



目录
什么是Eignface?
Eigenfaces就是特征脸的意思,是一种从主成分分析(Principal Component Analysis,PCA)中导出的人脸识别和描述技术。特征脸方法的主要思路就是将输入的人脸图像看作一个个矩阵,通过在人脸空间中一组正交向量,并选择最重要的正交向量,作为“主成分”来描述原来的人脸空间。
特征脸训练与识别原理图
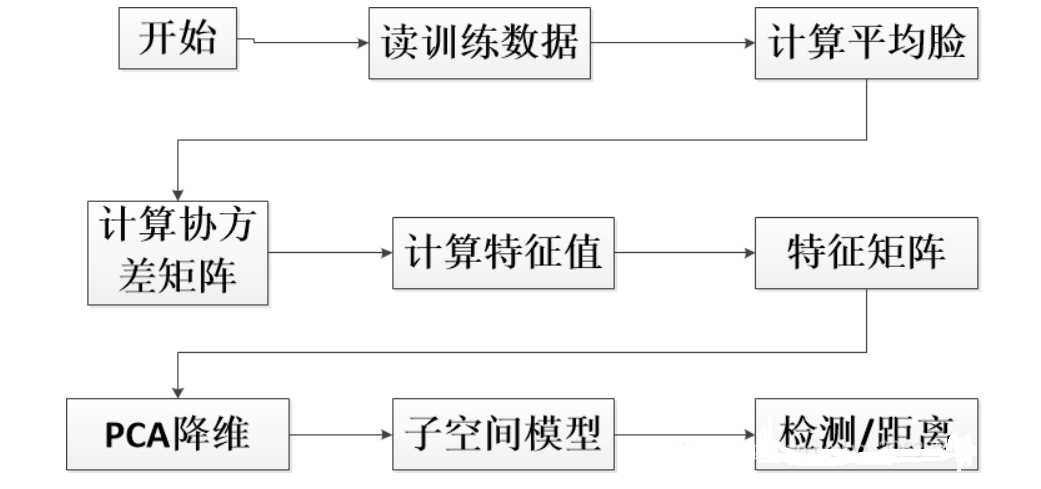
PCA主要过程
在很多应用中需要对大量数据进行分析计算并寻找其内在的规律,但是数据量巨大造成了问题分析的复杂性,因此我们需要一些合理的方法来减少分析的数据和变量同时尽量不破坏数据之间的关联性。于是这就有了主成分分析方法,PCA作用:
- 数据降维。减少变量个数;确保变量独立;提供一个合理的框架解释。
- 去除噪声,发现数据背后的固有模式。
PCA的主要过程:
- 特征中心化:将每一维的数据(矩阵A)都减去该维的均值,使得变换后(矩阵B)每一维均值为0;
- 计算变换后矩阵B的协方差矩阵C;
- 计算协方差矩阵C的特征值和特征向量;
- 选取大的特征值对应的特征向量作为”主成分”,并构成新的数据集
特征脸方法
特征脸方法就是将PCA方法应用到人脸识别中,将人脸图像看成是原始数据集,使用PCA方法对其进行处理和降维,得到“主成分”——即特征脸,然后每个人脸都可以用特征脸的组合进行表示。这种方法的核心思路是认为同一类事物必然存在相同特性(主成分),通过将同一目标(人脸图像)的特性寻在出来,就可以用来区分不同的事物了。人脸识别嘛,就是一个分类的问题,将不同的人脸区分开来。
代码实现
import cv2
import numpy as np
# 创建一个空列表用于存储图像
images = []
# 使用cv2.imread()函数读取名为'dingzhen3.png'的图像,并将其转换为灰度图像格式
image = cv2.imread('dingzhen3.png')
# 为图像列表添加四个图像,这些图像都预先读入并且大小调整为500x500像素,来源于不同的文件
images.append(cv2.resize(cv2.imread('agou1.png', 0), (500, 500)))
images.append(cv2.resize(cv2.imread('agou2.png', 0), (500, 500)))
images.append(cv2.resize(cv2.imread('dingzhen1.png', 0), (500, 500)))
images.append(cv2.resize(cv2.imread('dingzhen2.png', 0), (500, 500)))
# 创建一个标签列表,对应于之前添加到图像列表中的四个图像
labels = [0, 0, 1, 1]
# 读取名为'dingzhen3.png'的图像,并将其转换为灰度图像格式
predict_image = cv2.imread('dingzhen3.png', 0)
# 将预测图像的大小调整为500x500像素
resize_image = cv2.resize(predict_image, (500, 500))
# 创建一个EigenFace人脸特征识别器对象,通过训练图像和对应的标签来训练该识别器
recongnzer = cv2.face.EigenFaceRecognizer_create() # 人脸特征识别器
recongnzer.train(images, np.array(labels))
# 使用训练好的人脸特征识别器对调整大小后的预测图像进行人脸识别,返回识别到的标签和对应的置信度
label, confidence = recongnzer.predict(resize_image)
# 打印识别到的标签
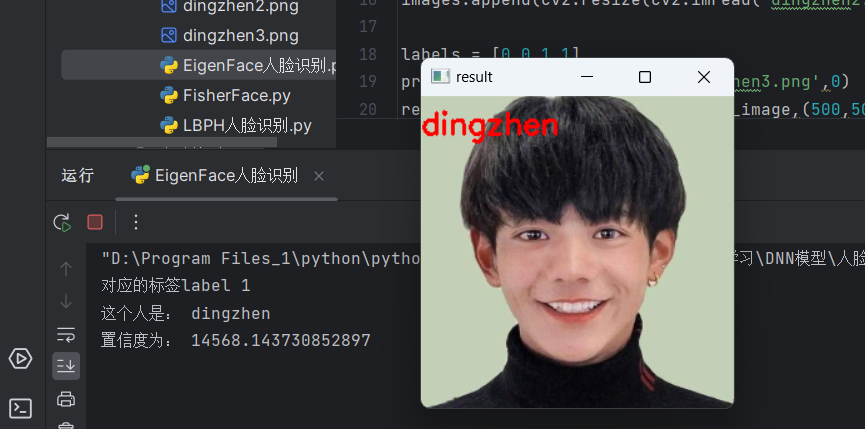
print('对应的标签label:', label)
# 创建一个字典,将标签映射到对应的人名
name = {0: 'agou', 1: 'dingzhen'}
# 打印识别到的人名
print('这个人是:', name[label])
# 打印置信度,即识别结果的可信程度
print('置信度为:', confidence)
# 创建一个字体对象,用于之后的文本绘制操作
font = cv2.FONT_HERSHEY_SIMPLEX
# 在图像上绘制识别人名的文本,位置为(0,30),字体大小为原始大小乘以0.8,颜色为红色,线宽为2
cv2.putText(image, name[label], (0, 30), font, 0.8, (0, 0, 255), 2)
cv2.imshow('result', image)
# 等待用户按键操作,如果用户按下任意键则退出等待,否则会一直等待下去
cv2.waitKey(0)
# 销毁所有创建的窗口对象,包括显示图像结果的窗口和所有的图像窗口
cv2.destroyAllWindows()运行结果:

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









