




一、记录下关于权重下标变换的理解
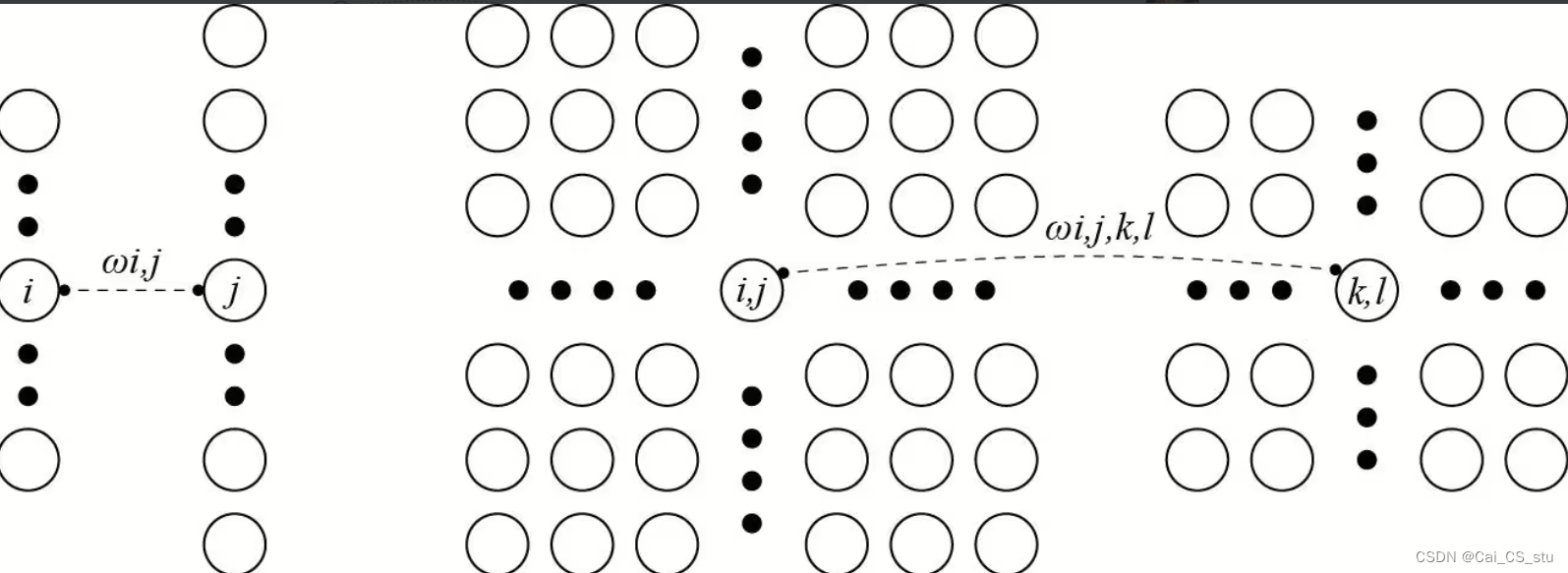
从原来的Wi,j到Wi,j,k,l是从二维到四维的过程,如下图所示
对全连接层使用平移不变性(如:卷积核在移动过程是不变的)和局部性(如:卷积核有一定大小)得到卷积层,这是卷积层的引入,下方Vi,j,a,b--->Va,b表示了平移不变性,给a,b限制在||内保证了局部性:
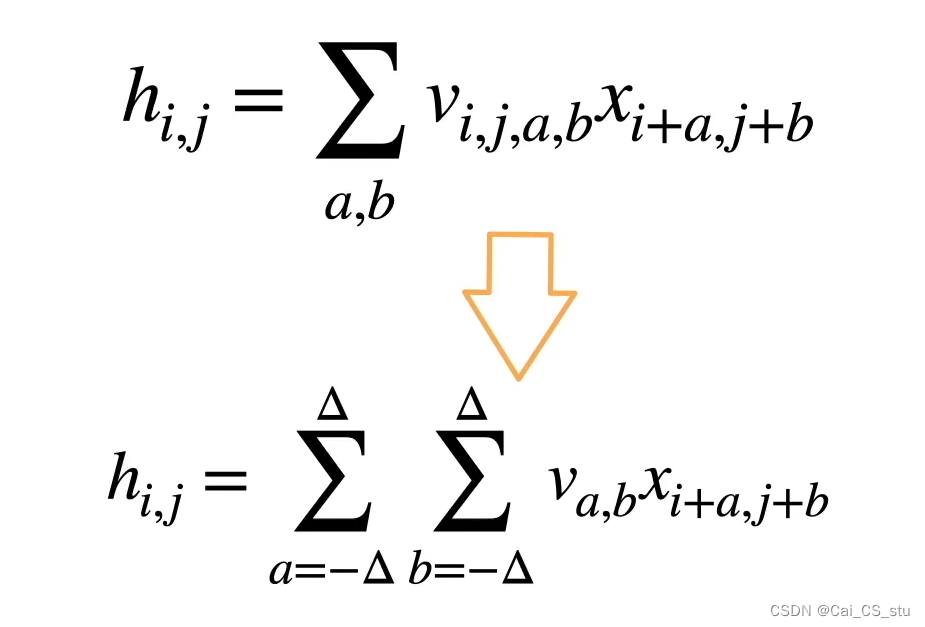
二、维度变换公式

从原来的Wi,j到Wi,j,k,l是从二维到四维的过程,如下图所示
对全连接层使用平移不变性(如:卷积核在移动过程是不变的)和局部性(如:卷积核有一定大小)得到卷积层,这是卷积层的引入,下方Vi,j,a,b--->Va,b表示了平移不变性,给a,b限制在||内保证了局部性:
 134
1910
726
134
1910
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























