



 本文介绍了使用Python和scikit-learn库进行逻辑回归分析的步骤,包括数据预处理、模型构建、训练与测试,以及评估指标如准确率、召回率和F1-score的应用。
本文介绍了使用Python和scikit-learn库进行逻辑回归分析的步骤,包括数据预处理、模型构建、训练与测试,以及评估指标如准确率、召回率和F1-score的应用。
目录
一、准备阶段
步骤1.
用win+R打开控制台
步骤2.
使用pip命令
pip install pandas#使用pip下载pandas库
pip install scikit-learn#使用pip下载scikit-learn库二、案例分析
1.案例:
对银行的贷款风险用户识别
2.数据表:
data.xls(【免费】对银行的贷款风险用户识别资源-优快云文库)
2.编写代码
1).导入库
首先,导入了所需的库,包括Pandas用于数据处理,sklearn.linear_model的LogisticRegression用于逻辑回归模型,sklearn.model_selection的train_test_split用于数据集划分,sklearn的metrics用于评估模型指标。
import pandas as pd#用于数据分析
from sklearn.linear_model import LogisticRegression#用于逻辑回归模型
#sklearn.model_selection库中的train_test_split函数用于数据集划分
from sklearn.model_selection import train_test_split
#sklearn的metrics用于评估模型指标
from sklearn import metrics2)读入数据
使用Pandas的read_excel函数读取了名为"data.xls"的Excel数据文件,并将其存储在名为"data"的DataFrame对象中。
data=pd.read_excel('./data.xls')#读入数据
3)取出自变量与因变量
从"data" DataFrame中,使用drop函数删除了名为"还款拖欠情况"的列,并将其赋值给变量"x",这里将x作为自变量。同时,将名为"还款拖欠情况"的列赋值给变量"y",即因变量。
#使用drop函数删除了名为"还款拖欠情况"的列,并将其赋值给变量"x"
x=data.drop('还款拖欠情况',axis=1)
#将名为"还款拖欠情况"的列赋值给变量"y"
y=data.还款拖欠情况
4)将数据集分为训练集和测试集
使用train_test_split函数将数据集划分为训练集和测试集。参数"test_size=0.2"表示将20%的数据作为测试集,"random_state=100"表示设置随机种子,以确保每次运行时划分结果一致。划分后的训练集和测试集分别赋值给"x_train_w"、"x_test_w"、"y_train_w"和"y_test_w"。
x_train_w,x_test_w,y_train_w,y_test_w =\
train_test_split(x,y,test_size=0.2,random_state=100)
#'\'的作用是连接下一行train_test_split函数详见:
5)创建逻辑回归模型
创建了一个LogisticRegression对象"lr",使用参数"C=0.01"和"max_iter=100"对逻辑回归模型进行配置。参数"C"控制正则化强度,较小的值表示更强的正则化,"max_iter"表示最大的迭代次数。
#创建了一个LogisticRegression对象,C代表正则化强度,max_iter代表迭代次数
lr=LogisticRegression(C=0.01,max_iter=100)逻辑回归模型详见:
6)拟合模型
使用训练数据集(x_train_w, y_train_w)对逻辑回归模型进行训练,即拟合模型。
lr.fit(x_train_w,y_train_w)#对逻辑回归模型进行训练,拟合模型
7)对模型进行预测
用训练好的模型对测试数据集(x_test_w)进行预测,将预测结果赋值给"pred"变量。
pred = lr.predict(x_test_w)#预测
8)计算准测率
使用模型的.score()方法计算测试集上的准确率,并将结果打印输出。
score = lr.score(x_test_w,y_test_w)#这里的score与线性回归的score方法不同
print(score)
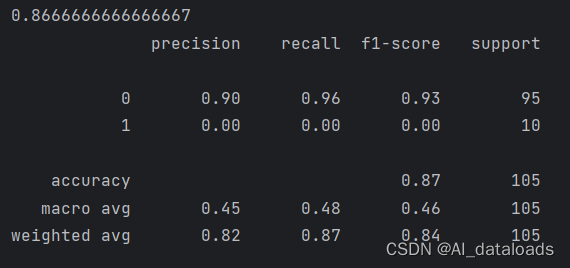
9)分类报告,包含准确率、召回率、F1-score等指标。
混淆矩阵metrics详见:
使用sklearn的metrics库中的classification_report函数计算并打印输出测试集上的分类报告,包含准确率、召回率、F1-score等指标。
#classification_report函数计算并打印输出测试集上的分类报告,包含准确率、召回率、F1-score等指标
print(metrics.classification_report(y_test_w,pred))3.代码结果:
三、总结
这段代码的功能是读取Excel数据文件,将数据分成训练集和测试集,使用逻辑回归模型对训练集进行训练,然后在测试集上进行预测并输出模型评估指标。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









