




1. 为什么要提出 RARE?
问答(QA,Question Answering)系统的目的以自然语言提出的问题生成答案,其涵盖的领域和类型极为广泛,从开放领域的 QA到更为专业的领域,比如医疗QA。
医疗 QA 要求模型能够掌握复杂的医学知识、解读临床场景,并选出正确且符合上下文的选项。
和多数专业领域的 QA 类似,医疗 QA 也需要结构化的多步骤推理,从一系列连续的步骤中推理出答案。比如,依据患者信息给出恰当的初始治疗方案,模型首先要识别患者的状况,接着分析相关因素并诊断疾病,最后确定合适的基于证据的干预措施。如果没有这种结构化的多步骤推理,面对如此复杂的医疗场景,很难得出准确且与上下文紧密相关的答案。
此外,医疗 QA 存在一些显著区别于其他领域 QA 的问题:
-
• 高度依赖特定领域的知识,而这些知识并非总能在预训练模型中获取,因此需要从外部来源依据事实进行检索。比如涉及特定医学术语,像射血分数降低的心力衰竭(HFrEF)这类问题。而且,医学知识更新迅速,新的治疗方法或最新的指南可能未被纳入模型的预训练语料库。例如,较新的药物(如用于 HFrEF 的 SGLT2 抑制剂)可能在近期的指南中被推荐,却在较旧的预训练模型中缺失。
-
• 包含各式各样的问题类型,不仅有前面提及的多步骤推理和基于事实的检索,还包括需要迭代证据检索的问题,在整个过程中都要求在每个推理步骤检索相关知识以确保准确性和相关性。
2. 什么是RARE框架?
2.1 RARE 框架概览
针对上述问题,作者提出了检索增强推理增强(RARE,Retrieval-Augmented Reasoning Enhancement)。
RARE基于现有的 rStar,其中语言模型生成推理步骤,另一个进行验证,在无需微调或使用高级模型的情况下提升准确性。为生成有效的多步骤推理路径,RARE 涵盖了五种类型的动作来提示语言模型生成下一个推理步骤。
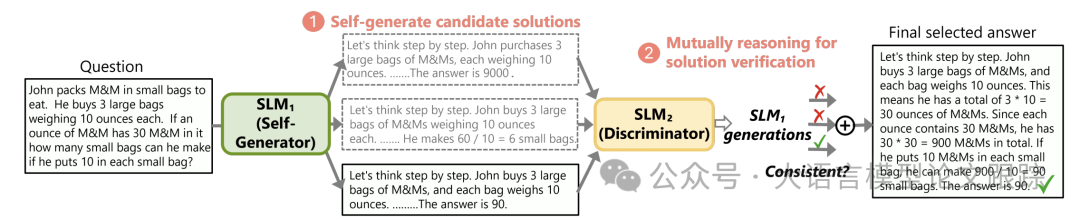
什么是rStar?
Self-play muTuAl Reasoning (rStar) 是一种自我博弈的相互推理方法,显著提高了小型语言模型(SLMs)的推理能力,而无需微调或依赖更高级的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









