




例一:存储学生对象并遍历

1.分析:
同姓名,同年龄认为是同一个学生意味着姓名和年龄相同的所有学生都只记作一个学生
->意味着键即学生对象(Student)需要去重
->对于HashMap集合的键,由于学生对象(Student)属于引用数据类型,且学生对象(Student)位于键的位置,重写hashCode方法和equals方法就能实现键即学生对象(Student)的唯一性
2.解答:
a.易错点:
number1:Student类属于引用数据类型,如果想要打印Student类的属性值就必须重写Student类的toString方法,否则打印的就是地址值
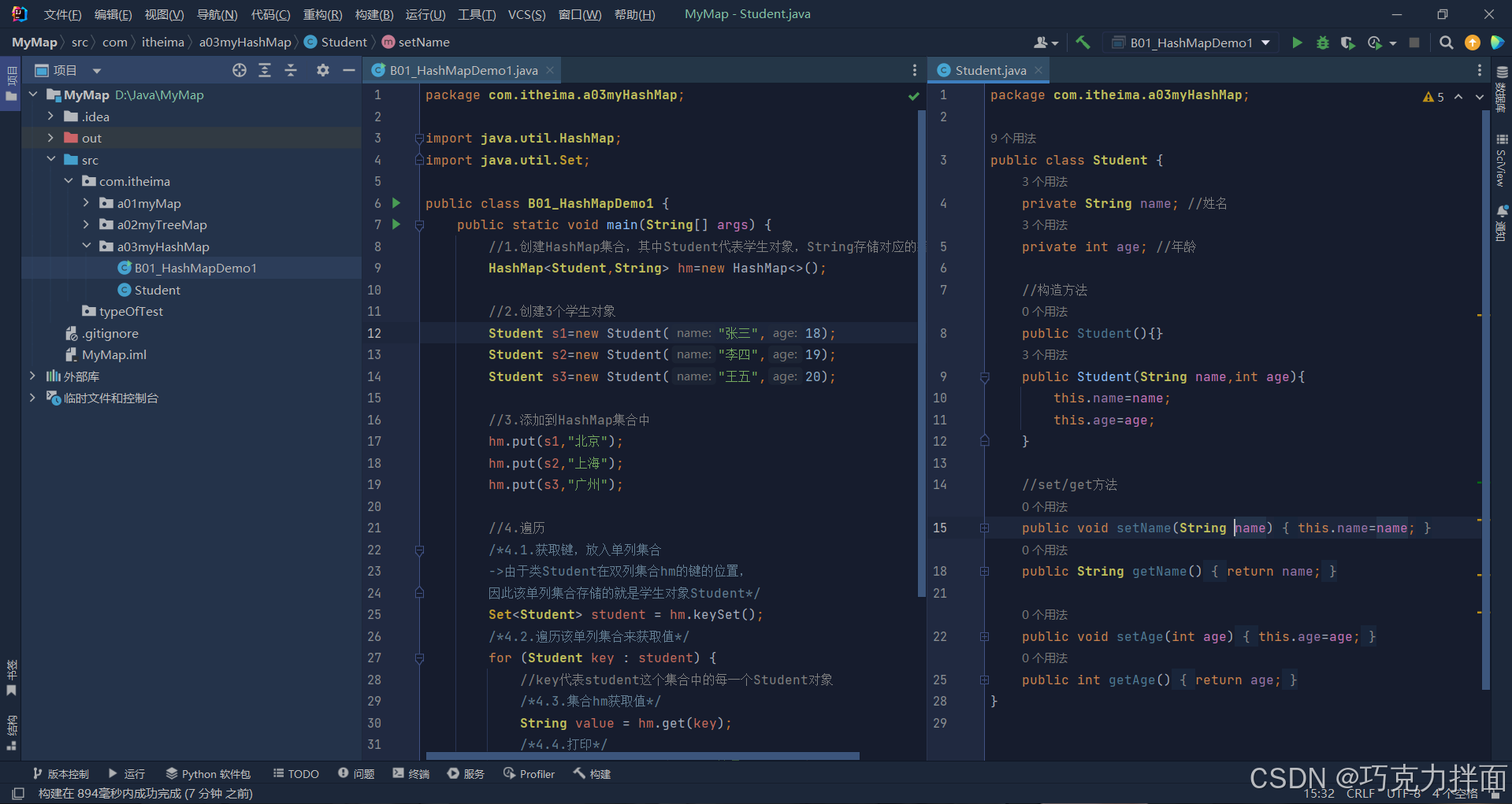
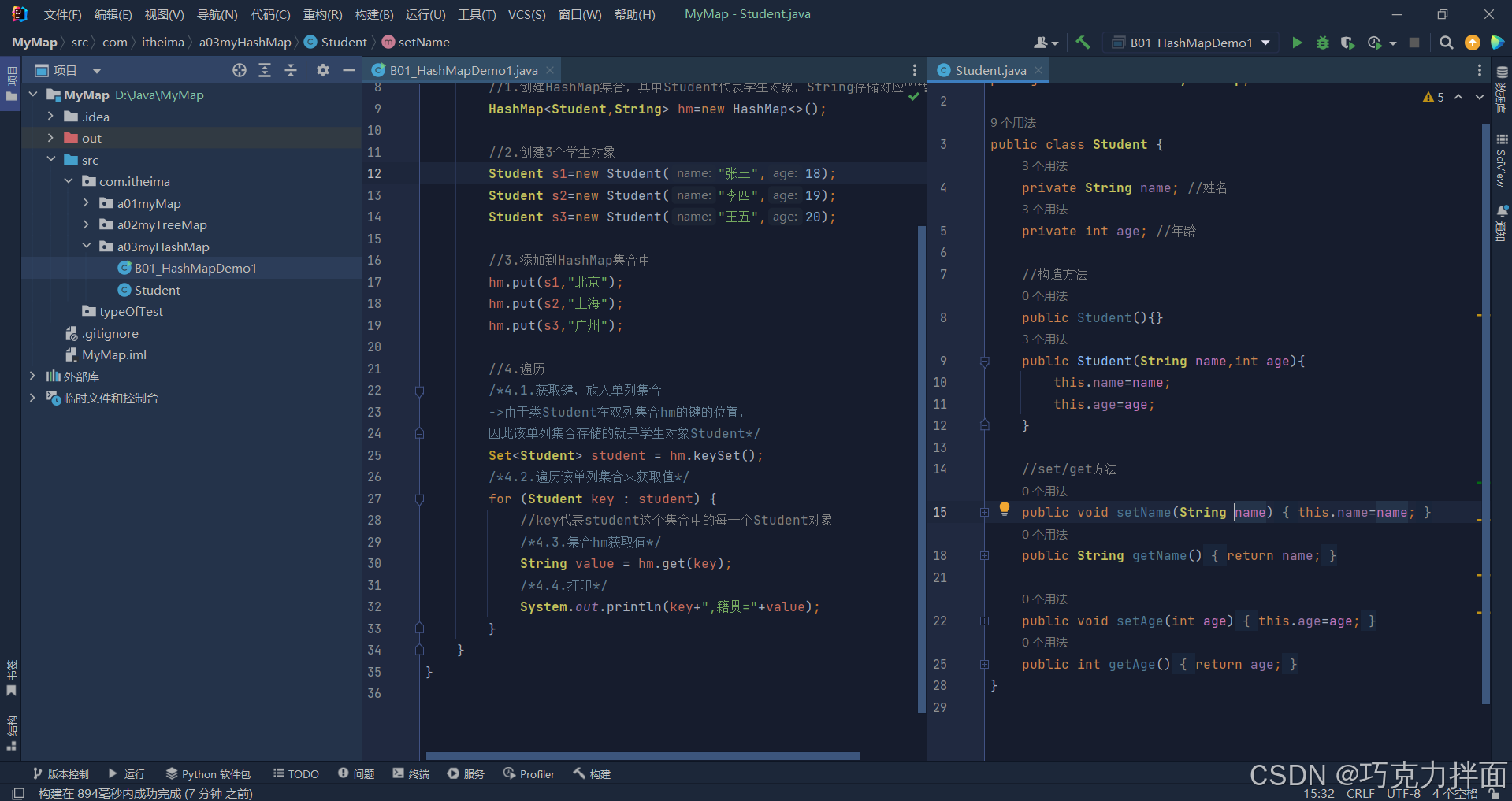
由于Student类中没有重写toString方法,因此打印Student对象即键时,打印的是键的地址值:
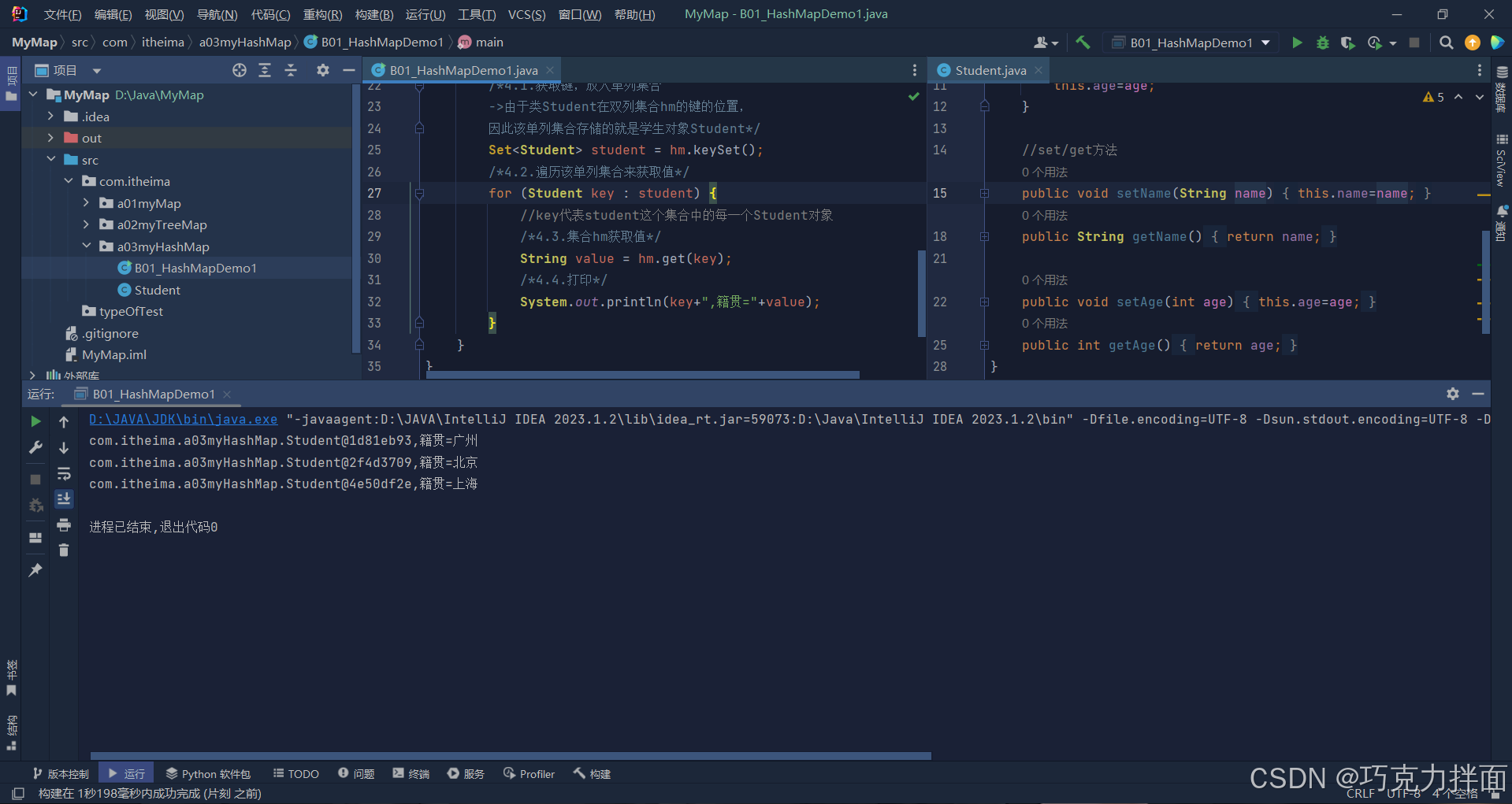
因此为了打印出正确的属性值,就需要重写类Student中的toString方法。
