







📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
有人问我登录携带登录的测试框架该怎么处理,今天就对框架做一点小升级吧,加入登录的测试功能。
选用的测试网址为我电脑本地搭建的禅道
更改了以下的一些文件,框架为原文章框架主体
conftest.py更改
conftest.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import base64
import pytest
import allure
from py.xml import html
from selenium import webdriver
from page.webpage import WebPage
from common.readconfig import ini
from tools.send_mail import send_report
from tools.times import timestamp
from config.conf import cm
driver = None
@pytest.fixture(scope='session', autouse=True)
def drivers(request):
global driver
if driver is None:
driver = webdriver.Chrome()
web = WebPage(driver)
web.get_url(ini.url)
def fn():
driver.quit()
request.addfinalizer(fn)
return driver
@pytest.hookimpl(hookwrapper=True)
def pytest_runtest_makereport(item):
"""
当测试失败的时候,自动截图,展示到html报告中
:param item:
"""
pytest_html = item.config.pluginmanager.getplugin('html')
outcome = yield
report = outcome.get_result()
extra = getattr(report, 'extra', [])
if report.when == 'call' or report.when == "setup":
xfail = hasattr(report, 'wasxfail')
if (report.skipped and xfail) or (report.failed and not xfail):
screen_img = _capture_screenshot()
if screen_img:
html = '<div><img src="data:image/png;base64,%s" alt="screenshot" style="width:1024px;height:768px;" ' \
'onclick="window.open(this.src)" align="right"/></div>' % screen_img
extra.append(pytest_html.extras.html(html))
report.extra = extra
report.description = str(item.function.__doc__)
def pytest_html_results_table_header(cells):
cells.insert(1, html.th('用例名称'))
cells.insert(2, html.th('Test_nodeid'))
cells.pop(2)
def pytest_html_results_table_row(report, cells):
cells.insert(1, html.td(report.description))
cells.insert(2, html.td(report.nodeid))
cells.pop(2)
def pytest_html_results_table_html(report, data):
if report.passed:
del data[:]
data.append(html.div('通过的用例未捕获日志输出.', class_='empty log'))
def pytest_html_report_title(report):
report.title = "pytest示例项目测试报告"
def pytest_configure(config):
config._metadata.clear()
config._metadata['测试项目'] = "测试百度官网搜索"
config._metadata['测试地址'] = ini.url
def pytest_html_results_summary(prefix, summary, postfix):
# prefix.clear() # 清空summary中的内容
prefix.extend([html.p("所属部门: XX公司测试部")])
prefix.extend([html.p("测试执行人: 随风挥手")])
def pytest_terminal_summary(terminalreporter, exitstatus, config):
"""收集测试结果"""
result = {
"total": terminalreporter._numcollected,
'passed': len(terminalreporter.stats.get('passed', [])),
'failed': len(terminalreporter.stats.get('failed', [])),
'error': len(terminalreporter.stats.get('error', [])),
'skipped': len(terminalreporter.stats.get('skipped', [])),
# terminalreporter._sessionstarttime 会话开始时间
'total times': timestamp() - terminalreporter._sessionstarttime
}
print(result)
if result['failed'] or result['error']:
send_report()
def _capture_screenshot():
"""截图保存为base64"""
now_time, screen_path = cm.screen_file
driver.save_screenshot(screen_path)
allure.attach.file(screen_path, "测试失败截图...{}".format(
now_time), allure.attachment_type.PNG)
with open(screen_path, 'rb') as f:
imagebase64 = base64.b64encode(f.read())
return imagebase64.decode()
config.ini更改
[HOST]
HOST = http://127.0.0.1/zentao/user-login-L3plbnRhby9teS5odG1s.html
conf.py更改
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import os
from selenium.webdriver.common.by import By
from tools.times import datetime_strftime
class ConfigManager(object):
# 项目目录
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 日志目录
LOG_PATH = os.path.join(BASE_DIR, 'logs')
