







📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
在进行大模型基准测试时,首先需要确定测试的指标体系,明确评测的维度和对应指标。大模型评测的指标体系可以按照场景、能力、任务、指标四层结构进行构建。
-
场景(Scenario):定义模型应用的具体环境或条件,例如通用对话、专业领域问答、代码生成等。
-
能力(Capability):指模型所具备的各项能力,如理解、生成、推理、知识、安全等。
-
任务(Task):为评估特定能力而设计的具体任务,例如文本分类、情感分析、阅读理解等。
-
指标(Metric):用于量化模型在任务中的表现,例如准确率、召回率、F1分数等。
四层结构运行机制
1、确定评测场景
根据模型的应用目标,确定需要评测的场景。例如,若要评测一个医学问答模型,则场景为医学问答。
2、明确评测能力
根据场景需求,确定需要评测的模型能力。例如,医学问答模型需要具备医学知识理解、问题理解、答案生成等能力。
3、选择评测任务
针对每项能力,选择合适的评测任务。例如,为了评估医学知识理解能力,可以选择医学文本分类、医学实体识别等任务。
4、选取评测指标
对于每个任务,选择合适的评测指标。例如,对于医学文本分类任务,可以选择准确率、F1分数等指标。
5、构建评测数据集
准备与评测任务和指标相匹配的数据集。
6、执行评测
将模型应用于评测数据集,得到模型的输出结果。
7、计算评测指标
根据模型输出结果和真实标签,计算相应的评测指标。
8、分析评测结果
对评测结果进行分析,评估模型在不同场景、能力和任务上的表现,并找出模型的优缺点。
指标体系-四层结构示例
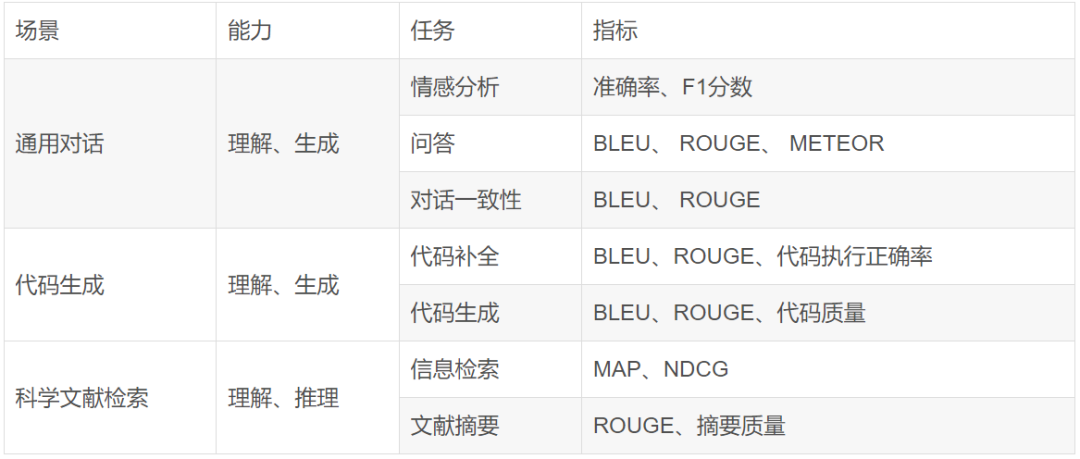
指标计算方式(常用)
指标计算方式(常用)
-
准确率
描述:衡量模型回答正确的比例。
计算方式:正确回答的数量除以总问题数量。
-
召回率
描述:体现模型正确识别正样本的能力。
计算方式:正确识别的正样本数量除以实际正样本数量。
-
精确率
精确率也称为查准率,是衡量模型预测结果中真正例(True Positives,TP)在所有被预测为正例的样本(包括真正例和假正例,即 TP 和 False Positives,FP)中所占的比例。它主要反映了模型在预测为正例的结果中,真正正确的比例有多高,即模型预测的准确性。
计算方式:精确率 = TP / (TP + FP)
-
F1 Scores
描述:综合考虑精确率和召回率的指标。
计算方式:2 * 精确率 * 召回率 / (精确率 + 召回率)。
-
BLUE
描述:用于评估文本生成和翻译任务的质量,衡量生成文本与参考文本的相似程度。
计算方式:基于 n-gram 匹配的算法,计算生成文本与参考文本之间的相似度得分。
-
ROUGE
描述:用于评估摘要生成任务的质量,衡量生成摘要与参考摘要的重合度。
计算方式:通过计算生成摘要和参考摘要中共同出现的 n-gram 的比例来评估摘要的质量
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



















 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









