




CapaBench 是一个量化 LLM Agent 架构中各个模块贡献的评估框架。
随着大规模语言模型(LLMs)的快速发展,人工智能代理在理解、生成和集成自然语言方面取得了显著突破。最近,DeepSeek与Claude的结合——DeepClaude——创造性地将DeepSeek的推理能力与Claude的生成能力结合,打造出“思考脑 + 创作脑”的双引擎架构。DeepSeek负责“思考”,Claude负责“表达”,这种推理与生成解耦的分工协作模式,使得模型能够在各自擅长的领域发挥最大优势,从而生成更智能、更专业的设计方案。
虽然LLMs在多个领域展现了强大的表现,但它们在实际应用中仍面临诸多挑战,比如准确理解细微的上下文变化、有效集成外部工具以及保证输出的可靠性和准确性。因此,越来越多的LLM Agent研究开始采用模块化架构,将复杂的任务分解为不同的模块,从而增强系统的可解释性和性能。
例如,经典的LLM Agent框架ReAct和AutoGPT通过将任务划分为规划、推理和行动执行等模块,取得了显著的效果。这种分层结构不仅提高了任务的处理效率,还增强了代理的可维护性和可扩展性。然而,尽管模块化架构有诸多优势,如何评估各个模块在整个系统中的作用及其相互作用,仍然是一个亟待解决的问题。
然而,在这种多模块架构下,如何评估各模块的贡献,尤其是在实际应用中如何充分发挥其性能,成为了一个迫切需要解决的挑战。为了解决这一问题,我们提出了CapaBench框架,它采用模块化设计,系统地评估Agent内部各个能力模块的贡献,采用Shapley value方法,为模块化LLM代理提供了一种全新的、可解释的评估方式。

1
LLM代理的模块化架构
CapaBench采用模块化设计,构建了如下所示的代理框架,旨在全面评估LLM代理在多种环境下的表现。该框架融合了当前主流LLM代理框架中的四个核心模块——规划、推理、行动和反思。
规划模块:将复杂任务拆解为结构化的子任务,确保代理能够有效地进行任务优先级排序和资源分配。
推理模块:通过链式思维机制,进行逻辑推理和因果分析,帮助代理根据任务进展调整策略。
行动模块:根据规划结果执行操作,确保代理的行为与环境状态持续对接。
反思模块:通过分析任务失败原因,帮助代理在多回合任务中反思并优化其行为
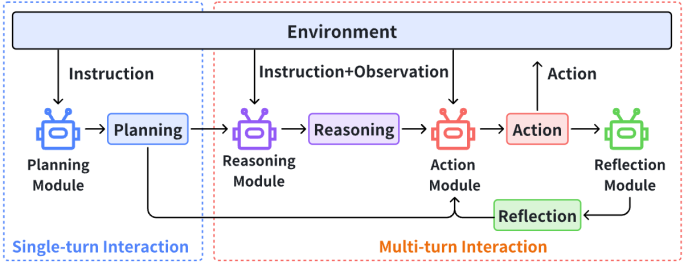
这些模块是了当前LLM Agent架构内解决复杂任务的核心基础,也是LLM Agent能够高效应对各种挑战的关键能力。
2
模块贡献的系统性评估
CapaBench采用Shapley值方法来量化各个模块的贡献。Shapley值是一种源自合作博弈论的公平评估框架,它通过计算每个模块对系统表现的边际贡献,确保各模块的表现得到了公正的归因。
Shapley值公式如下:
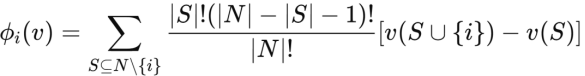
其中,N代表所有模块的集合,v(S)表示仅激活集合S中模块时的代理表现。通过该方法,我们可以量化每个模块的独立贡献以及模块之间的协同效应。
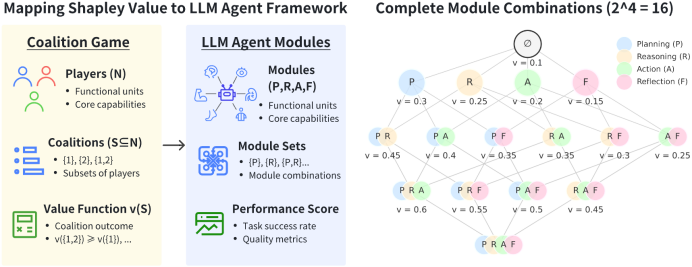
我们对四个核心模块的所有可能组合进行了评估,总共生成了 2^4 = 16 种不同的组合。在每种组合下,我们通过一系列多回合场景任务来评估代理的任务成功率,从而量化不同模块及其组合对整体任务表现的影响。
评估流程如下:
