



目录
为什么要剪枝
决策树是充分考虑了所有的数据点而生成的复杂树,它在学习的过程中为了尽可能的正确的分类训练样本,不停地对结点进行划分, 如果树足够大,每个叶子节点就剩下了一个数据。那么,这就会造成模型在训练集上的拟合效果很好,但是泛化能力很差,对新样本的适应能力不足。而剪枝能够通过删除一些无关紧要的分支,来减小决策树的复杂度,从而提高算法的泛化能力。
如何剪枝?
1.预剪枝
预剪枝是决策树算法中的一种技术,它在构建决策树时,在树的生长过程中就对其进行一些裁剪,以避免过度拟合的情况发生。预剪枝技术通常有以下几种:
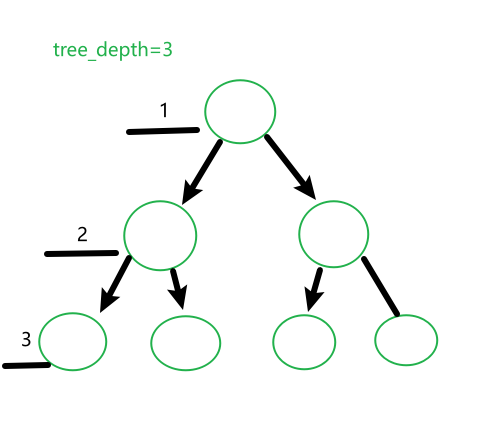
1.最大深度限制:限制树的深度,避免树过度深入。
假设我们限制树的深度最大为3,那么这个决策树再创建过程中,他的根节点不会超过3个
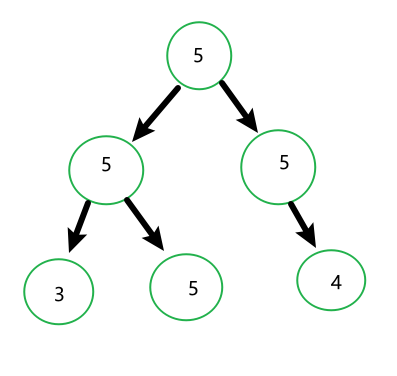
2.叶子节点最小样本数限制:限制叶子节点的最小样本数,以避免过度拟合。
我们设置min_sample_leaf=5(叶子节点样本数为5),那么每个叶子包含的样本最少为5个,如果样本数少于5,就不会再向下进行分支
3.信息增益阈值限制:设置阈值,当某个节点的信息增益小于阈值时,停止向下分裂。
信息增益计算可见ID3_决策树算法解析
总结:预剪枝技术在训练时可以降低模型的复杂度,从而减少过拟合的风险,但是如果预剪枝的设置不合理,则会影响决策树的精度,因此需要根据实际情况进行适当的调整。
2.后剪枝
后剪枝(post-pruning)是决策树剪枝的一种方法,它在构造决策树之后对决策树进行精简。后剪枝的基本思想是将决策树剪枝成一个较小的子树,以减少因过度拟合而产生的错误分类。
后剪枝的步骤包括:
-
从训练集中随机选择一部分数据用作验证集。
-
从根节点开始逐层遍历决策树,对每个节点进行以下操作:
- 计算对该节点进行剪枝后的验证集错误率。
- 计算不进行剪枝的验证集错误率。
- 如果进行剪枝后的错误率小于不进行剪枝的错误率,就将该节点剪枝,将其变为叶节点,并用该节点的众数作为叶节点的预测值。重复步骤2,直到所有节点都被遍历过一次
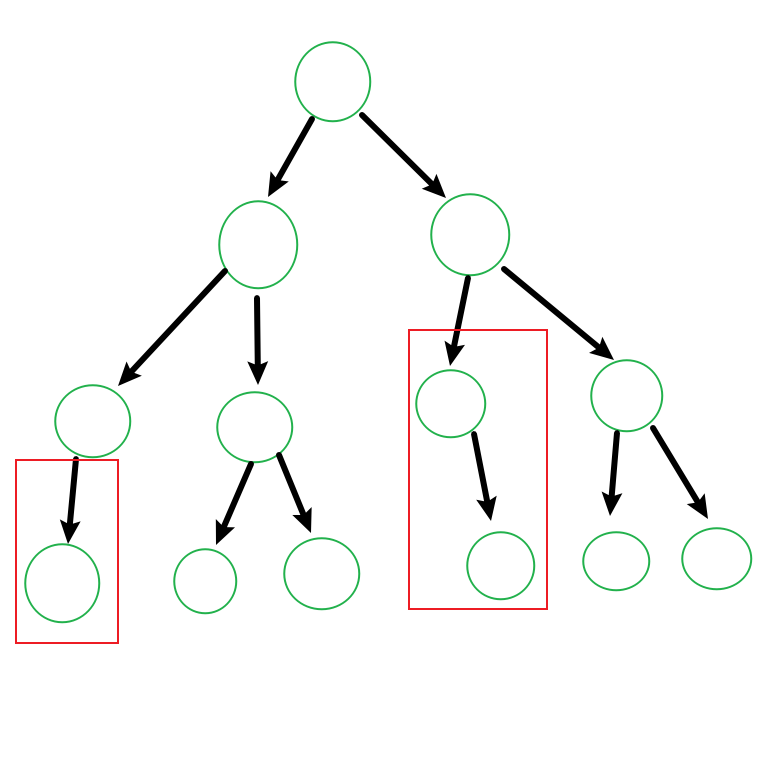
我们通过计算发现剪掉红色方框圈住的叶子后,会提高分类准确率,于是我们将其‘剪掉’
优点:不依赖于先验知识,可以提高决策树的泛化能力,避免过拟合。
缺点:需要对数据进行随机划分,增加了计算量和时间复杂度。

















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