# 报告目录
REPORT_PATH = os.path.join(BASE_DIR, 'report', 'report.html')
ELEMENT_PATH = os.path.join(BASE_DIR, 'page_element')
# 元素定位的类型
LOCATE_MODE = {
'css': By.CSS_SELECTOR,
'xpath': By.XPATH,
'name': By.NAME,
'id': By.ID,
'class': By.CLASS_NAME
}
# 邮件信息
EMAIL_INFO = {
'username': '1084502012@qq.com', # 切换成你自己的地址
'password': 'QQ邮箱授权码',
'smtp_host': 'smtp.qq.com',
'smtp_port': 465
}
# 收件人
ADDRESSEE = [
'1084502012@qq.com',
]
@property
def ini_file(self):
# 配置文件
_file = os.path.join(self.BASE_DIR, 'config', 'config.ini')
if not os.path.exists(_file):
raise FileNotFoundError("配置文件%s不存在!" % _file)
return _file
def element_file(self, name):
"""页面元素文件"""
element_path = os.path.join(self.ELEMENT_PATH, '%s.yaml' % name)
if not os.path.exists(element_path):
raise FileNotFoundError("%s 文件不存在!" % element_path)
return element_path
@property
def log_path(self):
log_path = os.path.join(self.BASE_DIR, 'logs')
if not os.path.exists(log_path):
os.makedirs(log_path)
return os.path.join(log_path, "%s.log" % datetime_strftime())
@property
def screen_file(self):
now_time = datetime_strftime("%Y%m%d%H%M%S")
# 截图目录
screenshot_dir = os.path.join(self.BASE_DIR, 'screen_capture')
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir)
screen_path = os.path.join(screenshot_dir, "{}.png".format(now_time))
return now_time, screen_path
cm = ConfigManager()
if __name__ == '__main__':
print(cm.BASE_DIR)
page更改
webpage.py
添加了几个函数!
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
"""
selenium基类
本文件存放了selenium基类的封装方法
"""
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from config.conf import cm
from tools.times import sleep
from tools.logger import Logger
log = Logger(__name__).logger
class WebPage(object):
"""selenium基类"""
def __init__(self, driver):
# self.driver = webdriver.Chrome()
self.driver = driver
self.timeout = 20
self.wait = WebDriverWait(self.driver, self.timeout)
def get_url(self, url):
"""打开网址并验证"""
self.driver.maximize_window()
self.driver.set_page_load_timeout(60)
try:
self.driver.get(url)
self.driver.implicitly_wait(10)
log.info("打开网页:%s" % url)
except TimeoutException:
raise TimeoutException("打开%s超时请检查网络或网址服务器" % url)
@staticmethod
def element_locator(func, locator):
"""元素定位器"""
name, value = locator
return func(cm.LOCATE_MODE[name], value)
def find_element(self, locator):
"""寻找单个元素"""
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_element_located(args)), locator)
def find_elements(self, locator):
"""查找多个相同的元素"""
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_all_elements_located(args)), locator)
def focus(self):
"""聚焦元素"""
self.driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
def elements_num(self, locator):
"""获取相同元素的个数"""
number = len(self.find_elements(locator))
log.info("相同元素:{}".format((locator, number)))
return number
def input_text(self, locator, txt):
"""输入(输入前先清空)"""
sleep(0.5)
ele = self.find_element(locator)
ele.clear()
ele.send_keys(txt)
log.info("输入文本:{}".format(txt))
def is_click(self, locator):
"""点击"""
ele = self.find_element(locator)
ele.click()
sleep()
log.info("点击元素:{}".format(locator))
def is_exists(self, locator):
"""元素是否存在(DOM)"""
try:
WebPage.element_locator(lambda *args: EC.presence_of_element_located(args)(self.driver), locator)
return True
except NoSuchElementException:
return False
def alert_exists(self):
"""判断弹框是否出现,并返回弹框的文字"""
alert = EC.alert_is_present()(self.driver)
if alert:
text = alert.text
log.info("Alert弹窗提示为:%s" % text)
alert.accept()
return text
else:
log.error("没有Alert弹窗提示!")
