




1. 当前知识图谱构建存在的问题
知识图谱通过捕捉实体之间的关系来构建知识的结构化表示,在分析文本数据集和从结构化异构数据中推断知识方面具有显著优势。比如,知识图谱能够融合来自多个来源的不同数据,提供一个具有凝聚力的信息视角。还能为文本语料库的分析提供更高层次的可解释性。
知识图谱的重要性不必多言,最近的GraphRAG又再一次将知识图谱掀起高潮。
1.1 传统知识图谱构建的问题
传统的命名实体识别、关系提取和实体解析是常用于将非结构化文本转化为结构化数据、捕获实体及其关联和相关属性的 NLP 技术。然而,这些方法存在一些局限性:往往局限于预定义的实体和关系,或者依赖特定的本体,并且大多依赖监督学习方法,需要大量的人工标注。
1.2 LLM时代知识图谱构建的问题
LLMs (大语言模型) 的最新进展在包括知识图谱补全、本体优化和问答等各类 NLP 任务中展现出了潜力和更优的性能,为知识图谱的构建带来了良好的前景。
LLMs 在少样本学习方面也表现出色,能够实现即插即用的解决方案,并且无需大量的训练或微调。由于它们在广泛的信息源中接受训练,因而能够跨不同领域提取知识。
所以,近期的研究已开始利用 LLMs 的发展成果,特别是其在知识图谱构建任务中的少样本学习能力。
不过,未解决和语义重复的实体及关系仍然构成重大挑战,导致构建的图谱出现不一致的情况,需要大量的后期处理。这些不一致可能表现为冗余、模糊以及图谱扩展的实际困难。
此外,许多现有的方法与主题相关,这意味着其有效性在很大程度上取决于其设计所针对的特定用例。这种依赖性限制了这些方法在不同领域的通用性,需要为每个新的主题领域定制解决方案。
基于大型语言模型(LLM)构建知识图谱(KG)的解决方案,可依据三种范式来分类:本体引导、微调以及零样本或少样本学习。
2. iText2KG
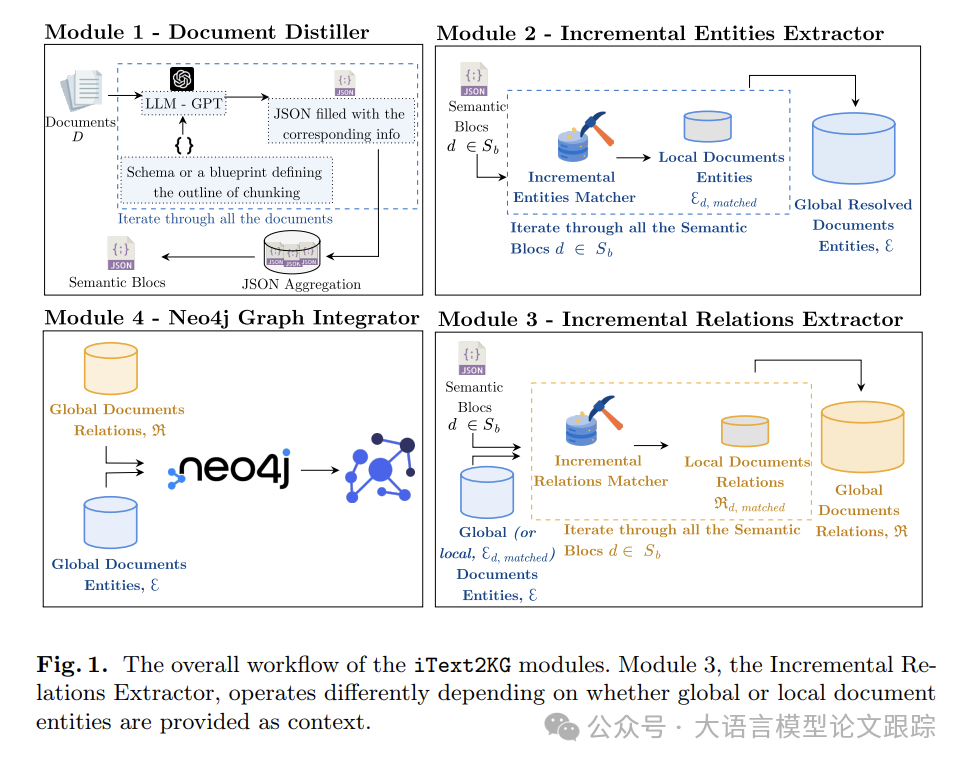
为了解决以上问题,作者提出了iText2KG。上图是 iText2KG 的工作流程概览。包含四个模块:
-
• 1)文档蒸馏器(Document Distiller):利用 LLM,将原始文档重新整理为预定义和语义块。该模式类似预定义的 JSON 结构,引导语言模型从每个文档中提取与特定键相关的特定文本信息;
-
• 2)增量实体提取器(Incremental Entities Extractor):获取语义块,识别语义块内独特的语义实体,消除歧义,确保每个实体都有清晰的定义并与其他实体区分开;
-
• 3)增量关系提取器(Incremental Relations Extractor):处理已解决的实体和语义块,以检测语义上独特的关系。
-
• 4)图集成器(Graph Integrator):使用 Neo4j 以图形格式直观地呈现这些关系和实体。
2.1 文档蒸馏器(Document Distiller)
运用大型语言模型(LLM)依照预定义的模式(Schema)或蓝图将输入文档重写为语义块。这些模式(Schema)并非
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









