 Salesforce多样性筛选提升RAG效果
Salesforce多样性筛选提升RAG效果




为什么大模型需要学会"挑食"?
在开发大语言模型应用时,我们常常遇到这样的困境:面对海量文本数据,模型就像面对满汉全席的新手食客,既想品尝所有美味,又受限于"胃容量"(上下文窗口)。这种限制主要源自 Transformer 架构的自注意力机制——每增加一个 token,计算量就会呈平方级增长。就像用 1000 块拼图拼一幅画,每增加一块新拼图,都需要和之前所有 999 块比对位置。
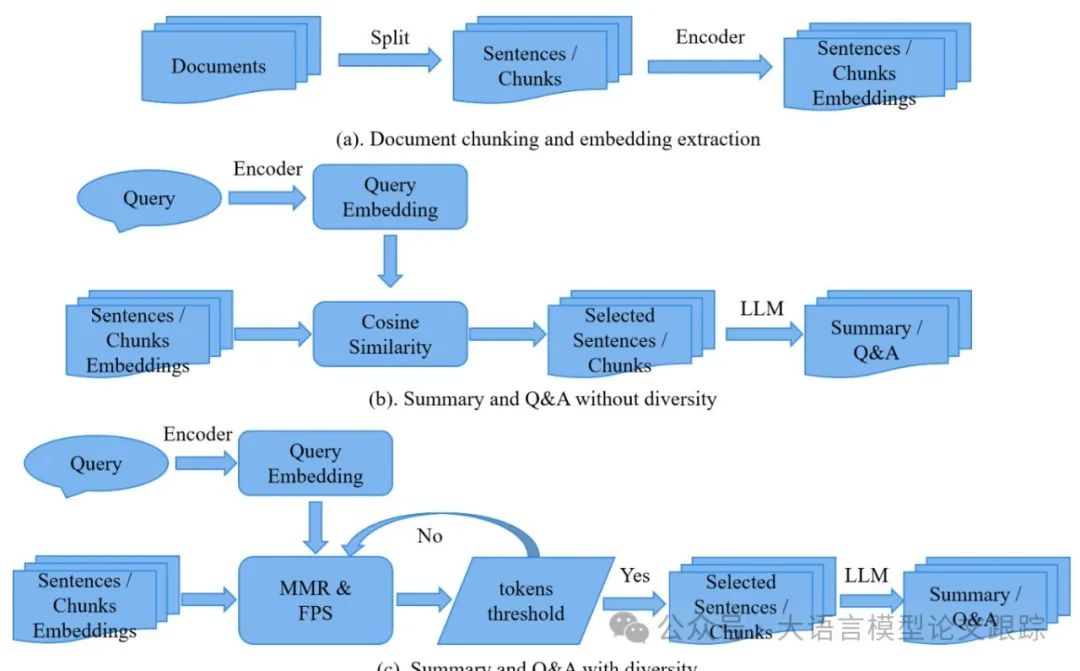
尽管 GPT-4 已经能将"胃容量"扩展到 12.8 万 token,但现实应用中的挑战依然严峻。想象你要开发一个法律咨询系统,需要同时处理上百份判例文书;或者开发医疗诊断助手,要分析患者长达十年的就诊记录。传统解决方案就像让食客只挑看起来最诱人的菜肴,但往往导致营养失衡——过度选择相似内容,漏掉关键信息。
多样性筛选:大模型的营养师
这时候就需要引入"营养师"角色——多样性筛选算法。它们的核心思想就像米其林餐厅的品鉴流程:既要保证食材品质(相关性),又要讲究菜品搭配(多样性)。目前主流的两种"营养搭配法"是:
1. 最大边际相关(MMR):精准的膳食平衡
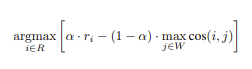
MMR 算法的工作方式就像米其林大厨选食材。假设要为贵宾准备 8 道菜的套餐,主厨会:
-
1. 先选最符合客人偏好的主菜(比如龙虾)
-
2. 接着选与主菜搭配又能带来新味觉体验的辅菜(比如用松露而非普通蘑菇)
-
3. 持续平衡"客人喜好"和"菜单多样性"
数学公式中的 α 参数就像口味调节旋钮:α=0.7 时更注重菜品质量,α=0.3 时强调菜品多样性。在实际开发中,我们通过实验发现将 α 设置在 0.6-0.7 之间,能在问答任务中取得最佳效果。
2. 最远点采样(FPS):聪明的空间布局
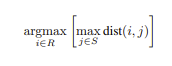
FPS 算法源自 3D 点云处理,其原理就像城市规划师选址:
-
1. 随机选择第一个消防站位置
-
2. 第二个选址离第一个最远
-
3. 第三个选址离前两个最远的位置
-
4. 以此类推确保全面覆盖
当应用于文本选择时,这种策略能有效避免信息扎堆。比如处理医疗报告时,传统方法可能会重复选择"血压升高"的相关描述,而 FPS 能同时保留"心电图异常"、"肾功能指标"等不同维度的关键信息。
为什么多样性筛选能创造奇迹?
