



随着ACL 2024大会的圆满落幕,本文将重点介绍会议中涉及的与Retrieval-Augmented Generation(RAG)相关的论文,探索这一领域最新的研究成果和发展趋势。
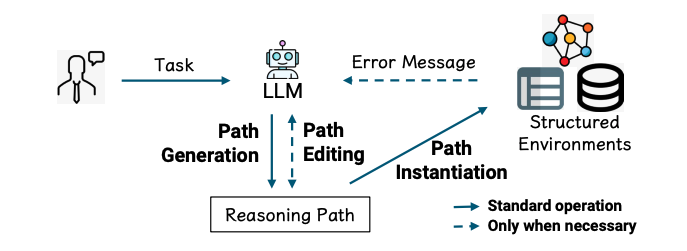
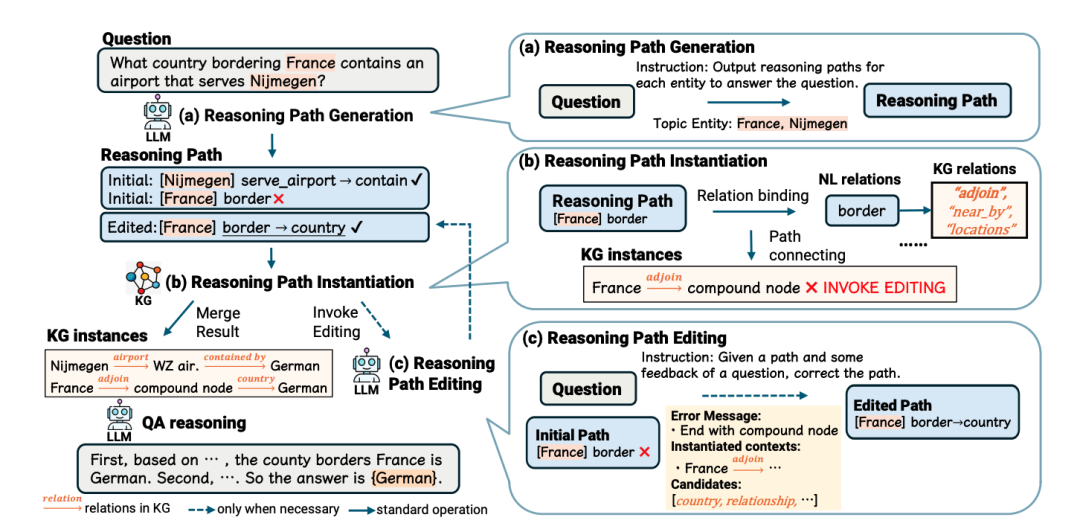
Call Me When Necessary: LLMs can Efficiently and Faithfully Reason over Structured Environments
https://aclanthology.org/2024.findings-acl.254.pdf
文章首先介绍了LLMs在处理这类任务时的挑战,即需要进行多跳推理,将自然语言话语与结构化环境中的实例相匹配。
在推理路径生成阶段,LLMs根据问题和给定的主题实体生成初始推理路径。在实例化阶段,系统尝试将推理路径与结构化环境匹配,并在遇到错误时收集错误信息。最后,在编辑阶段,LLMs利用这些错误信息来修正推理路径。
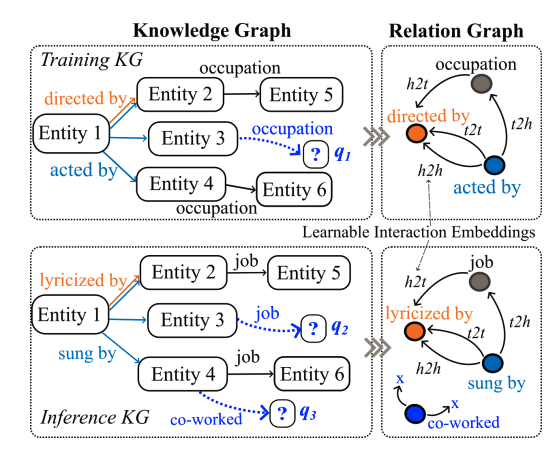
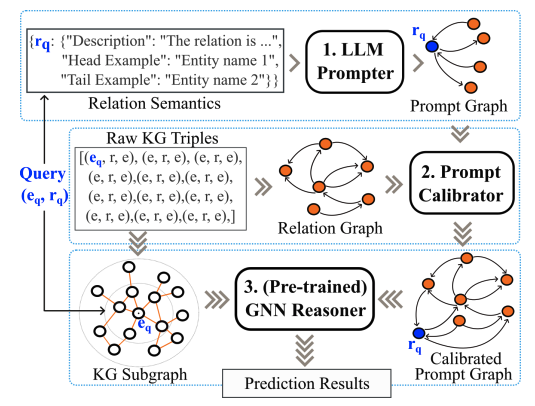
LLM as Prompter: Low-resource Inductive Reasoning on Arbitrary Knowledge Graphs
https://aclanthology.org/2024.findings-acl.224.pdf
KG归纳推理的一个关键挑战是处理文本和结构信息都匮乏的低资源场景。为了解决这一挑战,作者提出了利用大型语言模型(LLMs)生成图结构提示来增强预训练的图神经网络(GNNs),从而为KG归纳推理方法带来新的方法论见解,并在实践中具有很高的通用性。
A + B: A General Generator-Reader Framework for Optimizing LLMs to Unleash Synergy Potential