-
替换默认模块为测试模块。
-
使用不同任务基准评估代理的成功率。
-
计算每个模块的Shapley值,以量化其贡献。

3
数据集建设与评估任务
为了确保评估框架能够应对现实应用中的多样化挑战,我们还构建了一个大规模的数据集,涵盖了超过1500个多回合任务,包括在线购物、导航规划、票务订购、数学问题求解、自动定理证明、机器人协作和操作系统交互等任务。
-
在线购物任务:评估代理在处理个性化推荐中的能力,要求代理根据用户偏好提供最相关的商品建议。
-
导航规划任务:考察代理根据动态更新的用户需求生成旅行计划的能力,要求代理在多次任务迭代中灵活应对。
-
票务订购任务:测试代理根据用户日程和预算限制提供最佳航班组合的能力。
-
数学求解任务:通过集成工具使用,评估代理在代数和几何问题上的求解能力。
-
自动定理证明任务:考察代理在使用Coq和Isabelle等工具进行形式化推理和定理证明中的能力。
-
机器人协作任务:测试代理在与其他机器人协作时的表现,例如协作完成清扫、排序和物品搬运任务。
-
操作系统交互任务:评估代理在模拟操作系统环境下执行命令、操作文件系统和管理进程的能力。
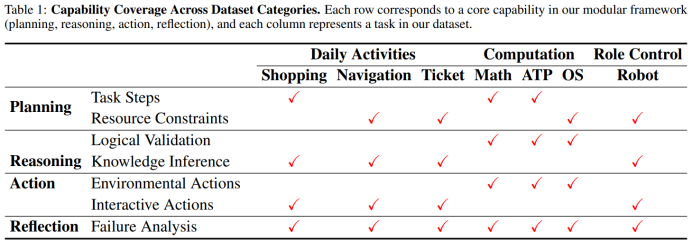
每个数据集都结合agent的特征经过精心设计,涵盖了多种难度等级,确保任务能够挑战规划、推理、行动和反思等模块的能力。任务设计不仅聚焦于单一技能的评估,还模拟了真实应用场景中的复杂交互,例如在多回合任务中,代理需要不断调整策略来应对不断变化的需求和约束。
上述评测集已在AGI-Eval社区平台上线,可跳转链接(https://agi-eval.cn/evaluation/CapaBench)查看。
4
实验评估
在我们的实验中,我们设定Llama3-8B-Instruct为所有四个核心模块(规划、推理、行动和反思)的默认实现。在每次评估中,我们有系统地将其中一个模块的默认实现替换为其测试变体(由测试模型驱动),同时保持其他模块为默认状态。通过这种系统化的替换方式,我们生成了 2^4 = 16 种不同的模块组合。在每个组合S下,我们通过一系列基准场景测量任务成功率 v(S),以确保获取可靠且具有代表性的性能数据。
我们评估了九个大规模语言模型,分为三组:
1. 封闭API模型:包括四个广泛使用的商业API模型:Anthropic/Claude-3.5-Sonnet、OpenAI/GPT-4-turbo-0409、OpenAI/GPT-4o-mini、GLM-4-air 和 Doubao-pro-4k。
2. 中型开源模型(32B-100B):为评估中型架构,选用了三个模型:Llama3.1-70B-Instruct 和 Mixtral-8x7B-Instruct-v0.1(46.7B)。
3. 轻量级开源模型(≤32B):为轻量级实现,包含 Qwen2.5-32B-Instruct 和 Mistral-8B-Instruct-v0.2。
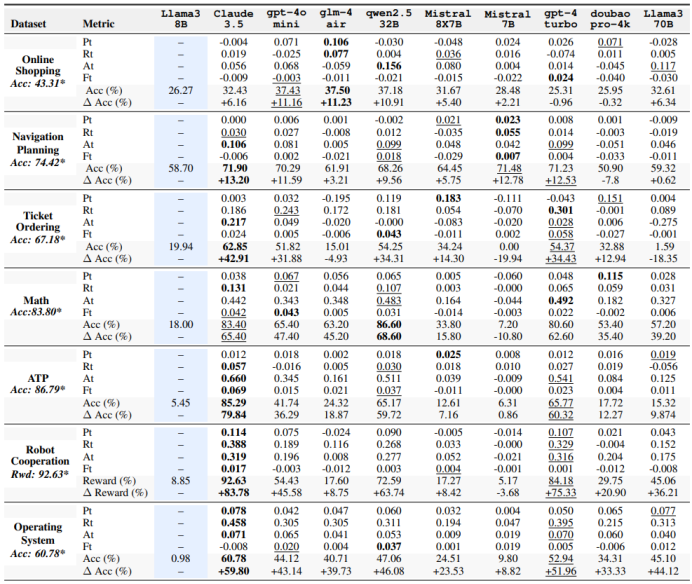
上面表格中的实验结果表明,具有更高Shapley值的模块组合始终能提高任务表现。在“在线购物”数据集中,最佳组合的准确率达到了43.31%,远高于其他模型,显示出利用高贡献模块的优势。同样,在ATP任务中,基于Shapley值计算的最佳组合实现了86.79%的准确率,显示出明显的改进。这些结果表明,识别和集成具有高Shapley值的关键模块,使得CapaBench能够在各种任务中系统地最大化性能,验证了Shapley值作为可靠模块选择和优化的指南。