number2:要想实现HashMap集合的键的去重操作,就必须重写equals方法和hashCode方法
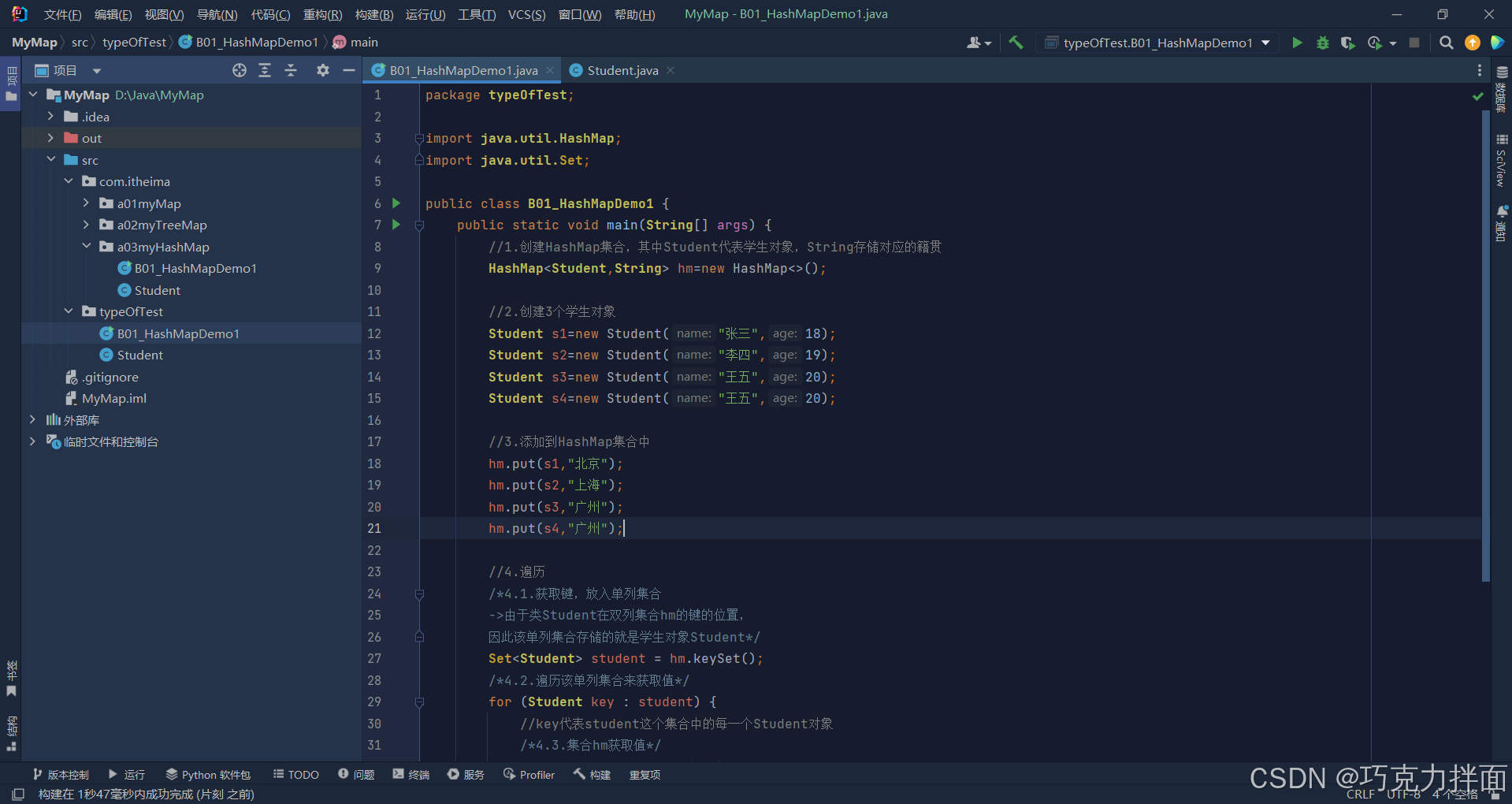
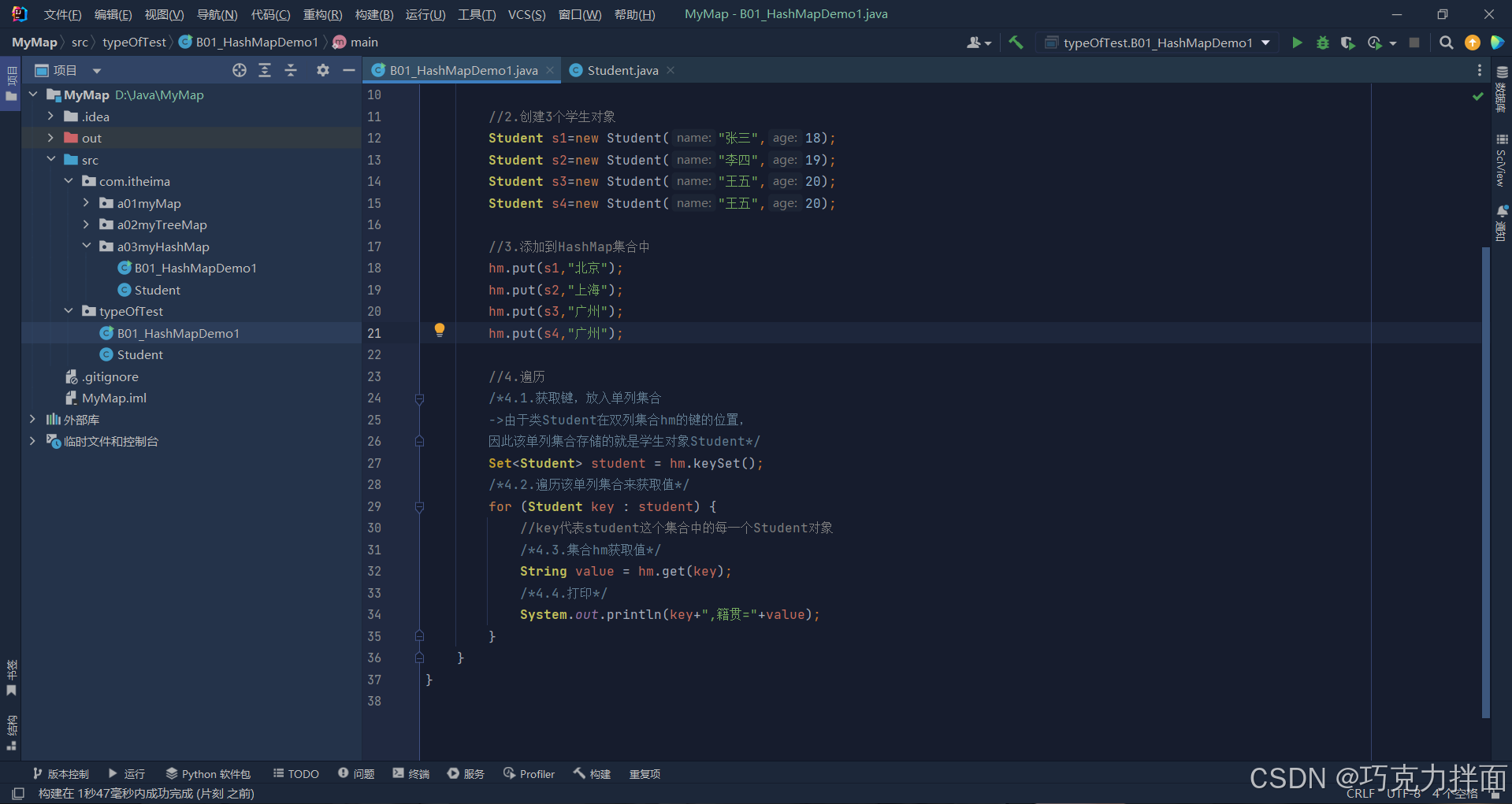
数据s3和s4的属性值一样,而且s3和s4是Student型,此时位于HashMap集合的键的位置,由于Student类中没有重写equals方法和hashCode方法,此时就不会去除重复的数据,运行结果如下->注:去重只针对键,和值无关:
b.解法:
Student类:
package com.itheima.a03myHashMap;
import java.util.Objects;
public class Student {
private String name; //姓名
private int age; //年龄
//构造方法
public Student(){}
public Student(String name,int age){
this.name=name;
this.age=age;
}
//set/get方法
public void setName(String name){
