




来源 | 机器之心
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批
「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。然而,这些方法的学习任务分布仍由人类预先设计,所依赖的数据依旧高度依赖专家精心策划与大量人工标注,面临着难以扩展与持续演化的瓶颈。
更重要的是,如果智能系统始终受限于人类设定的任务边界,其自主学习与持续进化的潜力将受到根本性限制,这一现实呼唤一种全新的推理范式,迈向超越人类设计约束的未来。
为应对这一挑战,清华大学 LeapLab 团队联合北京通用人工智能研究院 NLCo 实验室和宾夕法尼亚州立大学的研究者们提出了一种全新的推理训练范式 ——Absolute Zero,使大模型无需依赖人类或 AI 生成的数据任务,即可通过自我提出任务并自主解决,实现「自我进化式学习」。在该范式中,模型不仅学习如何生成最具可学习性的任务(maximize learnability),还通过解决这些自主生成的任务持续增强自身的推理能力。Absolute Zero 范式不仅在性能上表现卓越,其核心理念更在于推动推理模型从依赖人类监督向依赖环境监督的范式转变,使模型通过与真实环境的交互生成可验证的任务并获得可靠反馈,从而不断提升自身的推理能力。
在这一范式下,研究团队训练了新的模型 Absolute Zero Reasoner(AZR),以代码执行器作为真实环境,自动生成并解决三类代码推理任务,涵盖归纳、演绎与溯因推理,依赖环境可验证的反馈实现稳定训练。实验表明,虽然未见过目标任务,AZR 在代码生成与数学推理这两个跨领域基准任务中表现出色,并且超越已有的方法达到 SOTA。这一成果不仅显著缓解了当前大模型训练对高质量人工数据的依赖难题,也预示着推理模型正迈入一个具备「自主进化」的智能新时代。

-
论文标题:Absolute Zero: Reinforced Self-play Reasoning with Zero Data
-
论文链接:https://www.arxiv.org/abs/2505.03335
-
展示页面:https://andrewzh112.github.io/absolute-zero-reasoner/
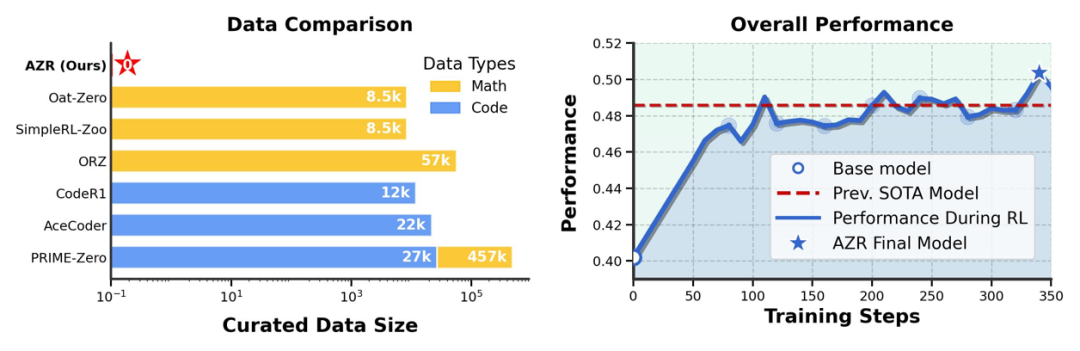
Absolute Zero Reasoner 在零数据的条件下实现了数学和代码推理 benchmark 上的 SOTA 性能。该模型完全不依赖人工标注或人类预定义的任务,通过研究团队提出的 self-play 训练方法,展现出出色的分布外推理能力,甚至超越了那些在数万个专家标注样本上训练而成的 reasoning 模型。
推理新范式:Absolute Zero,让模型真正摆脱人类数据依赖
在当前的大模型训练中,监督微调(SFT)是常见的推理能力对齐方法,依赖人类专家提供的问题、推理过程(即 Chai
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3166
3166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









