







 本文介绍了如何利用Python的Selenium和PhantomJS库爬取天天基金网的基金排行榜,获取指定页数内的基金近一周收益率和详情链接。接着,通过多进程并发处理,进入每个基金的详情页面,提取更多基金信息,如近6月收益率、基金类型、规模等。最后,将所有信息整理并按近6月收益率排序,写入Excel表格。整个过程中,结合了HTML解析、XPath选择器以及正则表达式进行数据提取。
本文介绍了如何利用Python的Selenium和PhantomJS库爬取天天基金网的基金排行榜,获取指定页数内的基金近一周收益率和详情链接。接着,通过多进程并发处理,进入每个基金的详情页面,提取更多基金信息,如近6月收益率、基金类型、规模等。最后,将所有信息整理并按近6月收益率排序,写入Excel表格。整个过程中,结合了HTML解析、XPath选择器以及正则表达式进行数据提取。

功能:
通过程序实现从基金列表页,获取指定页数内所有基金的近一周收益率以及每支基金的详情页链接。再进入每支基金的详情页获取其余的基金信息,将所有获取到的基金详细信息按近6月收益率倒序排列写入一个Excel表格。
思路:
-
通过实例化Tiantian_spider类的对象,初始化一个PhantomJS浏览器对象
-
使用浏览器对象访问天天基金近六月排行的页面,获取该页面的源码
-
从源码从获取每支基金所在的行(可以指定要获取基金的页数)
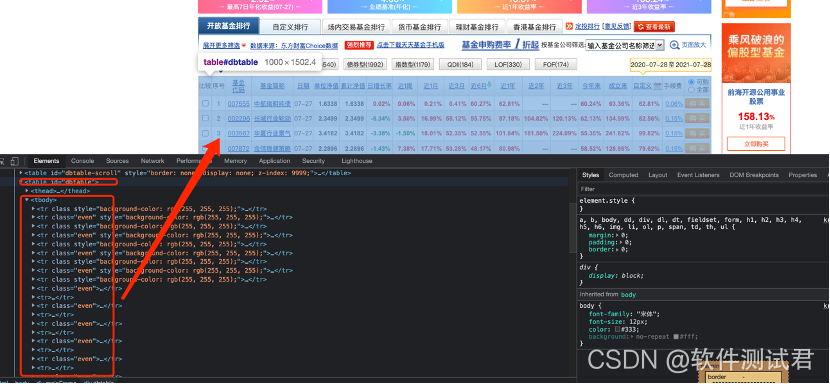
-
从每行中获取每支基金的近1周收益率和基金详情链接
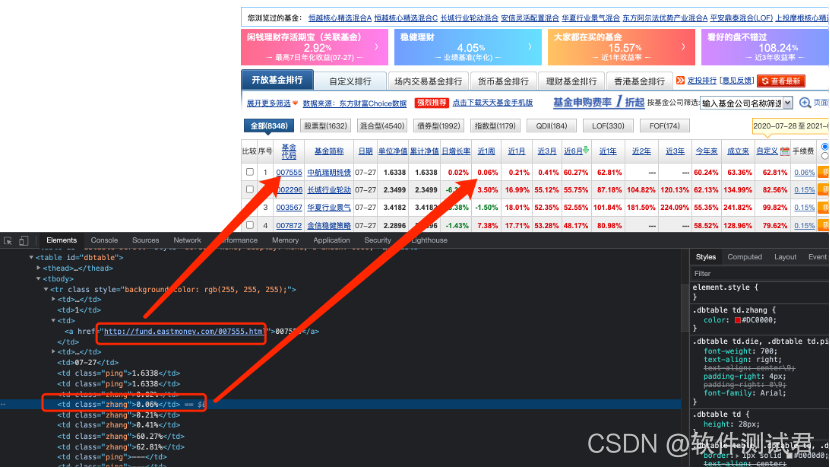
-
获取到每个基金的详情链接后,使用多进程分别进入每支基金的详情页面
-
进入详情页后,获取基金的相关信息,并存入列表
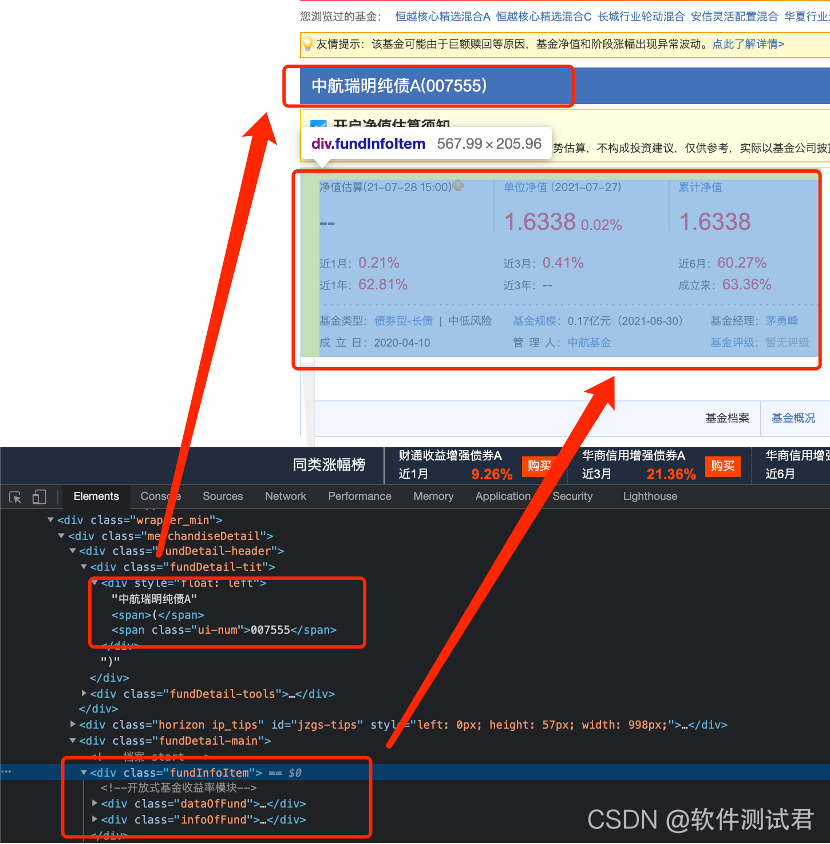
-
将从所有基金的基金详情与在列表页获取的基金近1周收益率拼接后存入列表
-
再将所有信息写入Excel表格
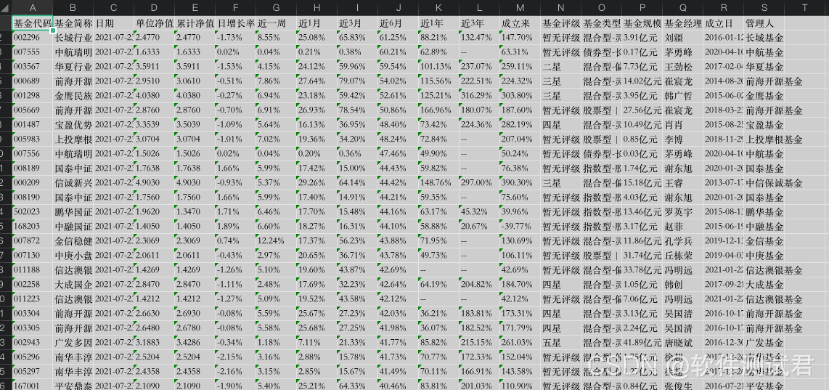
1from selenium import webdriver
2from lxml import etree
3import time
4from openpyxl import Workbook
5import multiprocessing
6import re
7
8class Tiantian_spider():
9 def __init__(self):
10 self.driver = webdriver.PhantomJS() #指定的PhantomJS浏览器创建浏览器对象
11 self.html = None
12 self.next_page = True
13 self.fund_url_list = []
14
15
16 #1 发起请求
17 def parser_url(self):
18 # if self.next_page :
19 # 点击页面进行翻页
20 # label[last()]---》定位到最后一个label,即<label value="xx">下一页</label>
21 # last()是一个函数,表示取最后一个
22 self.driver.find_element_by_xpath("//div[@id='pagebar']/label[last()]").click()
23 time.sleep(4) # 网页返回数据需要时间
24 self.html = self.driver.page_source
25
26
27 def parser_data_for_url(self):
28 '''从基金列表页获取每支基金的近一周收益和详情链接'''
29 # 解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象
30html = etree.HTML(self.html)
31 tr_list = html.xpath("//table[@id ='dbtable']//tbody/tr")
32 next_page = html.xpath("//div[@id ='pagebar']//label[last()]")
33 for tr in tr_list:
34 tds =tr.xpath("./td")
35 # 将近一周收益和详情链接组成的元组加入fund_url_list列表
36 self.fund_url_list.append((str(tds[8].text),str(tds[2].xpath("./a/@href")[0])))
37
38 return next_page # 返回下一页
39
40 #翻页控制器
41 def over_page(self,next_page):
42 # 获取最后一页
