




 文章介绍了如何使用Python库和OCR技术,如tesseract、pytesseract以及poppler,来批量识别PDF文件中图片格式的文本。首先安装必要的软件和库,然后通过pdf2image转换PDF页面为PNG图片,再用pytesseract进行文字识别,最终将识别出的中文文本保存为文件。
文章介绍了如何使用Python库和OCR技术,如tesseract、pytesseract以及poppler,来批量识别PDF文件中图片格式的文本。首先安装必要的软件和库,然后通过pdf2image转换PDF页面为PNG图片,再用pytesseract进行文字识别,最终将识别出的中文文本保存为文件。
有些PDF页面是图片格式,要怎么批量把图片中的文字识别出来?借助ChatGPT可以轻松完成这个任务。
首先要安装一些相关的软件和Python库。
安装tesseract-ocr(OCR)软件,最新版的是tesseract-ocr-w64-setup-v5.3.0.20221214.exe ,下载地址是https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.3.0.20221214.exe
要从图片中识别字符,就得使用光学字符识别(OCR)技术。
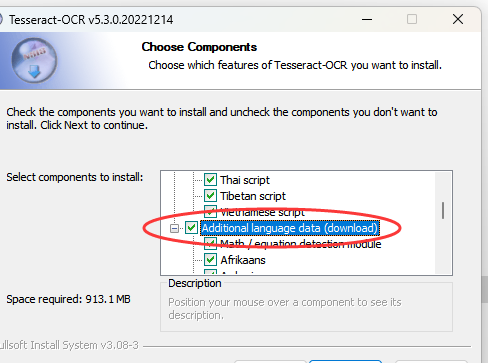
注意安装中文字库。
然后把D:\Program Files (x86)\TesseractOCR 添加到环境变量。
安装OCR库::pip install pytesseract
安装poppler-windows软件。Poppler 是一个用来生成 PDF 的 C++ 类库,从 xpdf 继承而来。它使用了很多先进的类库例如 freetype 和 cairois 来达到更好的输出效果,同时也提供了一组命令行工具包。下载地址:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2433
2433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









