





额
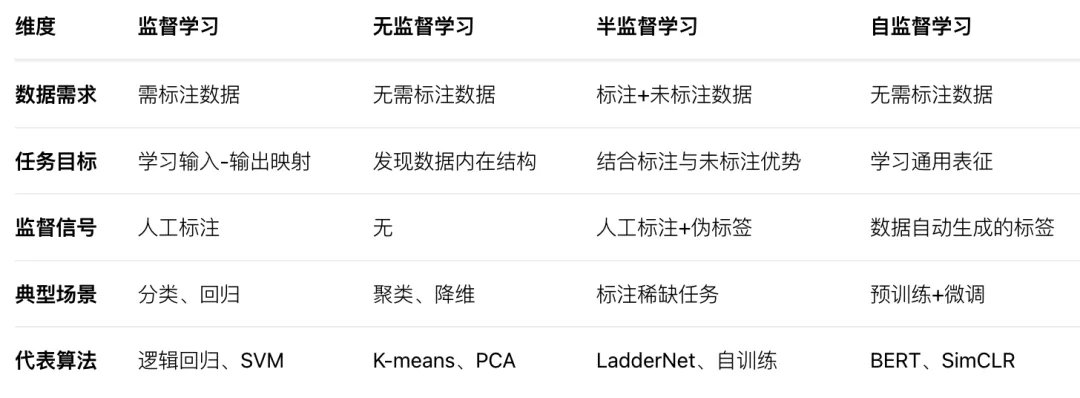

监督学习
监督学习利用大量的标注数据来训练模型,对模型的预测值和数据的真实标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。
特点:每个样本都有明确标签(如图片分类中的“猫/狗”)
典型应用:图像分类、语音识别、垃圾邮件过滤。
局限性:标注成本高,数据标注耗时且依赖人工
无监督学习
无监督学习完全无需人工标注,通过对数据内在特征的挖掘,找到样本间的关系。
特点:数据本身蕴含结构(如客户分群、文本主题提取)
与有监督学习的最主要差别:是否需要人工标注的标签信息。
真正的无监督学习应该不需要任何标注信息,通过挖掘数据本身蕴含的结构或特征,来完成相关任务,大体可以包含三类:
| 聚类 | k-means,谱聚类等 |
| 降维 | 线性降维:PCA、ICA、LDA、CCA等 |
| 非线性降维:ISOMAP、KernelPCA等 | |
| 2D降维:2D-PCA | |
| 离散点检测 | 如基于高斯分布或多元高斯分布的异常检测算法 |
无监督学习最主要采用的是自动编码器的方式。
其核心机制是通过编码器-解码器结构实现数据压缩与重构:
编码阶段:编码器将输入数据(如图像、文本)压缩为低维隐层向量,保留关键特征;
解码阶段:解码器基于隐层向量重建原始数据,理论上能无损还原输入。
由于隐层维度远低于输入维度(例如将784维图像压缩至20维),这个过程本质是非线性降维。
学习到的隐层向量可作为数据的紧凑表征,直接替代原始数据用于聚类、分类等任务,降低计算复杂度。(例如MNIST手写体识别中,150维隐层即可有效区分数字类别)
表征/表示学习(Representation Learning)则是对如何学习隐藏向量的研究。
核心是让机器自动从数据中提取有用特征(比如把图片压缩成几串数字)。
传统方法(如自动编码器)虽然能压缩数据,但存在两个关键问题:
1、只看像素,忽略结构
传统方法按像素逐个重建(比如把猫的每根毛都单独处理),导致模型学不到“猫耳朵”和“猫脸”的关联,只能记住零散的像素点。
2、语义信息缺失
比如判断两张图是否都是“猫”,传统方法可能只关注颜色深浅,而无法识别“胡须方向”等关键特征。
