




1. 背景
移动端智能体(Mobile Agent)是指在移动端(手机)上能够实现在多种应用中自动化执行任务,且几乎无需人工介入的AI应用。这些智能体专为在动态环境中进行感知、规划和执行而设计,非常适合需要即时适应性的移动平台。
随着时间的推移,移动端智能体的研究有了显著的进步,从简单的基于规则的系统发展到能够处理多模态和动态环境中复杂任务的更复杂的模型。
在早期,移动端智能体主要集中于通过轻量级的、基于规则的系统来执行预设的工作流程,这些系统专为移动设备上的特定任务量身定制。这些早期的智能体常常受限于硬件的计算和内存限制,严重依赖于基本的交互模式和静态流程。然而,移动技术的迅猛发展为更高级的智能体架构铺平了道路,使其能够执行更复杂的任务。
移动智能体研究的最新进展可以分为两大类:
基于提示的方法和基于训练的方法。
-
• 基于提示工程的方法:利用大型语言模型(LLMs),如ChatGPT 和GPT-4,通过指令提示和思维链(CoT)推理来处理复杂任务。如OmniAct 和AppAgent,已经展示了基于提示的系统在交互式移动环境中的潜力,尽管可扩展性和鲁棒性仍然有待提高。
-
• 基于训练的方法:为移动应用微调多模态模型,如LLaVA和Llama。这些模型能够处理丰富的多模态数据,通过整合视觉和文本输入,提高执行界面导航和任务执行等任务的能力。
2. Mobile Agent 核心组件
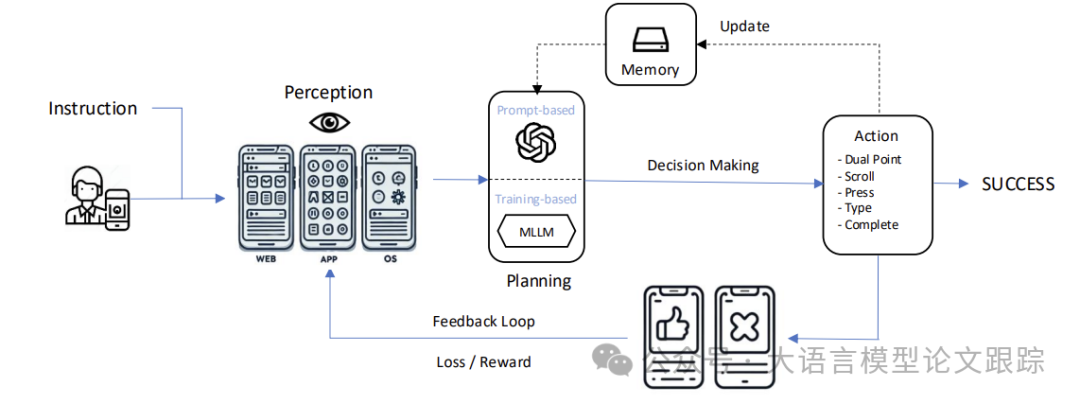
如上图,移动端智能体的四大核心构件:感知(Perception)、规划(Planning)、行动(Action)和记忆(Memory)。这些组件协同工作,让智能体能在复杂多变的移动环境中进行感知、推理和执行,灵活调整行为以提升任务的效率和稳定性。
2.1 感知(Perception)
感知是移动端智能体搜集和解读周围多模态信息的过程,提取有助于规划和执行任务的关键信息。
早期对移动智能体的研究主要依赖于将图像或音频转换为文本描述的简单模型或工具。但这些方法往往产生不相关和冗余的信息,影响了任务规划和执行的效率,尤其是在信息量巨大的界面中。
此外,大型语言模型(LLMs)的输入长度限制进一步加剧了这些挑战,使得智能体在处理任务时难以筛选和排序信息。大多数预训练的视觉编码器对移动数据中的交互元素不够敏感。为应对这一问题,有的智能体引入了专门针对移动环境的数据集,增强了视觉编码器识别和处理关键交互元素(例如图标)的能力。
在可以访问API调用的情况下,Mind2Web提出了一种处理基于HTML信息的方法,该方法对HTML数据的关键元素进行排序并筛选重要细节,以提升LLM对交互组件的感知能力。同时,Octopus v2通过使用专门的功能标记来简化功能调用,显著提升了设备上语言模型的效率,并降低了计算负担。
2.2 规划(Planning)
规划是移动智能体的核心环节,让智能体能够基于任务目标和变化的环境制定行动策略。与静态环境中的智能体不同,移动智能体必须在处理多模态信息的同时适应不断变化的输入。
移动智能体的规划
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