this.name=name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age=age;
}
public int getAge(){
return age;
}
//toString方法:为了打印出属性值
@Override
public String toString() {
return "Student{" + "name=" + name + "," + "age=" + age + "}";
}
//重写equals方法和hashCode方法:为了实现键的去重
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
遍历方式一:键找值
package com.itheima.a03myHashMap;
import java.util.HashMap;
import java.util.Set;
public class B01_HashMapDemo1 {
public static void main(String[] args) {
//1.创建HashMap集合,其中Student代表学生对象,String存储对应的籍贯
HashMap<Student,String> hm=new HashMap<>();
//2.创建3个学生对象
Student s1=new Student("张三",18);
Student s2=new Student("李四",19);
Student s3=new Student("王五",20);
Student s4=new Student("王五",20);
//3.添加到HashMap集合中
hm.put(s1,"北京");
hm.put(s2,"上海");
hm.put(s3,"广州");
hm.put(s4,"深圳");
//4.遍历
/*4.1.获取键,放入单列集合
->由于类Student在双列集合hm的键的位置,
因此该单列集合存储的就是学生对象Student*/
Set<Student> student = hm.keySet();
/*4.2.遍历该单列集合来获取值*/
for (Student key : student) {
//key代表student这个集合中的每一个Student对象
/*4.3.集合hm获取值*/