def element_text(self, locator):
"""获取当前的text"""
_text = self.find_element(locator).text
log.info("获取文本:{}".format(_text))
return _text
def get_attribute(self, locator, name):
"""获取元素属性"""
return self.find_element(locator).get_attribute(name)
@property
def get_source(self):
"""获取页面源代码"""
return self.driver.page_source
def refresh(self):
"""刷新页面F5"""
self.driver.refresh()
self.driver.implicitly_wait(30)
if __name__ == "__main__":
pass
page_element更改
login.yaml
账号: "css==input[name=account]"
密码: "css==input[name=password]"
登录: "css==button#submit"
我的地盘: "xpath==//nav[@id='navbar']//span[text()=' 我的地盘']"
右上角名称: "css==.user-name"
退出登录: "xpath==//a[text()='退出']"
product.yaml
产品按钮: "xpath==//nav[@id='navbar']//a[text()='产品']"
添加产品: "xpath==//div[@id='pageActions']//a[text()=' 添加产品']"
产品名称: "css==#name"
产品代号: "css==#code"
保存产品: "css==#submit"
产品列表: "xpath==//ul[@class='nav nav-stacked nav-secondary scrollbar-hover']//a[1]"
page_object更改
loginpage.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from page.webpage import WebPage
from common.readelement import Element
login = Element('login')
class LoginPage(WebPage):
"""登录类"""
def username(self, name):
"""用户名"""
self.input_text(login['账号'], name)
def password(self, pwd):
"""密码"""
self.input_text(login['密码'], pwd)
def submit(self):
"""登录"""
self.is_click(login['登录'])
def quit_login(self):
"""退出登录"""
self.is_click(login['右上角名称'])
self.is_click(login['退出登录'])
def login_success(self):
"""验证登录"""
return self.is_exists(login['我的地盘'])
productpage.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from page.webpage import WebPage, sleep
from common.readelement import Element
product = Element('product')
class ProductPage(WebPage):
"""产品类"""
def click_product(self):
"""点击产品"""
self.is_click(product['产品按钮'])
def add_product(self):
"""添加产品"""
self.is_click(product['添加产品'])
def add_product_content(self, name, code):
"""添加产品内容"""
self.input_text(product['产品名称'], name)
self.input_text(product['产品代号'], code)
