



 本文详细解释了深度学习中优化器(optimizer)的三个关键方法:optimizer.zero_grad()清除梯度,loss.backward()计算梯度并反向传播,optimizer.step()根据梯度更新参数。这些步骤构成模型训练的基本循环,对理解模型性能至关重要。
本文详细解释了深度学习中优化器(optimizer)的三个关键方法:optimizer.zero_grad()清除梯度,loss.backward()计算梯度并反向传播,optimizer.step()根据梯度更新参数。这些步骤构成模型训练的基本循环,对理解模型性能至关重要。
目录
本文重点讨论深度学习中的优化器的部分使用
一、概述
在深度学习和机器学习领域中,"optimizer"(优化器)是指一种用于优化模型参数以最小化损失函数的算法或工具。优化器的主要任务是更新模型的权重或参数,使其逐渐收敛到损失函数的最小值或局部最小值,从而提高模型的性能。
优化器在训练神经网络等机器学习模型时非常重要,因为模型参数的更新通常依赖于损失函数的梯度。
二、代码实际应用及作用解析
def train(dataloader,model,loss_fn,optimizer):
model.train()
batch_size_sum = 1
for x,y in dataloader:
x,y = x.to(device),y.to(device)
pred = model.forward(x)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value = loss.item()
print(f"loss:{loss_value:>7f} [number:{batch_size_sum}]")
batch_size_sum += 1上述代码为函数在实际案例中应用,下列将以具体使用进行分析
1、optimizer.zero_grad()
清空模型参数的梯度,以确保每次迭代的梯度计算都是基于当前小批量数据的,而不会受之前迭代的影响。这是为了避免在优化过程中梯度的不正确累积。
import torch
x = torch.tensor([1., 1.], requires_grad=True)
y = 200 * x
# 定义损失
loss = y.sum()
print("x:", x)
print("y:", y)
print("loss:", loss)
print("反向传播前, 参数的梯度为: ", x.grad)
# 进行反向传播
loss.backward()
print("反向传播后, 参数的梯度为: ", x.grad)
# 定义优化器
optim = torch.optim.Adam([x], lr=0.001) # Adam, lr = 0.001
print("更新参数前, x为: ", x)
optim.step()
print("更新参数后, x为: ", x)
# 再进行一次网络运算
y = 100 * x
# 定义损失
loss = y.sum()
# 进行optimizer.zero_grad()
optim.zero_grad()
loss.backward() # 计算梯度grad, 更新 x*grad
print("进行optimizer.zero_grad(), 参数的梯度为: ", x.grad)下列为结果展示:
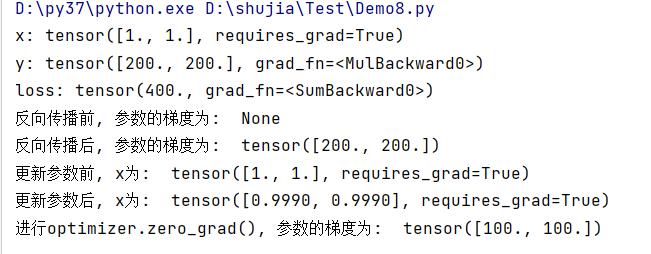
该函数可以清楚之前累计的梯度值,若不使用,则梯度为tensor([200,200])
2、loss.backward()
根据当前的损失值(通常是一个标量)计算模型参数的梯度。它会从损失开始,然后通过模型的各个层反向传播梯度,最终计算出每个参数相对于损失的梯度。这些梯度将被用于后续的参数更新,以减小损失。
3、optimizer.step()
根据优化器的配置和计算得到的梯度来更新模型参数。具体地,它执行了参数更新的操作,通常是将当前参数减去学习率乘以参数的梯度。学习率是一个超参数,用于控制参数更新的步长大小。通过不断地执行 optimizer.step(),模型的参数将逐渐调整,以减小损失函数。
下列为loss.backward() 和 optimizer.step()的具体用法:
import torch
x = torch.tensor([1., 2.], requires_grad=True)
y = 100 * x
loss = y.sum()
print("x:", x)
print("y:", y)
print("loss:", loss)
print("反向传播前, 参数的梯度为: ", x.grad)
loss.backward()
print("反向传播后, 参数的梯度为: ", x.grad)
optim = torch.optim.Adam([x], lr=0.001)
print("更新参数前, x为: ", x)
optim.step()
print("更新参数后, x为: ", x)结果展示:
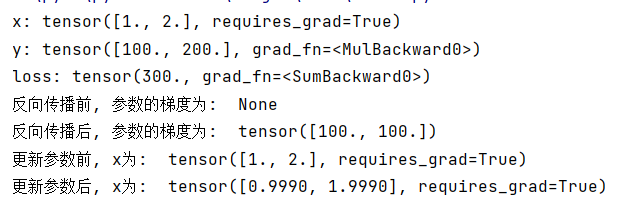
三、总结
这三行代码通常组成了深度学习模型训练的核心循环。在整个训练过程中,它们会被重复执行多次,模型的参数会根据损失函数的梯度逐渐调整,以最小化损失并提高模型性能。学习如何正确地使用这三行代码是深度学习入门的重要一步,因为它们构成了模型训练的基础。同时,理解这些代码背后的原理也有助于更好地调整超参数和选择合适的优化器,以改进模型的训练效果。

















 324
324





 到【灌水乐园】发言
到【灌水乐园】发言







