




 DreamTalk利用扩散模型和关键组件(去噪网络、唇部专家和风格预测器)生成逼真且风格丰富的说话头像,能处理多种输入,超越现有技术。
DreamTalk利用扩散模型和关键组件(去噪网络、唇部专家和风格预测器)生成逼真且风格丰富的说话头像,能处理多种输入,超越现有技术。
“DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models”
DreamTalk是一个基于扩散的音频驱动的富有表现力的说话头生成框架,可以生成不同说话风格的高质量的说话头视频。DreamTalk对各种输入表现出强大的性能,包括歌曲、多语言语音、噪声音频和域外肖像。

项目主页:https://dreamtalk-project.github.io/
论文地址:https://arxiv.org/pdf/2312.09767.pdf
Github地址:https://github.com/ali-vilab/dreamtalk
摘要
DreamTalk利用扩散模型生成表情丰富的说话头像。该框架包括三个关键组件:去噪网络、风格感知的唇部专家和风格预测器。去噪网络能够生成高质量的音频驱动面部动作,唇部专家能够提高唇部运动的表现力和准确性,风格预测器能够直接从音频中预测目标表情,减少对昂贵的风格参考的依赖。实验结果表明,DreamTalk能够生成逼真的说话头像,超越现有的最先进的对手。
简介
音频驱动的说话头生成是一种将肖像与语音音频动画化的技术,它在视频游戏、电影配音和虚拟化身等领域引起了广泛关注。生成逼真的面部表情对于增强说话头的真实感至关重要。目前,生成对抗网络(GANs)在表达性说话头生成方面处于领先地位,但其存在的模式崩溃和不稳定训练问题限制了其在不同说话风格上的高性能表现。扩散模型是一种新的生成技术,近年来在图像生成、视频生成和人体动作合成等领域取得了高质量的结果。然而,目前的扩散模型在表达性说话头生成方面仍存在问题,如帧抖动问题。因此,如何充分发挥扩散模型在表达性说话头生成方面的潜力是一个有前景但尚未开发的研究方向。
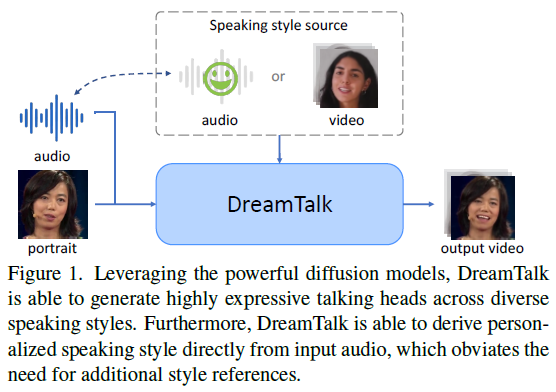
DreamTalk是一个表情丰富的说话头生成框架,利用扩散模型提供高性能和减少对昂贵的风格参考的依赖。它由去噪网络、风格感知的嘴唇专家和风格预测器组成。去噪网络利用扩散模型产生具有参考视频指定的说话风格的音频驱动的面部动作。风格感知的嘴唇专家确保准确的嘴唇动作和生动的表情。风格预测器通过音频直接预测个性化的说话风格。DreamTalk能够在各种说话风格下一致生成逼真的说话头,并最小化对额外风格参考的需求。它还能够灵活地操纵说话风格,并在多语言、嘈杂音频和领域外肖像等各种输入下展现出强大的泛化能力。通过全面的定性和定量评估,证明了DreamTalk相比现有的最先进方法的优越性。
相关工作
两种人工智能生成人物头像的方法:音频驱动和表情驱动。音频驱动方法分为个人特定和个人不确定两种,前者需要在训练时指定演讲者,后者则可以为未知演讲者生成视频。表情驱动方法早期采用离散情感类别模型,后来采用表情参考视频进行表情转移。然而,这些基于GAN的模型存在模式崩溃问题。本文提出了一种使用扩散模型的方法,可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









