面目”:
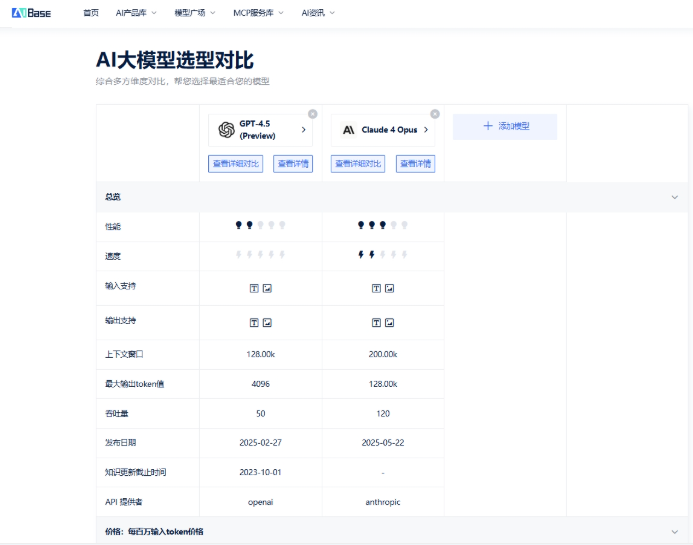
1. ⏱响应速度 & 处理效率
-
GPT-4.5:推理速度较GPT-4显著提升,尤其在API调用中表现更为敏捷,适合实时对话和多轮任务处理。
-
Claude4:以“稳”见长,响应内容往往更完整,但在速度上稍逊一筹。
2. 🧠上下文长度 & 记忆力
-
GPT-4.5:官方上下文长度为128k tokens,在理解复杂对话和长文档处理方面表现不俗。
-
Claude4:主打200k+上下文,在长文档总结、法律分析、大型PDF处理等任务中有天然优势。
3. 📚知识丰富度
-
GPT-4.5拥有更强大的训练数据库,内容更丰富、表达更自然,适合创作、写作、编剧等工作。
-
Claude4更注重安全性与对齐性,尤其在敏感领域的回答更为稳健,适合企业部署。
4. 🤖代码能力 & 技术推理
-
GPT-4.5:编程能力依然遥遥领先,尤其在Python、JS等语言领域表现出色。
-
Claude4:在复杂逻辑建模上进步明显,但在代码实战中稍逊GPT。
5. 🔐数据隐私 & 企业适配
-
Claude4强调可控性与可解释性,更适合对数据安全要求高的企业环境。
-
GPT-4.5则在插件与Agent生态上更为开放,适合快速试验、生成类应用。
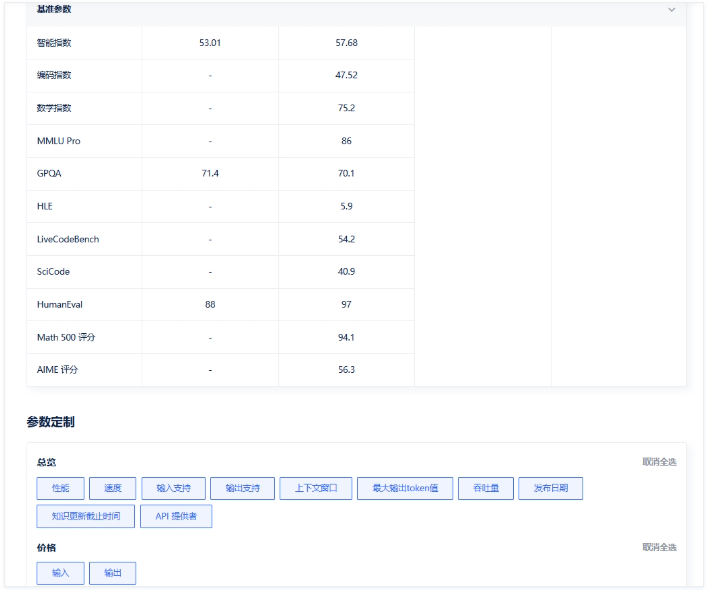
二、到底该怎么选?手动对比效率太低了……
面对如此多维度的差异,不少人开始“表格+对照+爬文”三连,但这样的手动方式不仅信息滞后,还容易忽视实际场景匹配。
比如:
-
你想做一个AI客服,Claude的“稳健+上下文记忆”可能更合适;
-
你是内容创作者或开发者,GPT-4.5的“速度+表达+生态”可能更香。
那么有没有一个地方,可以一键对比、快速上手、按需筛选模型?
三、推荐一个真正实用的神器:AIbase的大模型选型对比工具
👉 访问地址:https://model.aibase.com/zh/compar
这个工具不是简单的“模型列表”,而是一个动态、交互式的AI大模型对比平台,适合开发者、产品经理、AI爱好者快速做出选型判断。
✅ 核心亮点如下:
|
功能特色 |
描述 |
|---|---|
|
📊 多维参数对比 |
模型能力、上下文长度、接口价格、API调用限制等关键指标一目了然 |
|
📍 场景化推荐 |
可根据“写作/代码/客服/总结”等不同使用场景筛选适合模型 |
|
🧪 体验入口直通 |
每个模型都配有快速试用链接,点开就能体验 |
|
🆚 实时对比更新 |
支持Claude、GPT、Gemini、Moonshot、智谱等主流模型对比,保持最新版本数据 |
四、结语:别再纠结“哪家强”,看场景选才是真功夫!
无论你是初创团队、AI开发者、企业产品经理还是普通用户,面对GPT-4.5与Claude4,没有“唯一正确”的答案。
真正聪明的做法是:
让工具帮你快速理解差异,用场景倒推选型逻辑,少走弯路。
而像 AIbase 这样的一站式对比工具,它解决的是你在AI产品选型中真正的“决策焦虑”。
📎附录资源
-
✅ GPT-4.5vs Claude4全参数对比工具:
👉 https://model.aibase.com/zh/compar
-
📄 Claude4官方说明:https://www.anthropic.com/news/claude-4
-
📄 GPT-4.5说明文档:https://platform.openai.com/docs/models/gpt-4
如需获取更多大模型横评、AI应用教程、API调用实测分析,欢迎关注我们的后续更新,我们将持续用“实用+不忽悠”的方式帮你站稳AI时代的风口。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









