







 本文是关于使用ELK堆栈部署Kafka的第二部分,介绍了安装Kibana、Filebeat和Kafka的详细步骤。通过配置Kibana连接Elasticsearch,设置Filebeat收集Apache日志并转发到Kafka,以及安装和配置Kafka,创建数据管道。文章还提到了在Kibana中定义索引模式以开始分析数据。整个过程旨在展示一个基本的ELK数据管道实现,强调了Kafka在缓冲数据流中的关键作用。
本文是关于使用ELK堆栈部署Kafka的第二部分,介绍了安装Kibana、Filebeat和Kafka的详细步骤。通过配置Kibana连接Elasticsearch,设置Filebeat收集Apache日志并转发到Kafka,以及安装和配置Kafka,创建数据管道。文章还提到了在Kibana中定义索引模式以开始分析数据。整个过程旨在展示一个基本的ELK数据管道实现,强调了Kafka在缓冲数据流中的关键作用。
通过优锐课核心java学习笔记中,我们可以看到使用ELK堆栈部署Kafka,码了很多专业的相关知识, 分享给大家参考学习。
我又来更啦,关于前部分的详细在这,朋友们不要迷糊,地址在这
总结分享-使用ELK堆栈部署Kafka(part:1)
步骤3:安装Kibana
让我们继续进行到ELK Stack中的下一个组件-Kibana。 和以前一样,我们将使用一个简单的apt命令来安装Kibana:
sudo apt-get install kibana
然后,我们将在以下位置打开Kibana配置文件:/etc/kibana/kibana.yml,并确保定义了正确的配置:
server.port: 5601
elasticsearch.url: "http://localhost:9200"
这些特定的配置告诉Kibana要连接到哪个Elasticsearch以及要使用哪个端口。
现在,我们可以从以下内容开始Kibana:
sudo service kibana start
在浏览器中使用以下命令打开Kibana:http:// localhost:5601。 你将看到Kibana主页。