43 kw = next_page[0].xpath("./label[contains(@class,'end')]")
44 # print(kw)
45 # 判断是否是最后一页,如果是,则返回False,否则返回True
46 flag = True if len(kw)==0 else False
47 return flag
48
49 def get_every_fund_url(self, url, page):
50 # page:要获取前多少页的基金数据
51 # 1 发起请求
52 # 2 获取数据,解析数据
53 self.driver.get(url)
54 self.html = self.driver.page_source
55 # 当页数不为0且还有下一页时,执行下面的操作
56 while page > 0 and self.next_page:
57 next_page= self.parser_data_for_url()
58 # 4 翻页继续爬取
59 self.next_page = self.over_page(next_page)
60 # 如果不是下一页,就继续翻页
61 if self.next_page:
62 self.parser_url()
63 page -= 1
64 # 返回每支基金近一周收益和详情链接
65 return self.fund_url_list
66
67
68 def close_driver(self):
69 self.driver.quit()
70
71
72def save_data(data):
73
74 wb = Workbook() # 新创建一个文件
75 ws = wb.active # 获取当前正在运行的工作表/激活工作表
76 #将数据一行一行插入到工作表中
77 #列表第一个元素将作为标题
78 for i in data:
79 ws.append(i)
80 wb.save("近6月基金排名_" + time.strftime('%Y%m%d%H%M%S')+".xlsx")
81
82
83# 多进程任务函数
84# 获取进入基金的详情页获取详细信息
85def run(url, nearly_1_week):
86
87 driver = webdriver.PhantomJS()
88 driver.get(url)
89 page_html = etree.HTML(driver.page_source) # 获取页面源码
90 #获取基金名称
91 #通过xpath或者的是一个元素列表,要元素下面的子元素,需要取某个具体的元素,不能用列表取
92 fund_name =page_html.xpath("//div[@class='fundDetail-tit']/div/text()")[0]
93 #获取基金代码类名
94 fund_code_class_name = page_html.xpath("//div[@class='fundDetail-tit']/div/span[last()]/@class")[0]
95 #根据代码类名判断基金代码只有一个,还是有前后端两个
96 if fund_code_class_name == "ui-num":
97 fund_code = page_html.xpath("//div[@class='fundDetail-tit']/div/span[last()]/text()")[0]
98 elif fund_code_class_name == "fundcodeInfo":
99 fund_code_info = page_html.xpath("//div[@class='fundDetail-tit']/div/span[@class='fundcodeInfo']")[0]
100 fund_code = "前端: " +fund_code_info.xpath("./span[1]/text()")[0] + " 后端: " + fund_code_info.xpath("./span[2]/text()")[0]
101
102 #收益和净值所在的上层div
103 data_of_fund = page_html.xpath("//div[@class='dataOfFund']")[0]
104 #近1月
105 nearly_1_month =data_of_fund.xpath("./dl[1]/dd[2]/span[last()]/text()")[0]
106 #近1年
107 nearly_1_year =data_of_fund.xpath("./dl[1]/dd[3]/span[last()]/text()")[0]
108 #日期
109 date = data_of_fund.xpath("./dl[2]/dt/p/text()")[0]