def save_product(self):
"""保存产品"""
self.focus()
self.is_click(product['保存产品'])
def product_list(self):
"""产品列表"""
return [i.get_attribute('title') for i in self.find_elements(product['产品列表'])]
if __name__ == '__main__':
a = product['产品列表'][1] + "[1]"
print(a)
TestCase更改
test_login.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pytest
from tools.times import sleep
from page_object.loginpage import LoginPage
class TestLogin:
"""测试登录"""
@pytest.mark.parametrize("name,pwd", [('admin', 'Admin123456'), ('test', 'test123')])
def test_001(self, drivers, name, pwd):
login = LoginPage(drivers)
login.username(name)
login.password(pwd)
login.submit()
sleep(3)
res = login.alert_exists()
if res:
assert res == "登录失败,请检查您的用户名或密码是否填写正确。"
elif login.login_success():
login.quit_login()
test_product.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import pytest
import allure
from random import randint
from tools.times import sleep
from page_object.loginpage import LoginPage
from page_object.productpage import ProductPage
@allure.feature("测试产品模块")
class TestProduct:
@pytest.fixture(scope='class', autouse=True)
def is_login(self, request, drivers):
login = LoginPage(drivers)
login.username('admin')
login.password('Admin123456')
login.submit()
sleep(3)
def logout():
login.quit_login()
request.addfinalizer(logout)
@allure.story("测试添加产品")
def test_001(self, drivers):
"""搜索"""
product = ProductPage(drivers)
product.click_product()
product.add_product()
name, code = randint(100, 999), randint(100, 999)
product.add_product_content(name, code)
product.save_product()
sleep(3)
product.click_product()
assert str(name) in product.product_list()
if __name__ == '__main__':
pytest.main(['TestCase/test_aproduct.py'])
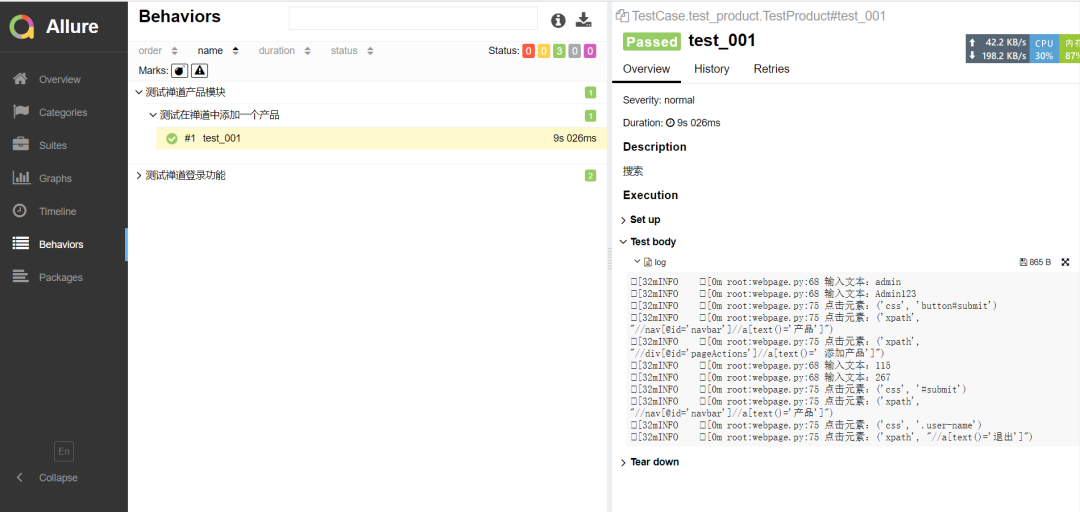
测试结果
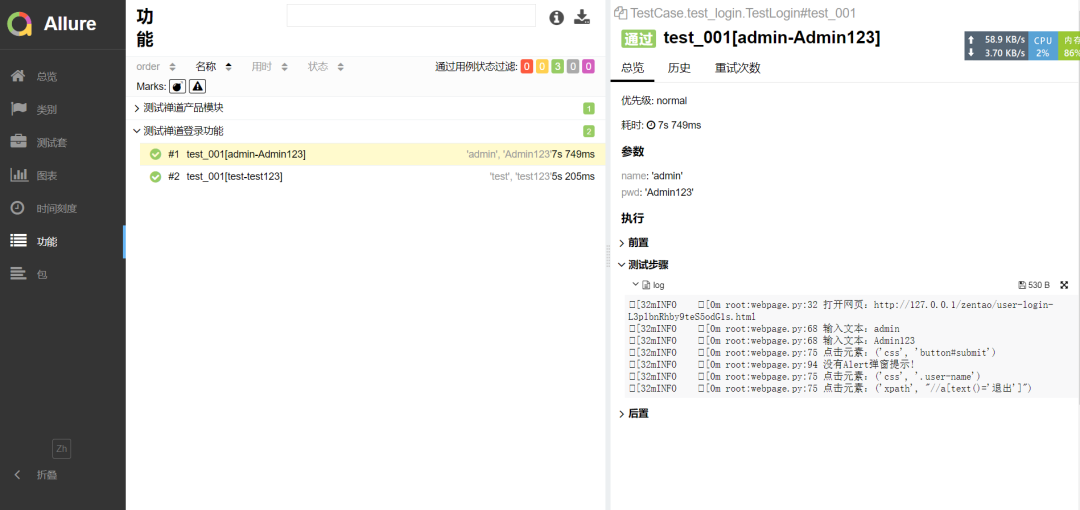
登录之后的测试用例:
测试登录的用例
开源地址
本次示例也开源在码云 https://gitee.com/wxhou/web-zentao
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









