







AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100+应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等干货。

AIGCmagic社区知识星球
截至目前,星球内已经累积了2000+AICG时代的前沿技术、干货资源以及学习资源;涵盖了600+AIGC行业商业变现的落地实操与精华报告;完整构建了以AI绘画、AI视频、大模型、AI多模态以及数字人为核心的AIGC时代五大技术方向架构,其中包含近500万字完整的AIGC
学习资源与实践经验。
论文题目:《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》
发表时间:2025年1月
论文地址:https://arxiv.org/pdf/2501.12948v1
本文作者:AIGCmagic社区 刘一手
DeepSeek-R1是一款具有显著特点和优势的大语言模型。
它在多个方面展现出强大的能力。首先,在知识储备上极为丰富,能够广泛涉猎各类领域知识,无论是科学常识、历史文化还是专业领域的信息,都能给出准确且详细的回答。其次,语言理解和生成能力出色,能精准理解用户的提问意图,生成自然流畅、逻辑连贯的文本内容,无论是撰写文章、解答问题还是进行对话交流,都能提供高质量的输出。再者,具备一定的推理和逻辑分析能力,对于复杂的逻辑问题或需要推理的任务,能够进行合理的分析和推导,给出有价值的见解。此外,DeepSeek-R1还在持续优化和改进中,不断提升自身的性能和表现,致力于为用户提供更加优质、高效的语言服务,在众多自然语言处理应用场景中都具有较高的实用价值。
研究背景
- 研究问题:这篇文章要解决的问题是如何通过强化学习(RL)提升大型语言模型(LLMs)的推理能力,特别是不依赖监督微调(SFT)的情况下。
- 研究难点:该问题的研究难点包括:如何在没有监督数据的情况下,通过纯强化学习提升模型的推理能力;如何提高模型的可读性和减少语言混乱。
- 相关工作:该问题的研究相关工作包括基于过程的奖励模型、强化学习和搜索算法等方法,但这些方法在推理性能上仍未达到OpenAI的o1系列模型的水平。
研究方法
这篇论文提出了DeepSeek-R1系列模型,通过大规模强化学习和多阶段训练来提升LLMs的推理能力。具体来说,
-
DeepSeek-R1-Zero:该模型直接在没有监督微调的情况下应用强化学习。采用Group Relative Policy Optimization(GRPO)算法进行训练,奖励模型主要包括准确性和格式奖励。训练模板要求模型先生成推理过程,再给出最终答案。
-
DeepSeek-R1:为了解决DeepSeek-R1-Zero的可读性和语言混乱问题,引入了冷启动数据和多阶段训练管道。首先,收集数千条冷启动数据对DeepSeek-V3-Base模型进行微调。然后,进行以推理为导向的强化学习,接着通过拒绝采样和SFT生成新的SFT数据,最后再次进行强化学习。
-
知识蒸馏:从DeepSeek-R1中蒸馏推理能力到较小的密集模型。使用Qwen2.5和Llama系列模型作为基础模型,通过简单的SFT蒸馏方法显著提升推理能力。
实验设计
- 数据收集:收集数千条冷启动数据,设计可读性的输出格式,过滤掉不友好的响应。
- 实验设置:DeepSeek-R1-Zero的训练采用规则基础的奖励系统,DeepSeek-R1则结合准确性和语言一致性奖励。使用多种基准测试进行评估,包括MMLU、DROP、GPQA Diamond、SimpleQA等。
- 样本选择:从RL训练中收集推理数据,通过拒绝采样和SFT生成新的SFT数据。非推理数据包括写作、事实问答和自我认知等领域。
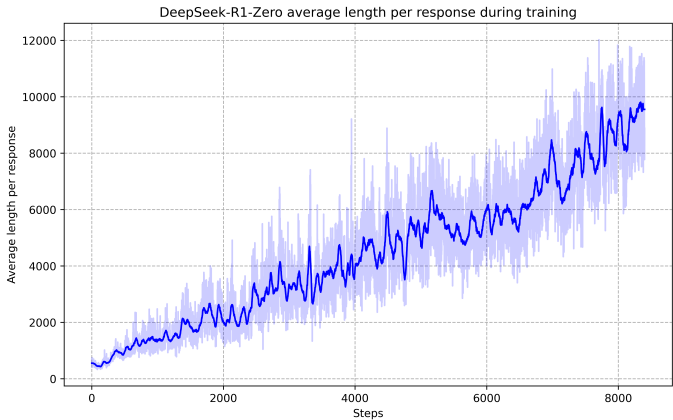
- 参数配置:设置最大生成长度为32,768个令牌,使用非零温度进行pass@1评估。
实验结果
-
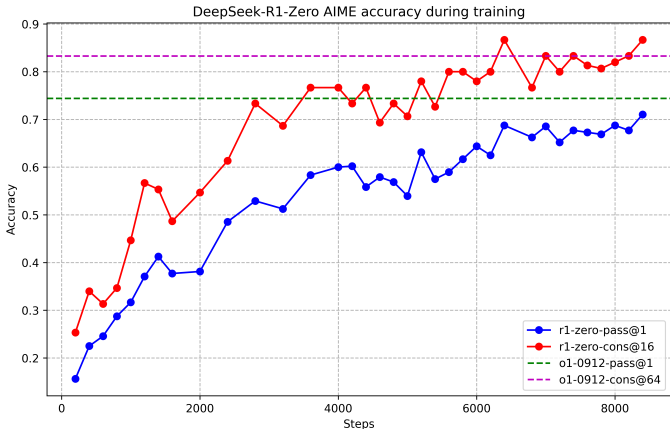
DeepSeek-R1-Zero:在AIME 2024上的pass@1得分从15.6%提升到71.0%,通过多数投票进一步提升到86.7%。在MATH-500上的pass@1得分为95.9%,接近OpenAI-o1-1217的水平。
-
DeepSeek-R1:在AIME 2024上的pass@1得分为79.8%,在MATH-500上的pass@1得分为97.3%,与OpenAI-o1-1217持平。在Codeforces上的rating为2029,显著优于96.3%的人类参与者。
-
蒸馏模型:DeepSeek-R1-Distill-Qwen-7B在AIME 2024上的pass@1得分为55.5%,超过QwQ-32B-Preview。DeepSeek-R1-Distill-Qwen-32B在AIME 2024上的pass@1得分为72.6%,在MATH-500上的pass@1得分为94.3%,在LiveCodeBench上的pass@1得分为57.2%。
论文结论
这篇论文通过大规模强化学习和多阶段训练,成功提升了LLMs的推理能力。DeepSeek-R1-Zero在没有监督微调的情况下,展示了强大的推理能力。DeepSeek-R1通过引入冷启动数据和多阶段训练,进一步提高了推理性能和可读性。通过知识蒸馏,成功将推理能力迁移到较小的密集模型,显著提升了这些模型的推理能力。
论文脑图

