 ReFT、Kimi K1.5与DeepSeek R1推理模型实现解析
ReFT、Kimi K1.5与DeepSeek R1推理模型实现解析






知乎:姜富春(已授权)
链接:https://zhuanlan.zhihu.com/p/20356958978
引言
最近Reasoning Model(推理模型)异常火爆,Kimi 和 DeepSeek 陆续推出自家的产品K1.5和R1,效果追评甚至超过o1,也引起了大家的关注,甚至OpenAI也慌了。我也第一时间体验了下产品的效果,推理能力确实惊艳。也非常好奇到底用了什么技术。国内的LLM开源玩家算是比较良心的,模型开源的同时,一些技术细节也都发表出来,也能进一步解答大家的好奇心。
过年期间正好忙里偷闲,可以静下来好好整理下这块内容。我个人认为主要有三篇工作比较清晰的讲述了Reasoning Model的探索过程,分别是:字节的ReFT、Kimi的K1.5和DeepSeek的R1。看完总结下来:大家方法趋同,核心都是在Post-Training阶段通过RL(Reinforcement learning)提升模型的推理能力。这也不禁让人感叹,Reasoning Model看似o1放出的杀手锏,"国产之光"的复现竟可以做到如此精巧、简洁。
在介绍3篇工作前,我也想按自己的理解先来介绍一些早期的o1的猜想。也方便与本文要介绍的工作做些对比,也好理解为什么说复现的工作是精巧、简洁的~
1. Reasoning Model的早期猜想
自从OpenAI发布o1模型后,让我们体验到LLM在复杂问题的推理能力上的进步。Reasoning Model(推理模型)的复现之路也成为各家大模型追捧的热点。在猜想和复现的过程中,试图从OpenAI、Google、微软的近期的研究中找到一些蛛丝马迹,其中主流的一些猜测集中在使用PRM和MCTS方法,在Post-training和Inference阶段提升推理性能。
我们简单看下使用PRM和MCTS方法是如何提升推理性能的?
1.1. PRM增强推理能力
PRM(Process-supervised Reward Model)是OpenAI在Let’s Verify Step by Step(https://arxiv.org/pdf/2305.20050)一文中首次提出的概念。与之相对应的是ORM(Outcome-supervised Reward Model)。PRM和ORM都是奖励模型,两者区别:
-
PRM:过程奖励模型,是在生成过程中,分步骤,对每一步进行打分,是更细粒度的奖励模型。
-
ORM:结果奖励模型,是不管推理有多少步,对完整的生成结果进行一次打分,是一个反馈更稀疏的奖励模型。
使用PRM可以在Post-Training和Inference两阶段提升模型的推理性能。
-
Post-Training阶段:在偏好对齐阶段,通过在RL过程中增加PRM,对采样的结果按步骤输出奖励值,为模型提供更精细的监督信号,来指导策略模型优化,提升模型按步推理的能力。
-
Inference阶段:对于一个训练好的PRM,可以在Inference阶段来筛选优质生成结果。具体来说。对generator模型做N次采样(如Beam Search方法等),并通过PRM对每个采样的每步推理进行打分,最终拟合一个整体过程打分,并选取打分最高的结果作为最终的答案。
这里我们假设基础的generator模型在pretrain后做了指令微调(SFT),有基本的推理能力(能按步骤生成答案,但推理准确性可能较差)
1.2. MCTS增强推理能力