110 date = re.findall(r"(\d{4}-\d{2}-\d{2})", date)[0] ifre.findall(r"(\d{4}-\d{2}-\d{2})", date) else ""
111 #单位净值
112 unit_net_worth =data_of_fund.xpath("./dl[2]/dd[1]/span[1]/text()")[0]
113 #日增长率
114 daily_growth_rate =data_of_fund.xpath("./dl[2]/dd[1]/span[2]/text()")[0]
115 #近3月
116 nearly_3_month =data_of_fund.xpath("./dl[2]/dd[2]/span[last()]/text()")[0]
117 #近3年
118 nearly_3_year =data_of_fund.xpath("./dl[2]/dd[3]/span[last()]/text()")[0]
119 #累计净值
120 accumulated_net =data_of_fund.xpath("./dl[3]/dd[1]/span[1]/text()")[0]
121 #近6月
122 nearly_6_month =data_of_fund.xpath("./dl[3]/dd[2]/span[last()]/text()")[0]
123 #基金成立日
124 since_established =data_of_fund.xpath("./dl[3]/dd[3]/span[last()]/text()")[0]
125 #获取基金类型,风险程度,规模等信息所在的上层vid
126 fund_info_item =page_html.xpath("//div[@class='infoOfFund']")[0]
127 #获取基金的类型以及风险程度
128 fund_type = fund_info_item.xpath(".//tr[1]/td[1]/a/text()")[0]
129 fund_risk =fund_info_item.xpath(".//tr[1]/td[1]/text()")[1].split()[-1].strip()
130 #获取基金规模
131 fund_scale =fund_info_item.xpath(".//tr[1]/td[2]/text()")[0].split(":")[-1]
132 #获取基金经理
133 fund_manager =fund_info_item.xpath(".//tr[1]/td[3]/a/text()")[0]
134 #获取基金成立日
135 establishment_date =fund_info_item.xpath(".//tr[2]/td[1]/text()")[0].split(":")[-1]
136 #获取管理人
137 administrator =fund_info_item.xpath(".//tr[2]/td[2]/a/text()")[0]
138 #获取评级类名
139 fund_rating_class_name =fund_info_item.xpath(".//tr[2]/td[3]/div/@class")[0]
140 data_list = []
141 #将每支基金的详细信息拼接成一个列表,并返回
142 data_list.append(str(fund_code))
143 data_list.append(str(fund_name))
144 data_list.append(str(date))
145 data_list.append(str(unit_net_worth))
146 data_list.append(str(accumulated_net))
147 data_list.append(str(daily_growth_rate))
148 data_list.append(str(nearly_1_week))
149 data_list.append(str(nearly_1_month))
150 data_list.append(str(nearly_3_month))
151 data_list.append(str(nearly_6_month))
152 data_list.append(str(nearly_1_year))
153 data_list.append(str(nearly_3_year))
154 data_list.append(str(since_established))
155
156 #根据评级所在divid的类名判断当前基金是几星
157 if fund_rating_class_name == 'jjpj1':
158 data_list.append("一星")
159 elif fund_rating_class_name == "jjpj2":