DeepSeek-R1创新点总结
- 纯强化学习的突破:DeepSeek-R1-Zero是第一个通过纯强化学习(RL)而不依赖监督微调(SFT)来提升语言模型推理能力的模型,标志着在这一领域迈出了重要一步。
- 多阶段训练管道:提出了包含两个RL阶段和两个SFT阶段的多阶段训练管道,旨在发现改进的推理模式并符合人类偏好。
- 冷启动数据的利用:通过引入冷启动数据,DeepSeek-R1在初期RL训练中表现更稳定,避免了基础模型的早期不稳定问题。
- 推理导向的强化学习:在冷启动数据的基础上,应用大规模推理导向的RL训练,显著提升了模型的推理能力。
- 拒绝采样和监督微调:在推理导向的RL收敛后,通过拒绝采样生成SFT数据,并结合监督数据进行进一步微调,提升了模型在所有场景下的表现。
- 知识蒸馏:展示了将大模型的推理模式蒸馏到小模型的有效性,显著提升了小模型在推理任务上的表现。
- 开源模型:开源了DeepSeek-R1-Zero、DeepSeek-R1及其基于Qwen和Llama的六个密集模型(1.5B, 7B, 8B, 14B, 32B, 70B),促进了研究社区的进一步发展。
DeepSeek-R1关键问题解答
问题1:DeepSeek-R1-Zero模型在推理任务中的表现如何?其自我进化过程有哪些亮点?
DeepSeek-R1-Zero模型在没有监督微调的情况下,通过大规模强化学习展示出了显著的推理能力。具体来说,在AIME 2024上的pass@1得分从15.6%提升到71.0%,通过多数投票进一步提升到86.7%。在MATH-500上的pass@1得分为95.9%,接近OpenAI-o1-1217的水平。此外,DeepSeek-R1-Zero还展示出了一些令人印象深刻的自我进化行为,如自我验证、反思和生成长链的推理过程(Chain of Thought, CoT)。这些行为是自发的,而不是显式编程的,显著增强了模型的推理能力。
问题2:DeepSeek-R1模型如何解决DeepSeek-R1-Zero模型的可读性和语言混乱问题?
DeepSeek-R1模型通过引入冷启动数据和多阶段训练管道来解决DeepSeek-R1-Zero模型的可读性和语言混乱问题。首先,收集数千条冷启动数据对DeepSeek-V3-Base模型进行微调,设计可读性的输出格式,过滤掉不友好的响应。然后,进行以推理为导向的强化学习,接着通过拒绝采样和SFT生成新的SFT数据,最后再次进行强化学习。这些步骤不仅提高了模型的可读性,还减少了语言混乱现象,使得模型生成的回答更加清晰和连贯。
问题3:DeepSeek-R1模型在蒸馏过程中是如何提升较小密集模型的推理能力的?
DeepSeek-R1模型通过简单的SFT蒸馏方法显著提升较小密集模型的推理能力。具体来说,使用Qwen2.5和Llama系列模型作为基础模型,直接从DeepSeek-R1中蒸馏推理能力。蒸馏后的模型在多个推理基准测试中表现出色,例如DeepSeek-R1-Distill-Qwen-7B在AIME 2024上的pass@1得分为55.5%,超过QwQ-32B-Preview。DeepSeek-R1-Distill-Qwen-32B在AIME 2024上的pass@1得分为72.6%,在MATH-500上的pass@1得分为94.3%,在LiveCodeBench上的pass@1得分为57.2%。这些结果表明,蒸馏是一种有效的方法,可以将大模型的推理能力迁移到小模型中。
推荐阅读
AIGCmagic社区介绍:
2025年《AIGCmagic社区知识星球》五大AIGC方向全新升级!
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之模态生成器:Modality Generator
AI多模态实战教程:
AI多模态教程:从0到1搭建VisualGLM图文大模型案例
AI多模态教程:Mini-InternVL1.5多模态大模型实践指南
AI多模态实战教程:面壁智能MiniCPM-V多模态大模型问答交互、llama.cpp模型量化和推理
交流社群
加入「AIGCmagic社区」,一起交流讨论:
AI视频、AI绘画、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向;
可私信或添加微信号:【lzz9527288】,备注不同方向邀请入群;
更多精彩内容,尽在「AIGCmagic社区」,关注了解全栈式AIGC内容!


















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