https://aclanthology.org/2024.findings-acl.219.pdf
提出了一个名为“A + B”的框架,旨在优化大型语言模型(LLMs)以释放协同潜力。这个框架通过将生成器(generator)和阅读器(reader)的角色分开,以提高LLMs在知识密集型任务中的性能和安全性。
文章阐述了“A + B”框架,其中A代表生成器,B代表阅读器。生成器A负责产生与输入查询相关的上下文,需要高度的事实准确性;而阅读器B则负责解释生成的上下文以提供适当的响应,需要认知推理和与人类偏好的一致性。
Uncovering Limitations of Large Language Models in Information Seeking from Tables
https://aclanthology.org/2024.findings-acl.82.pdf
文章介绍了一个名为TabIS(Table Information Seeking)的新基准测试,旨在评估大型语言模型(LLMs)在表格信息检索(TIS)方面的能力。TabIS包含三种典型的TIS场景,并采用单选题格式以确保评估的可靠性。通过对12个代表性LLMs的广泛实验。

TEXT2DB : Integration-Aware Information Extraction with Large Language Model Agents
https://aclanthology.org/2024.findings-acl.12.pdf
文章将信息提取的输出与目标数据库(或知识库)进行整合。这项任务需要理解用户指令来确定提取内容,并根据给定的数据库/知识库架构动态适应提取方式。
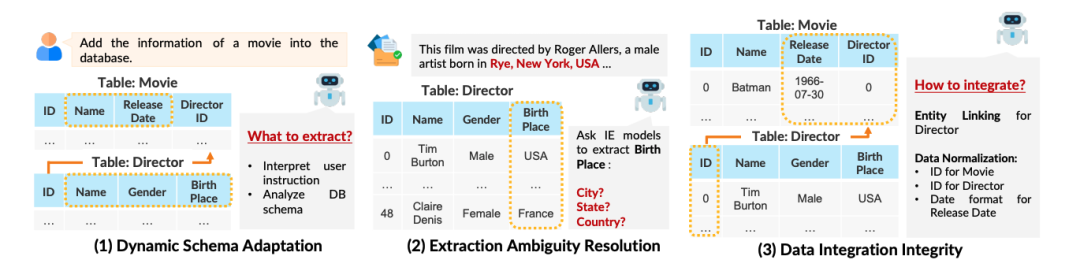
设计的框架包括与数据库交互的观察者组件、生成基于代码的计划的规划者组件,以及在执行前提供代码质量反馈的分析器组件。
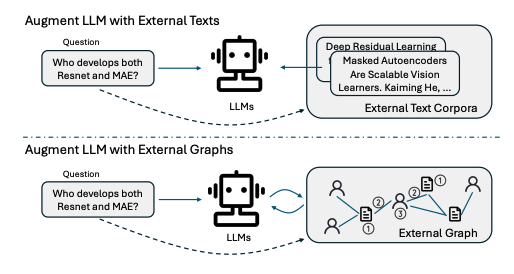