MCTS(Monte Carlo Tree Search)是强化学习领域提出的方法,通过采样方式预估当前动作或状态的价值。具体操作步骤:使用已有的策略与环境做仿真交互,进行多次rollout采样,最终构成了一个从当前节点出发的一颗Tree(每个rollout表示从当前节点到最终结束状态的多次与环境仿真交互的过程)。这颗Tree的所有叶子节点都是结束状态,结束状态是能量化收益的(量化收益的方法:比如方法1:答案错误收益-1, 答案正确收益 +3;再比如方法2:叶子节点的收益是到达叶子节点路径数/总路径数的概率,这是一种根据投票机制预估的价值,越多路径到达叶子节点,说明这个叶子节点越置信,那么这个叶子节点就有更高的奖励)。一颗Tree的叶子节点有了奖励值,就可通过反向传播,计算每个中间节点的奖励值,最终计算出整个Tree所有节点的奖励值。MCTS一次rollout包括:select,expand,simulate,backprop四个步骤。我们展开描述下四个步骤的具体工作。
-
Sample(采样) :选择一个未被探索的节点,在Reasoning Model中节点表示一个打了特定tag的推理步骤(如:planning 节点,reflection节点等)。初始情况,Tree只有一个表示原始问题的节点(如下图1的)。
-
expand(扩展) :从未被选择的节点出发(如初始从),展开所有可能的子节点(如下图1中的)。当然对于文本生成模型不可能穷举所有的子节点,需要设置个最大生成次数,在有限生成次数内的所有的不同的输出,认为是子节点的集合。
-
simulate(模拟) :从展开的子节点里,再随机选择一个节点,再展开它的子节点,重复做expand过程。直到最终到达叶子节点(生成答案)。当然这里也会控制最大树深度,模拟会进行N次。
-
backprop(回传) :通过多次模拟我们得到了一个从根节点(原始问题)到叶子节点(最终生成答案)的Tree,如下图1所示。我们通过计算(从当前节点出发到正确答案的路径数/从当前节点出发总路径数)的比值作为节点的奖励值。这个奖励值隐含表示的是从当前节点出发能得到正确答案的潜在的可能性。比如以节点为例,从出发共有4条路径,分别是:<>,<>,<>,<>,其中有2条路径都能走到正确答案。所以的奖励值为1/2。我们通过从后往前回溯,能计算出Tree中所有节点的奖励值。
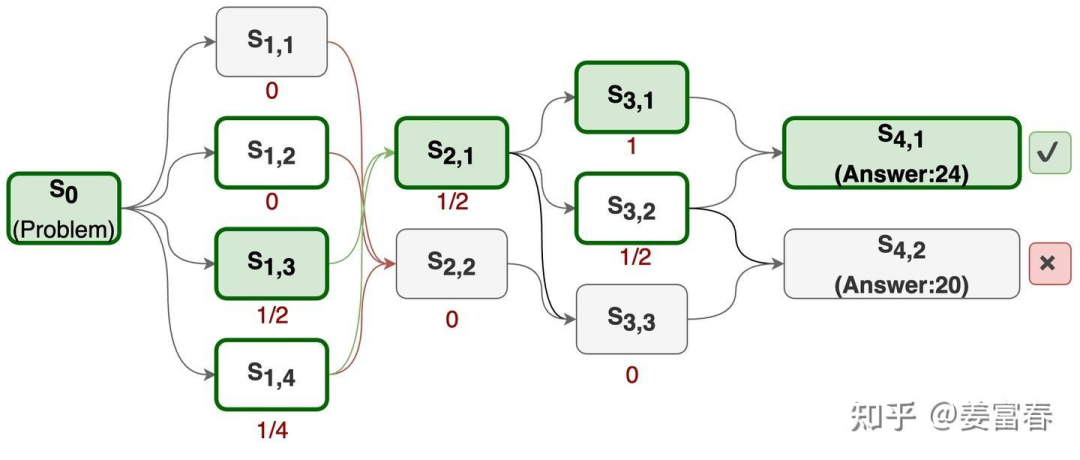
图1、MCTS 生成Search Tree过程
使用MCTS提升模型的推理能力,也可在Post-Training和inference两阶段来实现。
-
Post-Traing阶段:对于每个problem 通过上述方法构造一个搜索Tree,然后进行Tree的游走遍历采样,再用采样的样本SFT或RL训练模型。
-
Inference阶段:在推理阶段,也是对一个problem探索多节点构造一颗搜索Tree,对于到达正确答案的路径,根据节点路径的置信度打分,贪心选取最优路径作为最终的推理结果。
使用PRM和MCTS训练推理模型的大致框图,如图2所示,主要是在Post Training和Inference阶段使用来提升模型的推理能力。
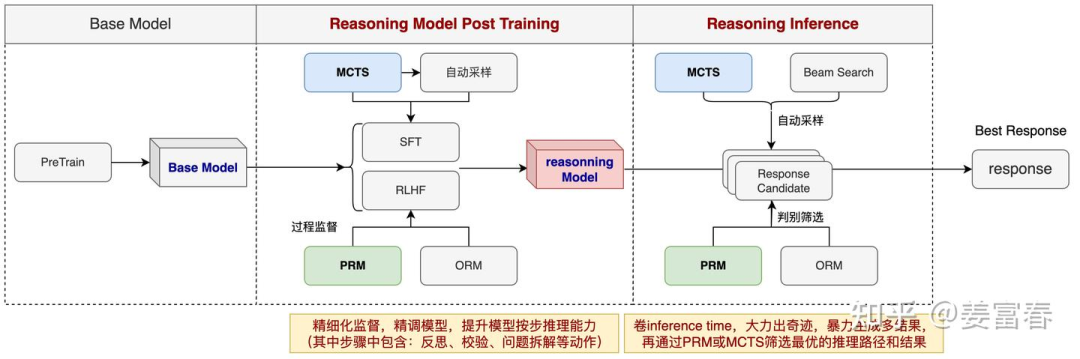
图2、基于PRM和MCTS的推理模型
注:这里对PRM和MCTS在Reasoning Model上的使用,是个人参考paper和网上的一些资料的总结,可能有不准确的地方。如有错误,欢迎指正~
1.3. PRM和MCTS方法存在的问题
PRM和MCTS的方法理论上都有自身的优势。对于复杂的推理过程,PRM可以按步骤做细粒度的监督,MCTS可以自动探索解空间。两者配合可以在探索(Exploration)和利用(Exploitation)上做平衡,以提升复杂问题的推理能力。
但在实践中这两种方法存在明显的局限性:
-
PRM的局
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









