




作者:榴莲酥
原文:https://zhuanlan.zhihu.com/p/21267744516
一句话:大模型界的拼夕夕,模型本身确实也有创新点,比如MLA、纯RL预训练、FP8混合精度,但更重要的是让我们看到了开源对闭源的生态挑战、中国对美国主导的有效追赶、极致工程优化的显著受益。
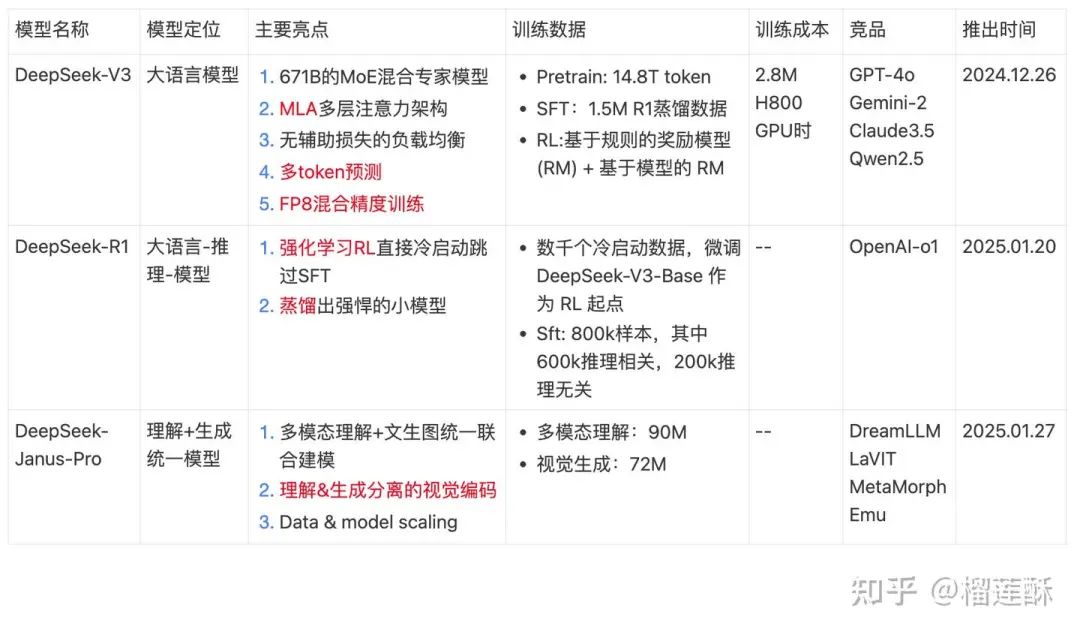
DeepSeek-V3
https://github.com/deepseek-ai/DeepSeek-V3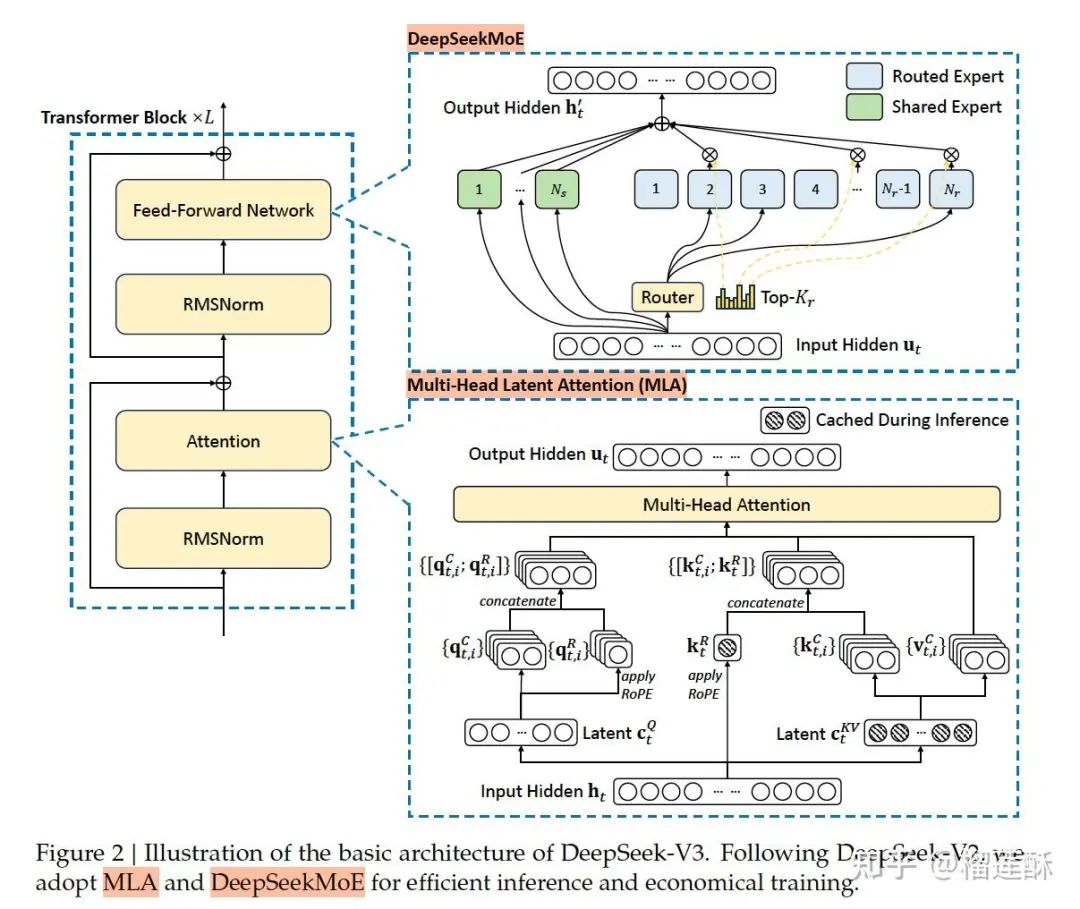
DeepSeekV3模型结构
基础架构
1. MoE结构:
混合专家模型:三个臭皮匠胜于诸葛亮的思想,基本上目前各大模型都在用。简单来说就是包含多个“专家”网络,其中每个专家都是一个相对独立的神经网络,都有各自的参数,每个擅长于处理特定类型的输入或者在数据的某个子空间上表现良好。通过门控网络(Gating Network)调整权重,把不同的输入按照概率路由给不同的专家网络。各个专家网络对分配到的输入进行处理,产生各自的输出,最后根据门控网络分配的权重,将这些专家网络的输出进行组合,得到最终的输出结果。
优点:可以在不显著增加模型整体参数量的情况下,利用多个专家网络的并行处理能力来处理不同类型的输入模式,比如这里DeepSeekV3一共671B参数,实际每个token推理激活的37B的参数就行。
DeepSeekMoE: 使用了更细粒度的专家,并将一些专家隔离为共享专家,这里的Topk就是由第 位 token 和所有路由专家计算出的Affinity得分中最高的 个分组成的集合。

2. MLA (Multi-head Latent Attention) 多层潜注意力架构:
注意力机制:神经网络中的一种重要技术,它允许模型聚焦于输入数据的不同部分。在传统的注意力机制中,模型会计算输入元素之间的关联权重,然后根据这些权重对输入进行加权组合。
多头Multi-head:每个注意力头可以学习到输入数据不同方面的表示。例如,在处理自然语言处理任务中的一个句子时,一个注意力头可能聚焦于句子中的语法结构,另一个可能聚焦于语义信息,还有一个可能关注于词汇的情感倾向等。这些不同的注意力头并行工作,最后将它们的结果进行组合。
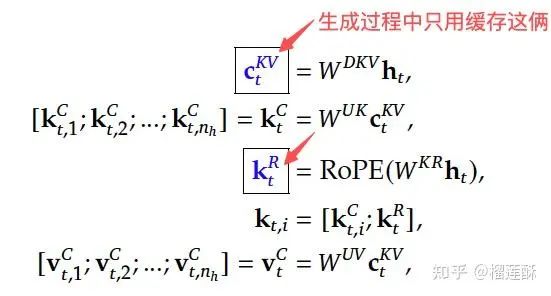
MLA是DeepSeek这里新提出的,核心是对注意力 key 和 value 进行低秩联合压缩,这样在生成过程中只需要缓存映射到潜空间的这两个蓝框向量,从而显著减少键值 (KV) 缓存。
3. 无辅助损失的负载均衡 auxiliary-loss-free strategy:
传统:对于 MoE 模型,不平衡的专家负载会导致路由崩溃,并在具有专家并行的场景中降低计算效率。传统解决方案通常依靠辅助损失来避免负载不平衡,但是过大的辅助损失会损害模型性能。
无辅助损失的负载平衡策略:目标是在负载平衡和模型性能之间取得更好的平衡,这里的方法是为每个专家引入一个偏差项 ,并将其添加到相应的affinity分数 , 中以确定topK 的路由:
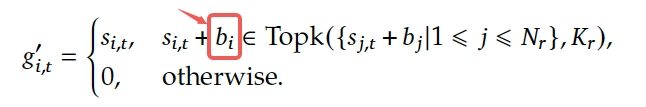
注意这里的偏差项仅用于路由,与 FFN 输出相乘的门控值仍然来自原始affinity得分 , 。在训练期间持续监控每个训练step对应的整个batch上的专家负载。在step
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