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
https://aclanthology.org/2024.findings-acl.11.pdf
Graph-COT的每次迭代包括三个子步骤:LLM推理、LLM-图交互和图执行。文章还包含了数据集的创建过程,包括数据收集、问题模板设计、使用GPT-4生成多样化的问题表达,以及如何从图中自动生成答案。
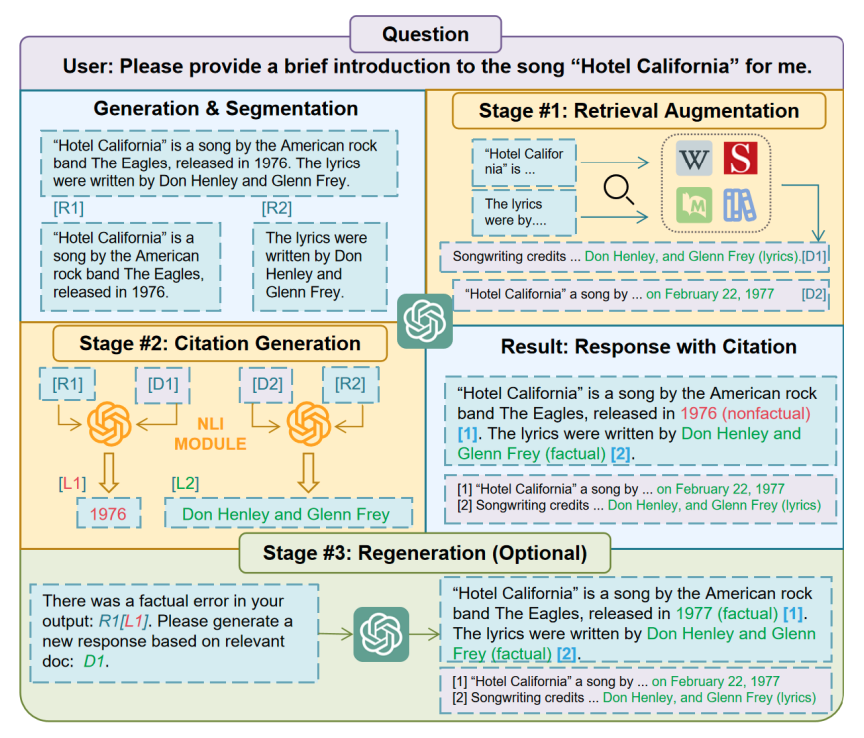
Citation-Enhanced Generation for LLM-based Chatbots
https://aclanthology.org/2024.acl-long.79.pdf
文章介绍了一种名为Citation-Enhanced Generation (CEG)的新型方法,旨在减少大型语言模型(LLM)聊天机器人在生成回答时可能出现的虚构内容。
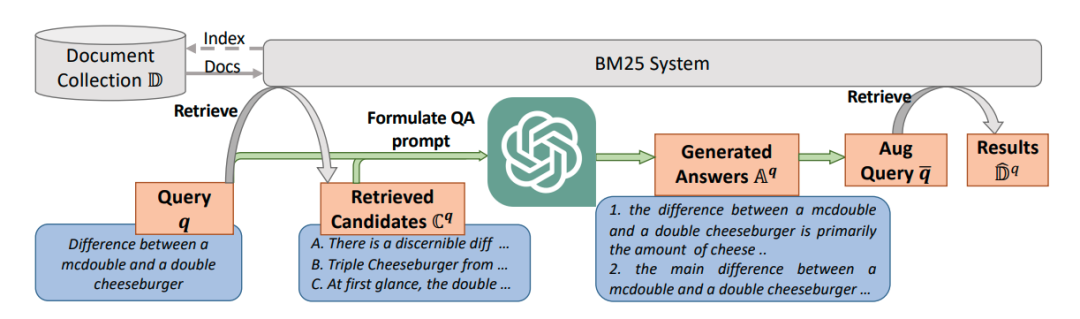
Retrieval-Augmented Retrieval: Large Language Models are Strong Zero-Shot Retriever
https://aclanthology.org/2024.findings-acl.943.pdf
文章提出了一种名为“Large language model as Retriever (LameR)”的方法,它利用大型语言模型(LLM)来改善零样本(zero-shot)情况下的大规模信息检索性能。LameR的核心思想是通过提示(prompting)LLM,将查询及其潜在答案结合起来,以增强查询并提高检索质量。
ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
https://aclanthology.org/2024.findings-acl.122.pdf