在我们的实验中,采用多样性筛选带来了三大突破性提升:
1. 召回率提升
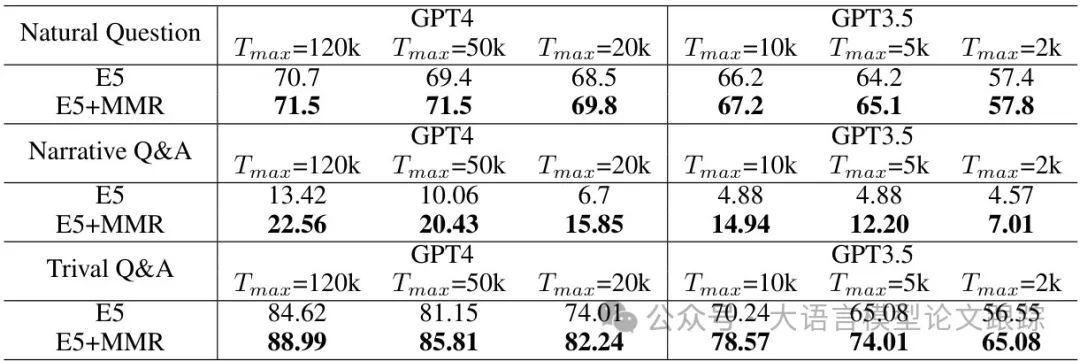
在长文本问答(Q&A)任务中,传统方法倾向于选择与查询相似度最高的内容,但这种方式容易导致信息冗余或遗漏关键细节。
通过引入最大边际相关(MMR)和最远点采样(FPS) 两种多样性筛选策略,显著提升了候选内容的召回率。
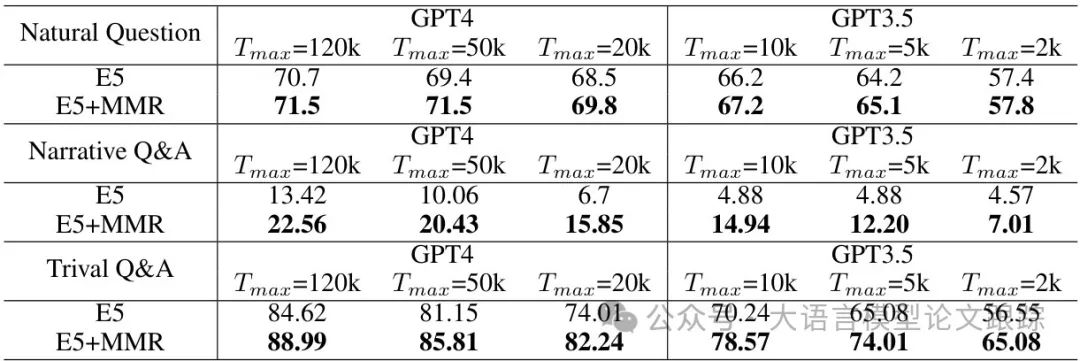
实验显示,在单文档问答任务中,MMR和FPS相比基准方法(SB)的召回率提升了2%-5%;
在多文档问答任务中,MMR结合E5模型后,答案在检索文档中的召回率提升超过10%。
这种改进源于多样性筛选能覆盖更广泛的语义空间,减少重复内容的干扰,确保关键信息不被遗漏。
2. 推理延迟降低 40%
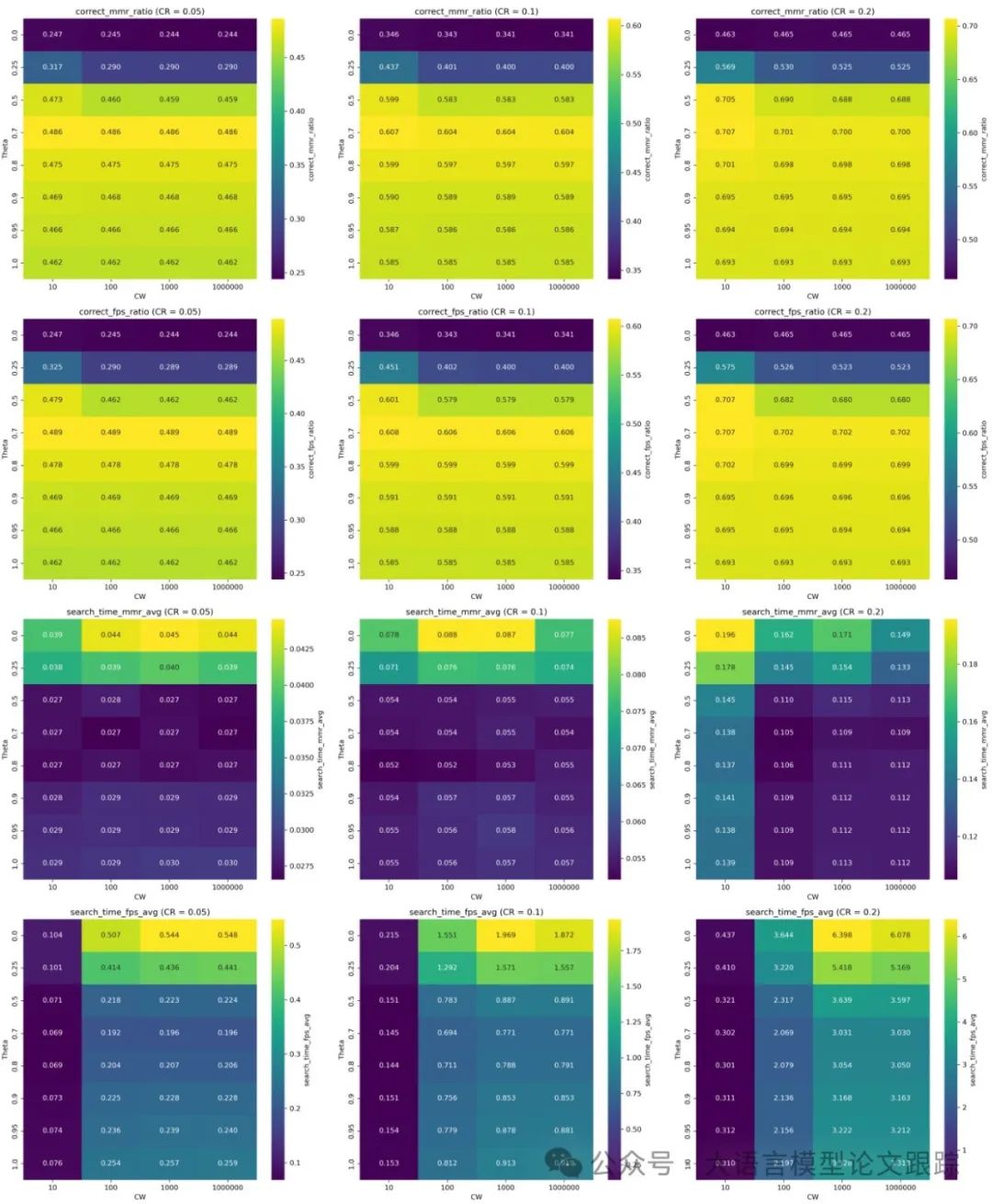