自监督学习通过设计辅助任务(如预测图片旋转角度、拼图还原),迫使模型理解数据背后的逻辑,最终学到“猫有四条腿”这样的语义知识。
半监督学习
半监督学习:让学习器不依赖外界交互,自动的利用未标记样本来提升学习性能。
核心思想:结合少量标注数据和大量无标签数据,提升模型性能。
半监督学习可进一步划分为纯(pure)半监督学习和直推学习(transductive learning),
| 纯(pure)半监督学习 | 假定训练数据中的未标记样本并非待测的数据 |
| 直推学习(transductive learning) | 假定学习过程中所考虑的未标记样本是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。 |
半监督深度学习算法可以总结为三类:
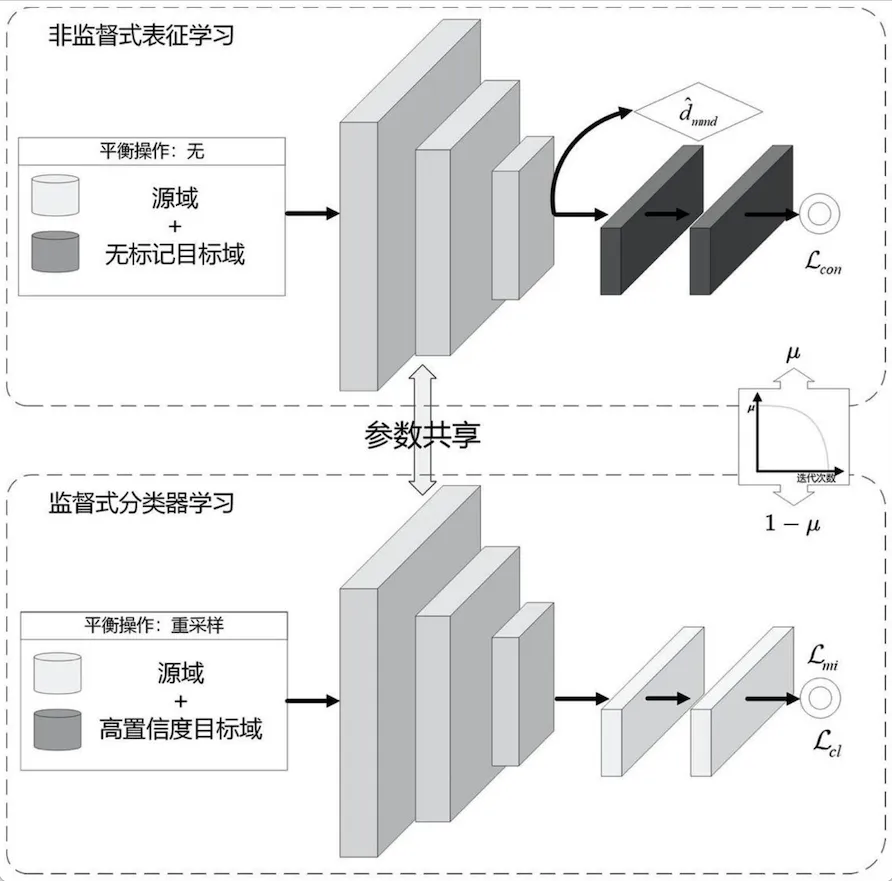
1. 无标签数据预训练网络后有标签数据微调(fine-tune)
无监督打地基:用所有数据逐层重构预训练,对网络的每一层,都做重构自编码,保留核心特征,然后把自编码网络的参数,作为初始参数,用有标签数据微调。
伪有监督预训练:通过某种方式/算法(如半监督算法,聚类算法等),用少量标记数据微调模型,提升分类能力,然后在用有标签数据来微调。
例子:先用10万张无标签图片训练特征提取器,再用1万张带标签图片优化细节
2. 利用从网络得到的深度特征来做半监督算法
先用有标签数据训练网络,从网络中提取数据特征,以这些特征用某种分类算法对无标签数据进行分类,挑选认为分类正确的无标签数据加入到训练集,再训练网络,如此循环。
特点:筛选高置信度预测结果 → 加入训练集循环优化
效果:像滚雪球,正确分类的无标签数据越多,模型越强
3. 半监督网络结构
就神经网络本身而言,其实还是运行在一种有监督的方式上。2015年诞生半监督ladderNet,效果非常好,达到了当时的state-of-the-art性能。
文章
(Rasmus,A.,Valpola,H.,Honkala,M.,Berglund,M.&Raiko,T. Semi-Supervised Learning with Ladder Network.)
