



来源 | 机器之心
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:
-
流程复杂、涉及模块多(生成、训练、奖励判定等),为实现高效稳定的分布式训练带来很多挑战;
-
R1/o1 类推理模型的输出长度很长(超过 10K),并且随着训练持续变化,很容易造成显存和效率瓶颈;
-
开源社区缺乏高质量强化学习训练数据,以及完整可复现的训练流程。
本周,蚂蚁技术研究院和清华大学交叉信息院吴翼团队,联合发布了训练速度最快最稳定的开源强化学习训练框架 AReaL(Ant Reasoning RL),并公开全部数据和完成可复现的训练脚本。在最新的 AReaL v0.2 版本 AReaL-boba 中,其 7B 模型数学推理分数刷新同尺寸模型 AIME 分数纪录,并且仅仅使用 200 条数据复刻 QwQ-32B,以不到 200 美金成本实现最强推理训练效果。
-
项目链接:https://github.com/inclusionAI/AReaL
-
HuggingFace数据模型地址:https://huggingface.co/collections/inclusionAI/areal-boba-67e9f3fa5aeb74b76dcf5f0a
关于 AReaL-boba
AReaL 源自开源项目 ReaLHF,旨在让每个人都能用强化学习轻松训练自己的推理模型和智能体。AReaL 承诺完全开放与可复现,团队将持续发布与训练 LRM 相关的所有代码、数据集和训练流程。所有核心组件全部开源,开发者可无阻碍地使用、验证和改进 AReaL。
本次最新版本「boba」的命名一方面源自团队对珍珠奶茶的偏爱,另一面也是希望强化学习技术能如奶茶成为大众饮品一般,渗透至 AI 开发的每个日常场景,普惠整个社区。
AReaL-boba 发布亮点
训练速度最快的开源框架
AReaL-boba 是首个全面拥抱 xAI 公司所采用的 SGLang 推理框架的开源训练系统,对比初代 AReaL 训练大幅度提升训练吞吐:通过集成 SGLang 框架及多项工程优化,AReaL-boba 可以无缝适配各种计算资源下的强化学习训练,实现吞吐在 1.5B 模型尺寸上速度提升 35%,在 7B 模型速度提升 60%,32B 模型速度提升 73%。
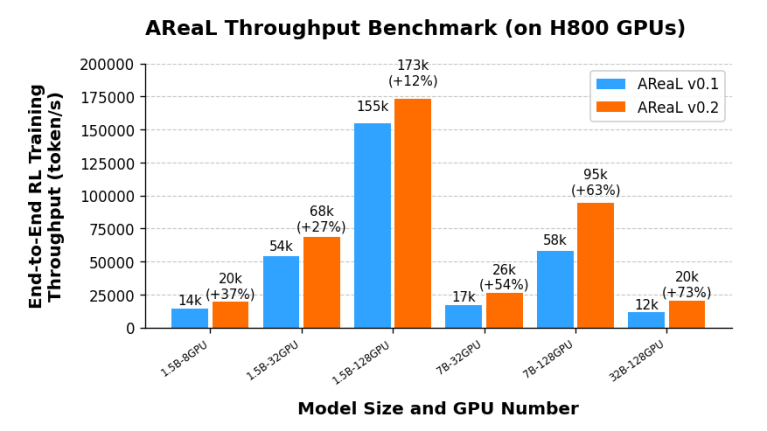
图 1:AreaL-boba 对比初代 AReaL 训练大幅度提升训练吞吐
使用 AReaL-boba 即可以 128 张 H800 规模在 1 天内训练完成 SOTA 1.5B 推理模型,以 256 张 H800 规模在 2 天内完成 SOTA 7B 推理模型训练。
AReaL 希望让整个社区不论单机器,还是大规模分布式训练,都可以轻松高效率驾驭强化学习。
7B 模型数学推理分数断崖领先
AReaL 团队以 Qwen-R1-Distill-7B 模型为基础模型,通过大规模强化学习训练,即可在 2 天内取得领域最佳的数学推理能力,实现 AIME 2024 61.9 分、AIME 2025 48.3 分,刷新开源社区记录,也大幅超越了 OpenAI o1-preview。相比基础模型,AReaL-boba 通过强化学习让模型能力实现跃升 —— 在 AIME 2024 上提升 6.9 分,在 AIME 2025 提升 8.6 分 —— 再次证明了 RL Scaling 的价值。
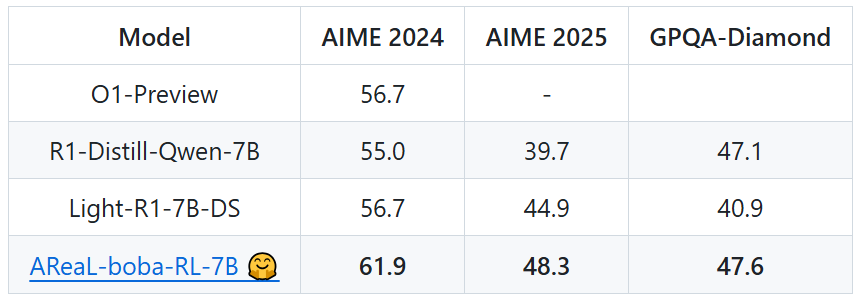
表 1: 同类参数模型的不同基准测试分数
同时 AReaL-boba 不仅开源了推理模型,也开源所有的训练数据 AReaL-boba-106k,以及全部的训练脚本和评估脚本,确保人人可复现。在项目官方仓库上,AReaL 团队也放出了极其详细的技术笔记,总结了大量训练中的关键点,包括 PPO 超参数、奖励函数设置、正则化设置、长度上限设置等等。
通过创新性数据蒸馏技术,200 条数据复现 QwQ-32B
在 32B 模型尺寸上,AReaL 团队进一步精简训练数据并发布数据集 AReaL-boba-SFT-200 以及相关训练脚本。基于 R1-Distill-Qwen-32B,AReaL-boba 使用仅仅 200 条数据并以轻量级 SFT 的方式,在 AIME 2024 上复刻了 QwQ-32B 的推理结果,相当于仅仅使用了 200 美金的计算成本,让所有人都可以以极低的成本实现最强的推理训练效果。
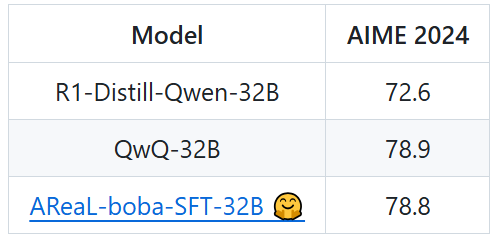
表 2:同类参数模型的 AIME 2024 分数
结语
AReaL 团队的核心成员均来自于蚂蚁研究院强化学习实验室以及交叉信息研究院吴翼团队,项目也借鉴了大量优秀的开源项目,比如 DeepScaleR、SGLang、QwQ、Open-Reasoner-Zero、OpenRLHF、veRL、Light-R1 和 DAPO。作为国内第一个完整开源(数据、代码、模型、脚本全开源)的强化学习项目团队,AReaL 希望能真正实现 AI 训练的普惠。
AReaL 团队在项目列表中也列出了团队后续的开源计划和目标,包括异步训练、训练吞吐优化、数据集和算法升级,以及代码和 Agent 智能体能力支持。让我们期待 AReaL 团队的下一个 release,猜猜是哪一款奶茶呢?

















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