160 data_list.append("二星")
161 elif fund_rating_class_name == "jjpj3":
162 data_list.append("三星")
163 elif fund_rating_class_name == "jjpj4":
164 data_list.append("四星")
165 elif fund_rating_class_name == "jjpj5":
166 data_list.append("五星")
167 else:
168 data_list.append("暂无评级")
169
170 data_list.append(fund_type + " | " + fund_risk)
171 data_list.append(str(fund_scale))
172 data_list.append(str(fund_manager))
173 data_list.append(str(establishment_date))
174 data_list.append(str(administrator))
175
176 driver.quit() # 关闭浏览器
177 return data_list
178
179
180if __name__ == '__main__':
181
182 start = time.time()
183 #基金排行按近6月排行页面url
184 url ="http://fund.eastmoney.com/data/fundranking.html#tall;c0;r;s6yzf;pn50;ddesc;qsd20200725;qed20210725;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb"
185 tiantian = Tiantian_spider() # 实例化Tiantian_spider类
186 #获取每个基金的近1周收益和基金详情链接
187 #传入参数为排行页面url和要获取数据的总页数
188 url_list = tiantian.get_every_fund_url(url,4)
189
190 #要获取的数据,也作为保存excel的标题
191 data = [["基金代码", "基金简称", "日期", "单位净值", "累计净值", "日增长率", "近一周", "近1月", "近3月", "近6月", \
192 "近1年", "近3年", "成立来", "基金评级", "基金类型", "基金规模", "基金经理", "成立日", "管理人"]]
193
194 result = []
195 #multiprocessing.cpu_count():获取cpu核数
196 #新建一个进程池,最大放cpu核数个进程
197 pool = multiprocessing.Pool(multiprocessing.cpu_count())
198 for nearly_1_week, url in url_list:
199 # pool.apply_async:异步执行,10个任务同时执行
200 # 通过进程池来执行并发任务
201 # 进程池会自动找不同个数的进程来执行任务函数run, 将args=(url, nearly_1_week)中的url, nearly_1_week两个参数传入run函数
202 # .get()表示获取任务函数的返回值,即基金的详细信息
203 result.append(pool.apply_async(func=run, args=(url,nearly_1_week)).get())
204
205 pool.close() # 关闭进程池
206 pool.join() # 阻塞进程,所有进程池中的任务都执行完毕了,才能继续执行主进程
207 #将基金列表按基金的近6月收益率倒序排列后加入data
208 data.extend(sorted(result, key=lambda x:x[9], reverse=True))
209 save_data(data)
210 end = time.time()
211 print("耗时为:%s秒" % (end - start))
本文小练习爬取的数据均为公开数据,并且仅限于技术研究,不给网站造成负担。请大家在练习的时候注意合法合规!

最后: 大家可以去我公众号:伤心的辣条 ! 进去有许多资料共享!资料都是面试时面试官必问的知识点,也包括了很多测试行业常见知识,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。
好文推荐
转行面试,跳槽面试,软件测试人员都必须知道的这几种面试技巧!

















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









