




 文章介绍了一种新的训练准则,通过最大化高斯性来规整数据分布,特别在深度学习的说话人识别中提升了性能。该方法避免了标准化流模型的过拟合问题,使数据分布更接近高斯分布,有助于简化模型并改善识别效果。
文章介绍了一种新的训练准则,通过最大化高斯性来规整数据分布,特别在深度学习的说话人识别中提升了性能。该方法避免了标准化流模型的过拟合问题,使数据分布更接近高斯分布,有助于简化模型并改善识别效果。
近日,清华大学、昆明理工大学、北京邮电大学联合在模式识别权威杂志 Pattern Recognition (IF 8.0) 上发表论文,报告了一种最大化高斯性 (Maximum Gaussianality) 的训练准则,用于对数据分布进行规整。

分布规整与标准化流模型
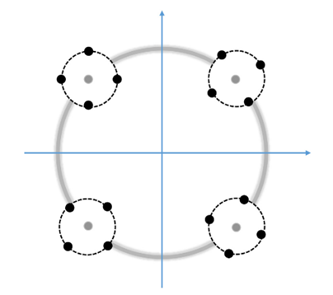
我们知道数据的概率分布对如何选择模式识别算法至关重要。通常我们希望概率分布越简单越好,最好是高斯分布,这样就可以选择简单的模型对其进行建模,进而完成分类、生成等模式识别任务。例如在随机线性区分性分析 (Probabilistic LDA, PLDA),数据必须是服从一些协方差一致的一组高斯分布,且这些高斯分布的均值本身也是一个高斯分布。形象的理解,如下图所示。
问题在于,现实应用中大部分数据都很复杂,这就必须用一个复杂的模型来建模。那么,有没有可能把一个复杂的分布映射成一个简单的分布呢?是有可能的,标准化流模型 (Normalization Flow, NF) 就是这样一个模型。它可以通过一串可逆映射把复杂分布映射到高斯分布,或反过来将高斯分布再映射回观察数据空间,如下图所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