5
现象分析
跨任务模型性能比较
我们对不同任务中模型表现的高层次比较揭示了各模型的优势与劣势。值得注意的是,Claude-3.5在大多数任务中表现优异,特别是在形式化验证(如Coq、Lean 4、Isabelle)和机器人协作任务中展现了显著的优势。这表明Claude-3.5具备强大的推理机制和高效的多代理协作策略,这些能力对需要精确逻辑证明结构和协调同步行动的任务至关重要。相比之下,开源模型如Qwen-2.5和Mistral-8X7B在较为简单的领域(如购物和基本代数)中取得了中等的进展,但在认知密集型任务中表现不佳。它们在自动定理证明和机器人协作上的落后表明,尽管这些模型在处理常规查询和程序性问题求解上表现较好,但它们缺乏深度推理、先进规划或专门模块,这些对于高难度协调和严格的证明验证是必需的。通过对专业语料库的微调或整合更先进的工具使用,可能有助于缩小开源模型与专有模型在复杂多阶段任务中的差距。
模块贡献模式
我们的研究发现,不同任务对模块贡献的需求各异,反映了不同的认知过程。具体来说:
高认知复杂度的任务(例如在线购物、机器人协作和操作系统):推理和规划发挥了至关重要的作用。在线购物任务需要有效平衡约束条件(如预算和偏好)并有效安排决策顺序。在机器人协作中,推理使得信息更新和任务分配更加高效。操作系统任务涉及故障排除和资源管理,依赖于实时问题解决和反馈解释。在这些任务中,强大的推理能力确保了在不确定条件下进行逻辑推理和决策。
要求精准度的任务(例如数学求解和自动定理证明):行动是主导模块。在数学求解中,特别是几何任务中,精确的程序执行,如应用定理或构建图形,比战略规划更为重要。同样,在形式验证任务(如Coq或Lean)中,严格遵循语法和语义正确性至关重要。这些场景都要求在每一步执行中保持高度精准,以确保可靠性并防止错误。
反思模块贡献较低
在所有任务中,反思模块对整体任务表现的贡献较低,主要有以下两个原因:
反思是否能直接转化为更高的成功率,并不一定能准确反映反思的质量或有效性。换句话说,任务是否成功并不能完全衡量模型在反思过程中的深度与质量。即使模型进行了反思,也不能保证它能在下一次任务中有效改进。
当模型进行自我反思时,缺乏额外信息或更强模型的指导,它可能无法准确识别出错误的根本原因。由于缺乏对错误来源的深度洞察,反思往往无法有效促进任务结果的改善。因此,尽管反思模块存在,但它对提高成功率的实际作用仍然有限。
6
结语
CapaBench 作为一种新型的评估框架,能够有效地揭示 LLM 代理中各个模块的作用,为开发者提供科学的性能评估依据,也为代理的优化和未来应用的提升提供了有力支持。我们期待它在学术界和工业界的广泛应用,推动 LLM 代理技术迈向新的高度。
参考资料:
CapaBench: Modular Attribution Benchmark
[2502.00510] Who's the MVP? A Game-Theoretic Evaluation Benchmark for Modular Attribution in LLM Agents

















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









