











 https://blog.youkuaiyun.com/AI_Green/article/details/134931243?spm=1001.2014.3001.5502
https://blog.youkuaiyun.com/AI_Green/article/details/134931243?spm=1001.2014.3001.5502Selenium是一个用于网页应用程序测试的工具。它提供了一个API,可以操作浏览器,并且可以通过这个API编写代码来测试Web应用程序的用户界面。
首先,你需要安装selenium库和chromedriver。你可以使用pip来安装selenium库:
pip install selenium同时你还需要跟你chrome浏览器版本匹配的chromedriver版本。chrome浏览器默认是自动更新。所以我们要首先禁用他自动更新。
1.禁用chrome更新:
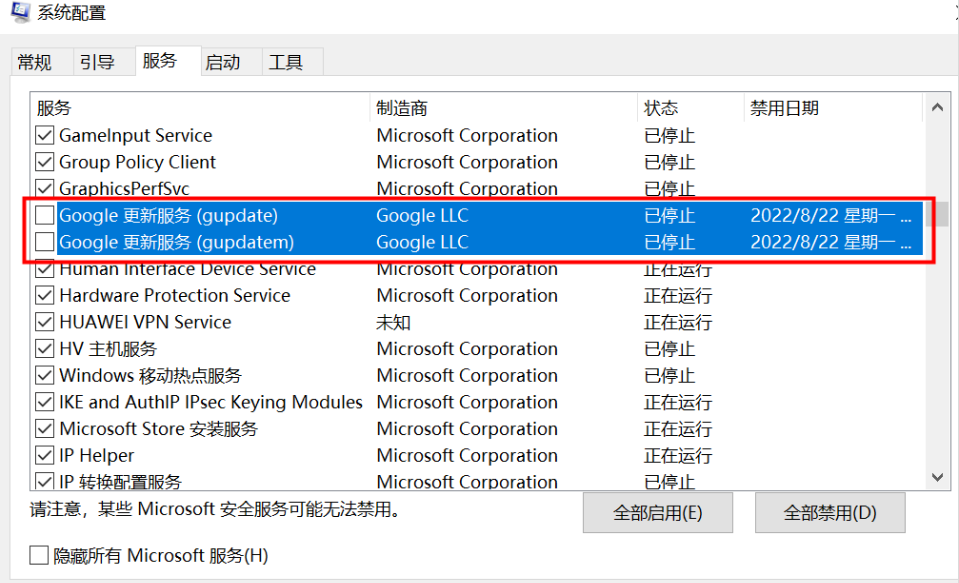
开始—运行—msconfig—服务
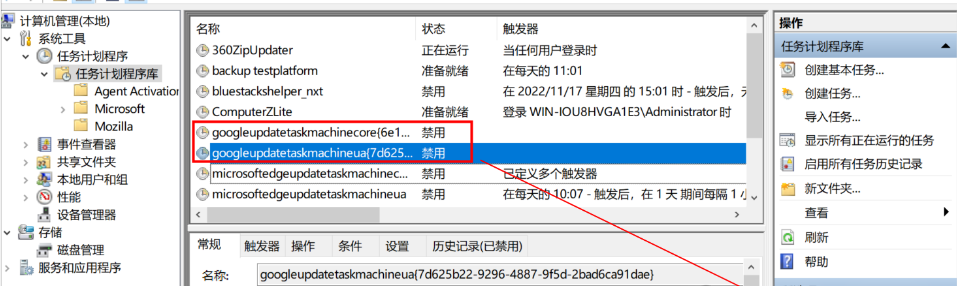
我的电脑—右键管理—任务计划程序
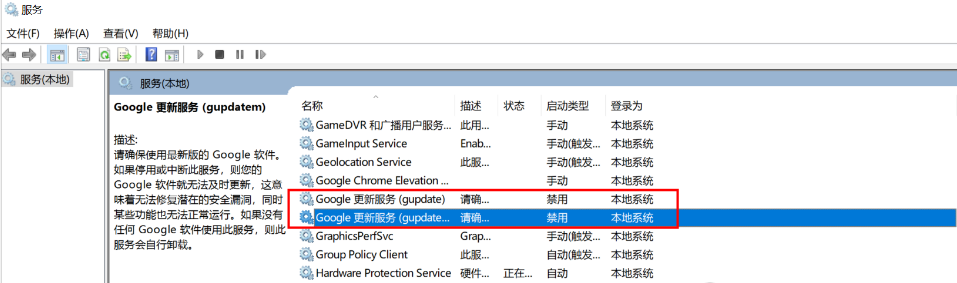
开始—运行—service
2.安装对应版本的chrome和chromedriver
chrome历史版本下载:
https://downzen.com/en/windows/google-chrome/versions/?page=2
chromedriver下载链接:
https://registry.npmmirror.com/binary.html?path=chromedriver
这里,我已下载好了对应的浏览器版本和chromedriver,关注"伤心的辣条"公众号,回复“selenium”获取下载链接