ladderNet是有监督算法和无监督算法的有机结合。
很多半监督深度学习算法是用无监督预训练这种方式对无标签数据进行利用的,但事实上,这种把无监督学习强加在有监督学习上的方式有缺点:
传统问题:自监督预训练(学特征)和监督微调(学分类)目标冲突
ladderNet通过skip connection解决这个问题,通过在每层的编码器和解码器之间添加跳跃连接(skip connection),减轻模型较高层表示细节的压力,使得无监督学习和有监督学习能结合在一起,并在最高层添加分类器,ladderNet就变身成一个半监督模型。
优势:同时利用标记数据分类+未标记数据重建,提升泛化能力
自监督学习
相比于上述方法,自监督学习实现了用更少的样本或更少的实验来学习更多。
核心思想:通过设计辅助任务(如预测图像旋转角度),从无标签数据中生成监督信号。
自监督学习在很多地方被定义为无监督学习问题,但是它常常被构造为监督学习问题的求解形式
典型的例如word2vec,autoencoder这类明明没标签却能够造出目标函数,使用凸优化方法求解,无中生有,这和kmeans,dbscan之类的无监督学习的范式是完全不同的
判断一个工作是否属于自监督学习,除了无需人工标注这个标准之外,还有一个重要标准,就是是否学到了新的知识。对于自监督学习能够学到新信息的原理解释:
- 数据的丰富性和多样性:自监督学习通常利用大规模的未标记数据进行训练,这些数据往往具有丰富的内容和多样的特征。
- 任务的设计和构造:通过设计具有挑战性和信息丰富度的预测任务,可以促使模型更好地学习数据的表示。例如,可以设计预测图像的旋转角度、颜色变换、上下文信息等任务。
- 迁移学习和泛化能力:通过对比学习、时序建模等方法,提取跨领域通用特征(如物体轮廓、语义关联),实现小样本场景下的快速适应与持续学习。
- 自适应和增量学习:可以通过不断更新模型参数来适应新的数据和环境。
- 特征提取和表示学习:自监督学习通过预测数据的属性或结构,推动模型学习数据的特征表示。些特征表示可以用于解决各种任务。
自监督学习通过设计数据增强和任务构造,从无标签数据中自动生成监督信号:
数据增强:对图片翻转、裁剪等操作生成新样本,迫使模型学习不变特征(如识别旋转后的猫)。
图像任务
像素预测:遮挡部分图像,让模型补全(如MAE)
颜色化:将灰度图恢复彩色,学习语义关联(如天空蓝色)
3.对比学习:对同一图片生成不同增强视图(如裁剪+调色),拉近相似视图的特征距离,推开不相似视图
4.生成式任务:用GAN生成假图,与原图对比学习特征(如StyleGAN)
实际上自监督学习的应用有很多,但是其最核心的目标还是在“为下游的有监督任务学习良好的representation”,
通过自监督学习能够学习到泛化性能很强的representation(也即nn里的一些layer输出的features是比较generalized,这个generalized的features反应了数据本身的一些隐藏的pattern,最好这些pattern可以在许多的下游任务中shared(transfer learning and pretrained model)),
例如nlp中的许多预训练任务都可以视为自监督学习,从transformer pretrained model的表现也可以看到自监督学习的强大。
优势:
无需人工标注,数据利用率高。
学习的特征泛化性强,适合小样本场景。
典型应用:
大语言模型预训练(如GPT、BERT)
图像自监督表征学习(如ResNet)
多模态任务(如CLIP跨模态对齐)

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