尽管MMR和FPS均能提升召回率,但两者的计算效率差异显著。实验发现,MMR的延迟远低于FPS,尤其是在处理长上下文时。例如,在自然问题(Natural Question)数据集上,当压缩比为0.2时,MMR的延迟仅为FPS的1/3。这一优势源于MMR采用余弦相似度计算,而FPS依赖欧氏距离,后者计算复杂度更高。此外,MMR支持动态调整超参数(如窗口大小和权重),进一步优化了实时性能。因此,MMR更适合实际应用场景,尤其是需要快速响应的工业级系统。
3. 内容顺序的隐藏价值
内容的排列顺序对LLM的理解能力影响深远。研究发现,保持句子在原文中的顺序(index sort) 能显著提升问答准确率。
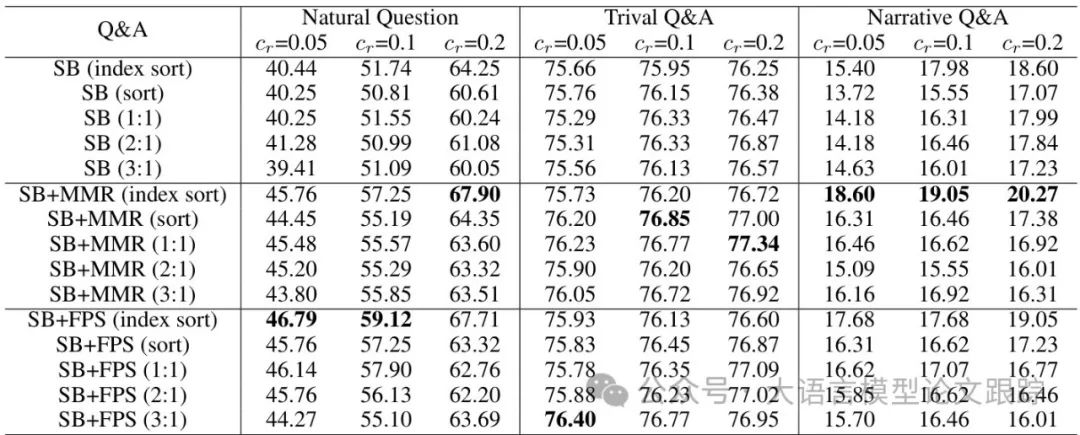
例如,在单文档问答任务中,保持原始顺序的MMR方法(SB+MMR index sort)相比乱序版本的性能高出3%-5%(如上图)。
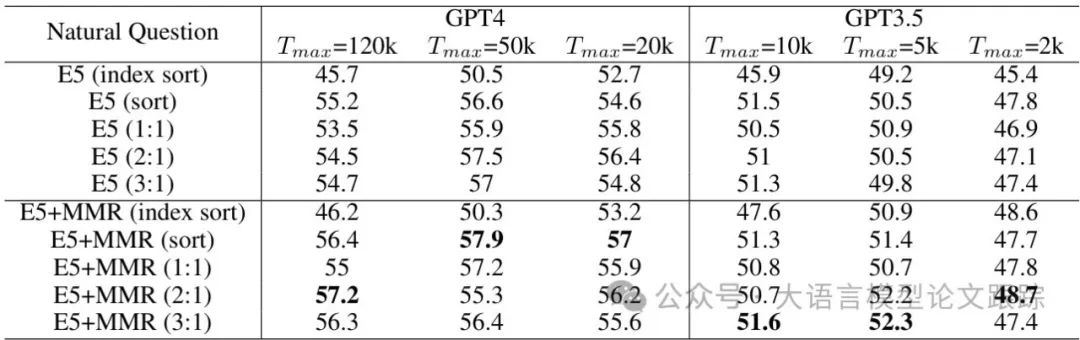