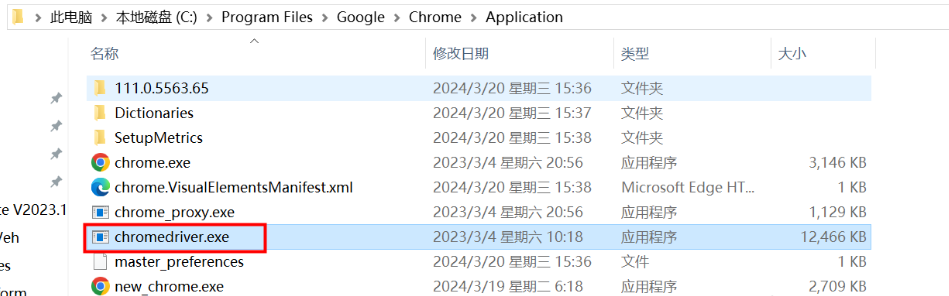
3.复制chromedriverd到chrome安装目录
4.添加path环境变量
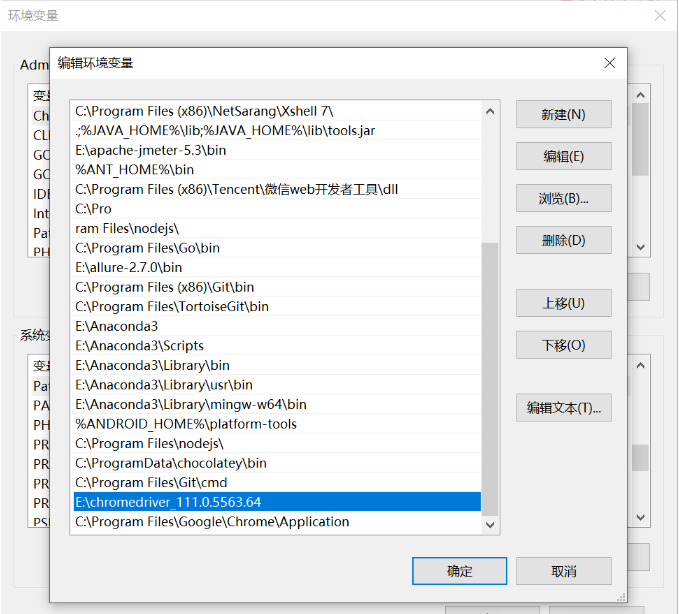
5.开始—运行—输入chromedriver
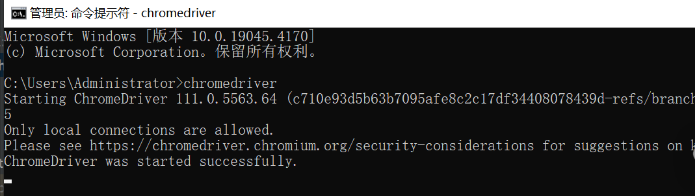
6.编写测试代码
url = "www.baidu.com"
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
7.如何准确定位元素:
八大元素定位法则:
1.id:通过元素的id属性来进行元素的获取,一般id都是不会重复的,类似人的身份证
2.name:通过元素的name属性进行元素的获取,一般有可能会重名,类似于人的名字
3.tag name:通过元素的标签名来进行元素的获取,一定会重名,一般在自动化中一般不用。一般在爬虫领域下会用。
4.class name:通过元素的class属性进行元素的获取,不是特别推荐,class的值会特别长,所以在读代码的时候不会特别友好
5.link test: 通过元素的文本进行定位,只能用于a标签进行定位
6.partial link text:与link test一样,只能通过文本进行定位,只能说通过模糊查找到方式进行元素的定位,也是只能用于a标签
7.css selector:定位界的万金油,核心是通过class属性进行定位
8.xpath:定位界的万金油,是基于树状结构进行定位
元素定位的方法:
find_element(by,value)
如果元素在定位过程中有重复属性,导致定位无法精准,selenium定义下,如果有多个元素相同,默认返回第一个获取到的元素8.特殊操作,句柄
handles:句柄,浏览器的每一个标签页,都是一个句柄默认打开的浏览器,都是聚焦在第一个标签页,Selenium不会自动切换标签页。如果在运行Selenium时需要切换到新的标签页来进行操作,则需要进行句柄的切换实际操作过程中,尽可能保持最多不超过两个标签页存在,一般都是关一个,再换一个。不切换句柄无法操作新的标签页,从而导致流程的失败。
句柄的切换
handles = driver.window_handles # 获取浏览器的所有句柄
driver.close()
driver.switch_to.window(handles[1])
print(driver.title)
driver.close()
driver.switch_to.window(handles[0])
print(driver.title)行动吧,在路上总比一直观望的要好,未来的你肯定会感谢现在拼搏的自己!如果想学习提升找不到资料,没人答疑解惑时,请及时加入群: 759968159,里面有各种测试开发资料和技术可以一起交流哦。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。



















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