步骤4:安装Filebeat
如上所述,我们将使用Filebeat收集日志文件并将其转发到Kafka。
要安装Filebeat,我们将使用:
sudo apt-get install filebeat
让我们在以下位置打开Filebeat配置文件:
/etc/filebeat/filebeat.yml
sudo vim /etc/filebeat/filebeat.yml
输入以下配置:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/apache2/access.log
output.kafka:
codec.format:
string: '%{[@timestamp]} %{[message]}'
hosts: ["localhost:9092"]
topic: apache
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
在输入部分,我们告诉Filebeat要收集哪些日志-Apache访问日志。 在输出部分,我们告诉Filebeat将数据转发到本地Kafka服务器和相关主题(将在下一步中安装)。
请注意使用codec.format指令-这是为了确保正确提取message和timestamp字段。 否则,这些行将以JSON发送到Kafka。
保存文件。
步骤4:安装Kafka
我们的最后也是最后一次安装涉及设置Apache Kafka(我们的消息代理)。
Kafka使用ZooKeeper来维护配置信息和同步,因此我们需要在设置Kafka之前安装ZooKeeper:
sudo apt-get install zookeeperd
接下来,让我们下载并解压缩Kafka:
wget http://apache.mivzakim.net/kafka/2.2.0/kafka_2.12-2.2.0.tgz
tar -xvzf kafka_2.12-2.2.0.tgz
sudo cp -r kafka_2.12-2.2.0 /opt/kafka
现在我们准备运行Kafka,我们将使用以下脚本进行操作:
sudo /opt/kafka/bin/kafka-server-start.sh
/opt/kafka/config/server.properties
你应该开始在控制台中看到一些INFO消息:
[2019-04-22 11:48:16,489] INFO Registered
kafka:type=kafka.Log4jController MBean
(kafka.utils.Log4jControllerRegistration$)
[2019-04-22 11:48:18,589] INFO starting (kafka.server.KafkaServer)
接下来,我们将为Apache日志创建一个主题:
bin/kafka-topics.sh --create --zookeeper localhost:2181
--replication-factor 1 --partitions 1 --topic apache
Created topic apache.
我们都准备开始管道。
步骤5:启动数据管道
现在我们已经准备就绪,现在该启动所有负责运行数据管道的组件了。
首先,我们将启动Filebeat:
sudo service filebeat start
然后,Logstash:
sudo service logstash start
管道开始流式传输日志需要花费几分钟。 要查看Kafka的实际效果,请在单独的标签中输入以下命令:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server
localhost:9092 --topic apache --from-beginning
如果你的Apache Web服务器确实在处理请求,则应该开始在控制台中查看Filebeat将消息转发到Kafka主题的消息:
2019-04-23T13:50:01.559Z 89.138.90.236 - - [23/Apr/2019:13:50:00 +0000]
"GET /mysite.html HTTP/1.1" 200 426 "-" "Mozilla/5.0
(Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/73.0.3683.86 Safari/537.36"
2019-04-23T13:51:36.581Z 89.138.90.236 - -
[23/Apr/2019:13:51:34 +0000] "GET /mysite.html HTTP/1.1" 200 427 "-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
为了确保Logstash正在聚合数据并将其运送到Elasticsearch中,请使用:
curl -X GET "localhost:9200/_cat/indices?v"
如果一切正常,你应该看到列出了logstash- *索引:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_task_manager zmMH6yy8Q6yg2jJHxq3MFA 1 0 2 0 45.4kb 45.4kb
yellow open logstash-2019.04.23-000001 rBx5r_gIS3W2dTxHzGJVvQ 1 1 9 0 69.4kb 69.4kb
green open .kibana_1 rv5f8uHnQTCGe8YrcKAwlQ 1 0 5 0
如果你没有看到该索引,恐怕是时候进行一些调试了。 查看此博客文章,了解调试Logstash的一些技巧。
我们现在要做的就是在Kibana中定义索引模式以开始分析。 这是在管理→Kibana索引模式下完成的。
Kibana将识别索引,因此只需在相关字段中对其进行定义,然后继续选择时间戳字段的下一步:
创建索引模式后,你将看到所有已解析和映射字段的列表:
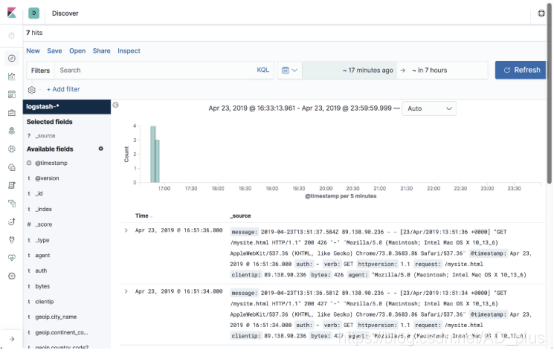
打开“发现”页面开始分析数据!
总结:
弹性数据管道是任何生产级ELK部署中所必需的。 日志对于将事件组合在一起至关重要,在紧急情况下最需要它们。 我们无法让我们的日志记录基础结构在最需要的确切时间点发生故障。 Kafka和类似的代理在缓冲数据流方面发挥着重要作用,因此Logstash和Elasticsearch不会在突然爆发的压力下崩溃。
上面的示例是课程的基本设置。 生产部署将包括多个Kafka实例,大量数据和更复杂的管道。 这将涉及大量的工程时间和资源,需要加以考虑。 不过,这里的说明将帮助你了解入门方法。 我还建议你看一下我们的文章,解释如何记录Kafka本身。
喜欢这篇文章的可以点个赞,欢迎大家留言评论,记得关注我,每天持续更新技术干货、职场趣事、海量面试资料等等
如果你对java技术很感兴趣也可以加入我的java学习群 V–(ddmsiqi)来交流学习,里面都是同行,验证【优快云2】有资源共享。
不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代

















&spm=1001.2101.3001.5002&articleId=103562172&d=1&t=3&u=71d73e7d1b2143678bf5d8a37b562dff)
 2060
2060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