而对于分块(chunk)内容,将关键块置于提示的开头或结尾可进一步提升LLM的注意力(如上图),这与“Lost in the Middle”现象一致——模型容易忽略中间位置的信息。
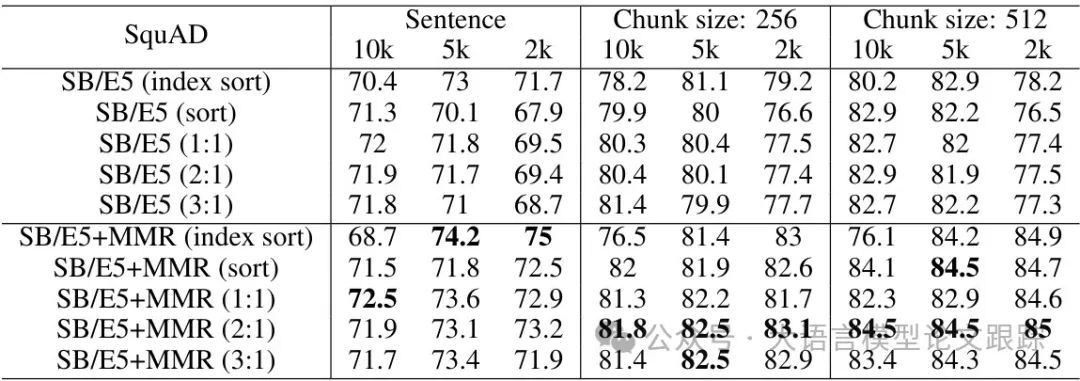
此外,分块大小也影响效果:512词块的表现优于256词块和句子级分割(表7),说明适度的上下文连贯性对模型推理至关重要。
实践指南
在实际应用中,总结了三大黄金法则:
1. 参数调优四步法
-
• 第一步:确定基线 α=0.5
-
• 第二步:以 0.1 为步长进行网格搜索
-
• 第三步:验证集上评估召回率和生成质量
-
• 第四步:根据任务类型微调(问答任务建议 α=0.6,摘要任务 α=0.55)
2. 混合策略配置
对于超长文本处理,可以采用分级筛选:
-
• 1.第一级用 FPS 快速粗选(窗口大小 100)
-
• 2.第二级用 MMR 精准筛选(窗口大小 10)
-
• 3.最终按原文顺序+相关性分数排序
3. 避免的五个陷阱
-
• 1.盲目追求最大多样性(α<0.4 会导致信息偏离)
-
• 2.忽视 embedding 模型的质量(建议使用 bge-large-v1.5)
-
• 3.混合不同来源文档时未做归一化处理
-
• 4.固定窗口大小不调整(建议动态设置:窗口大小=总 token 数/50)
-
• 5.忽略内容顺序的影响(特别是时序性文档)
未来演进方向
三个重要趋势:
-
• 1.动态多样性调节:根据上下文复杂度自动调整 α 参数
-
• 2.多模态扩展:将图像特征纳入多样性考量
-
• 3.自监督微调:让模型自主生成多样性评估信号
站在开发者的角度,理解这些原理不仅能够优化现有系统,更能为设计新一代语言模型提供启发。就像优秀的厨师懂得食材搭配的艺术,聪明的开发者需要掌握信息筛选的平衡之道。将人类的信息处理智慧编码进算法,大模型才能真正成为称职的"信息美食家"。
来源 | 大语言模型论文跟踪

















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









