







📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
在当今快速迭代的软件开发周期中,性能问题往往成为影响产品质量和用户体验的关键因素。作为测试开发工程师,掌握专业的性能监控与剖析工具不仅能帮助我们快速定位性能瓶颈,更能为系统优化提供数据支撑。本文将为您详细介绍行业主流的性能监控与剖析工具。
在性能优化领域,监控工具和剖析工具就像医生的"听诊器"和"显微镜":
-
监控工具(如Prometheus、Grafana)相当于听诊器,用于实时检查系统生命体征(CPU、内存、网络等)
-
剖析工具(如JProfiler、FlameGraph)则像显微镜,深入代码层面分析性能瓶颈
科普时间:根据Google SRE手册,有效的监控系统应该遵循"四个黄金信号"原则:
-
延迟(Latency)
-
流量(Traffic)
-
错误率(Errors)
-
饱和度(Saturation)
二、基础监控三板斧:Linux自带工具详解
1. vmstat - 系统健康快照
# 每2秒采样一次,共5次
vmstat 2 5输出解读:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 467804 139488 2347488 0 0 21 26 3 2 15 5 78 2 0-
关键指标:
-
r:运行队列长度(>CPU核数说明过载) -
wa:IO等待时间占比(>5%需警惕)
-
2. top - 进程资源追踪器
交互命令秘籍:
-
P:按CPU使用率排序 -
M:按内存使用排序 -
1:展开多核CPU详情
https://media/image2.png
有趣事实:top的"load average"三个数值分别代表1分钟、5分钟、15分钟的系统平均负载,理想值应小于CPU核数。
三、企业级监控方案对比
1. 经典组合:Collectd + InfluxDB + Grafana
数据流架构:
Collectd(采集) -> InfluxDB(存储) -> Grafana(可视化)优势场景:
-
物理服务器监控
-
长期趋势分析
-
自定义指标收集
2. 云原生首选:Prometheus + Grafana
核心特性对比:
| 特性 | Prometheus | InfluxDB |
|---|---|---|
| 数据模型 | 多维标签 | 时间序列 |
| 查询语言 | PromQL | Flux/InfluxQL |
| 服务发现 | 原生支持 | 需插件 |
| 适用场景 | 动态云环境 | 固定基础设施 |
科普时间:Prometheus的Pull(拉取)模式 vs 传统Push(推送)模式:
-
Pull更适合动态变化的云环境
-
Push更适合防火墙内的固定节点
四、Java生态剖析工具深度解析
1. JVM调优三剑客
| 工具 | 核心功能 | 典型使用场景 |
|---|---|---|
| JConsole | 可视化监控JVM基础指标 | 开发环境快速诊断 |
| VisualVM | 插件式深度分析 | 内存泄漏排查 |
| JStack | 线程快照分析 | 死锁/死循环定位 |
2. 火焰图:性能瓶颈的X光片
生成火焰图的四步魔法:
# 1. 采集性能数据
perf record -F 99 -p <PID> -g -- sleep 30
# 2. 转换数据格式
perf script > out.perf
# 3. 生成折叠格式
./stackcollapse-perf.pl out.perf > out.folded
# 4. 生成火焰图
./flamegraph.pl out.folded > flamegraph.svg如何阅读火焰图:
-
x轴:采样数量(越宽耗时越多)
-
y轴:调用栈深度
-
颜色:随机区分不同方法
五、分布式系统追踪实战
1. SkyWalking vs Zipkin架构对比
SkyWalking特性:
-
服务拓扑自动发现
-
跨进程/跨线程追踪
-
性能指标与追踪数据融合
Zipkin特性:
-
更轻量级的部署
-
兼容OpenTracing标准
-
丰富的社区集成
科普时间:分布式追踪的三大核心概念:
-
Trace:完整的请求链路
-
Span:链路中的单个操作单元
-
Context Propagation:上下文传递机制
六、工具选型决策树
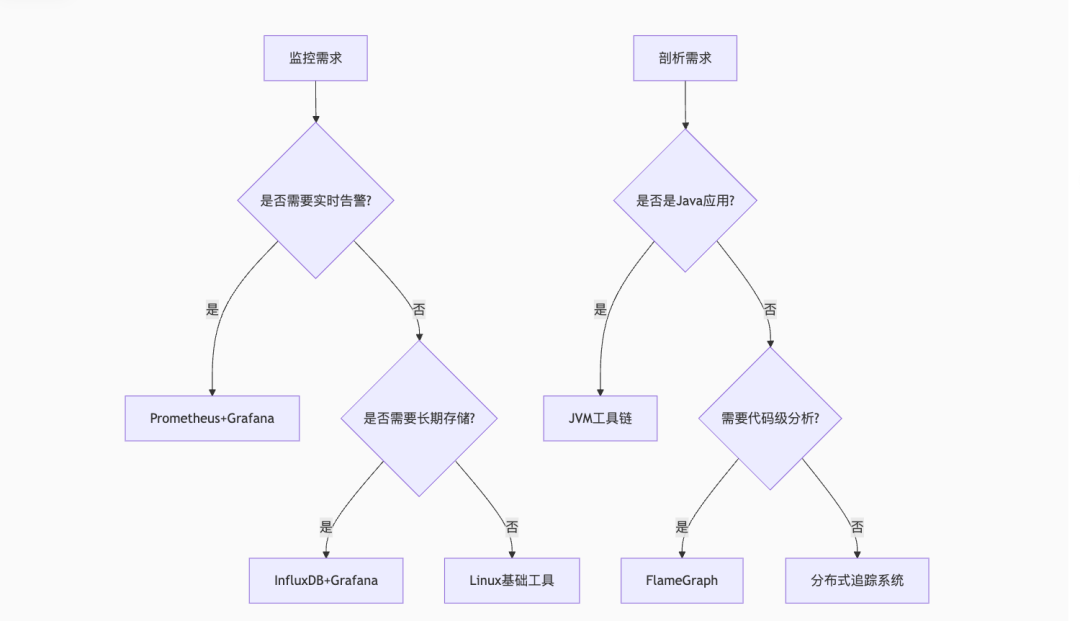
七、性能优化实战案例
案例背景:
某电商平台大促期间出现接口超时,QPS从5000骤降到800。
排查过程:
-
通过Prometheus发现CPU使用率正常但GC频繁
-
JConsole显示老年代内存持续增长
-
VisualVM内存抽样发现HashMap未合理初始化
-
JStack发现多个线程阻塞在日志锁上
优化方案:
-
调整HashMap初始容量
-
改用异步日志框架
-
增加JVM年轻代大小
效果:
QPS恢复至5500,P99延迟降低60%
结语:构建你的性能工具箱
建议每个测试开发工程师都应该掌握的"性能武器库":
-
基础诊断:top/vmstat/nmon
-
JVM专家:VisualVM + Arthas
-
全链路追踪:SkyWalking
-
可视化展示:Grafana
-
深度剖析:FlameGraph + perf
互动话题:你在性能排查过程中遇到过哪些"诡异"问题?最终是如何解决的?欢迎在评论区分享你的战斗故事!
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