文章提出了ChatKBQA,这是一个新颖的生成-检索KBQA框架,它首先使用微调的大型语言模型(LLMs)生成逻辑形式,然后使用无监督检索方法检索和替换实体和关系,以更直接地改进生成和检索。
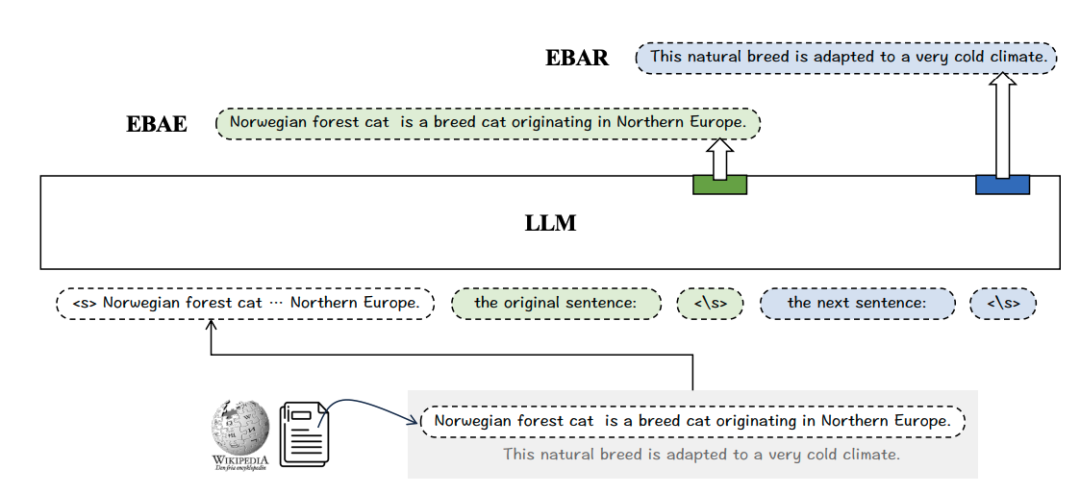
Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval
https://aclanthology.org/2024.acl-long.191.pdf
Llama2Vec的核心思想是利用两个预文本任务:EBAE(基于嵌入的自编码)和EBAR(基于嵌入的自回归),来促使LLMs生成能够代表输入文本全局语义的嵌入向量。这种方法简单、轻量级,但非常有效。
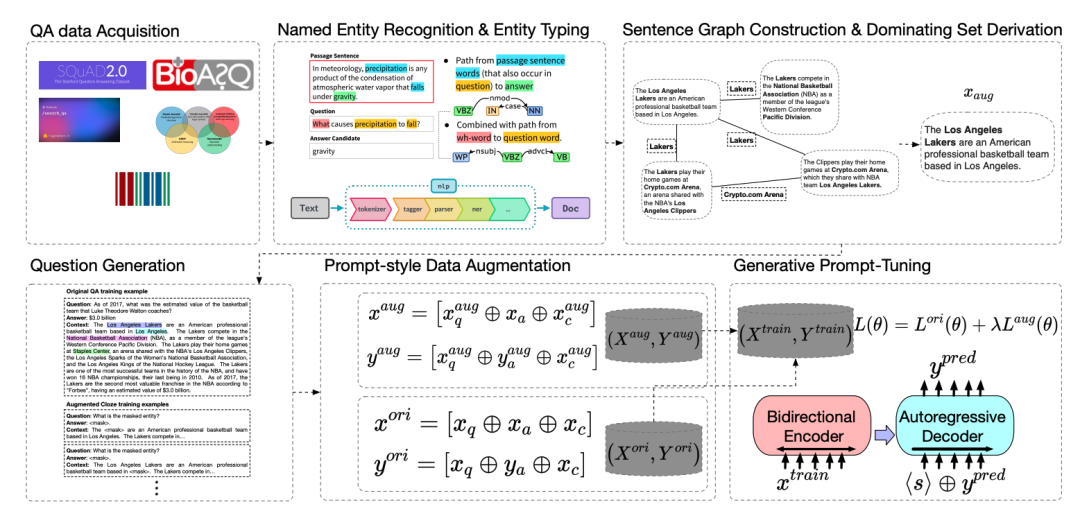
MINPROMPT: Graph-based Minimal Prompt Data Augmentation for Few-shot Question Answering
https://aclanthology.org/2024.acl-long.16.pdf
文章介绍了一种名为MINPROMPT的新型数据增强框架,它针对少量样本问答(Few-shot Question Answering, QA)任务,旨在提高问答模型的效率和性能。MINPROMPT通过图算法和无监督问题生成技术,从原始文本中提取最有意义的问答训练样本。
-
句子图构建模块:利用句子图表示来结构化原始文本,通过图算法识别出覆盖最多信息的句子子集。
-
数据选择模块:应用近似最小支配集算法来确定最小的句子集合,以覆盖所有共享实体。
-
问题生成模块:将选定的事实句子转换成问答对,进一步转换成提示,为QA模型提供高质量、信息丰富的训练实例。
来源 | 包包算法笔记

















 3876
3876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