String value = hm.get(key);
/*4.4.打印*/
System.out.println(key+",籍贯="+value);
}
}
}
遍历方式二:依次获取键值对对象即Entry对象
package com.itheima.a03myHashMap;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class B01_HashMapDemo1 {
public static void main(String[] args) {
//1.创建HashMap集合,其中Student代表学生对象,String存储对应的籍贯
HashMap<Student,String> hm=new HashMap<>();
//2.创建3个学生对象
Student s1=new Student("张三",18);
Student s2=new Student("李四",19);
Student s3=new Student("王五",20);
Student s4=new Student("王五",20);
//3.添加到HashMap集合中
hm.put(s1,"北京");
hm.put(s2,"上海");
hm.put(s3,"广州");
hm.put(s4,"深圳");
//4.遍历
/*4.1.获取键值对对象*/
Set<Map.Entry<Student, String>> entries = hm.entrySet();
/*4.2.遍历entries集合,去得到里面的每一个键值对对象*/
for (Map.Entry<Student, String> entry : entries) {
/*4.3.利用entry调用对应的方法获取键和值*/
Student key = entry.getKey(); //键
String value = entry.getValue(); //值
/*4.4.打印*/
System.out.println(key+",籍贯="+value);
}
}
}
遍历方式三:Lambda表达式
未简化Lambda表达式前:
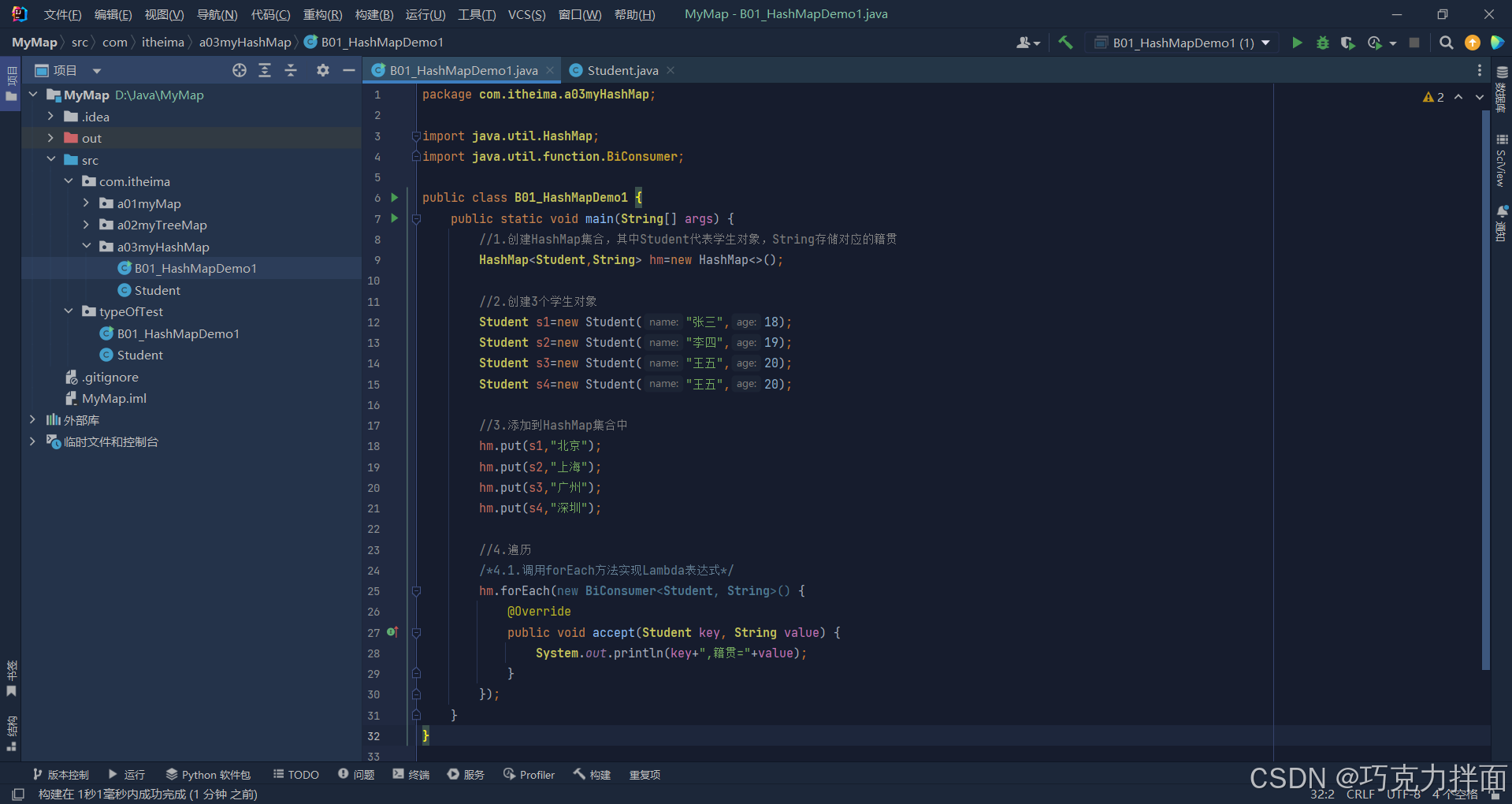
简化Lambda表达式:
package com.itheima.a03myHashMap;
import java.util.HashMap;
public class B01_HashMapDemo1 {
public static void main(String[] args) {
//1.创建HashMap集合,其中Student代表学生对象,String存储对应的籍贯
HashMap<Student,String> hm=new HashMap<>();
//2.创建3个学生对象
Student s1=new Student("张三",18);
Student s2=new Student("李四",19);
Student s3=new Student("王五",20);
Student s4=new Student("王五",20);
//3.添加到HashMap集合中
hm.put(s1,"北京");
hm.put(s2,"上海");
hm.put(s3,"广州");
hm.put(s4,"深圳");
//4.遍历
/*4.1.调用forEach方法实现Lambda表达式*/
hm.forEach( (key,value) -> System.out.println(key+",籍贯="+value) );
}
}
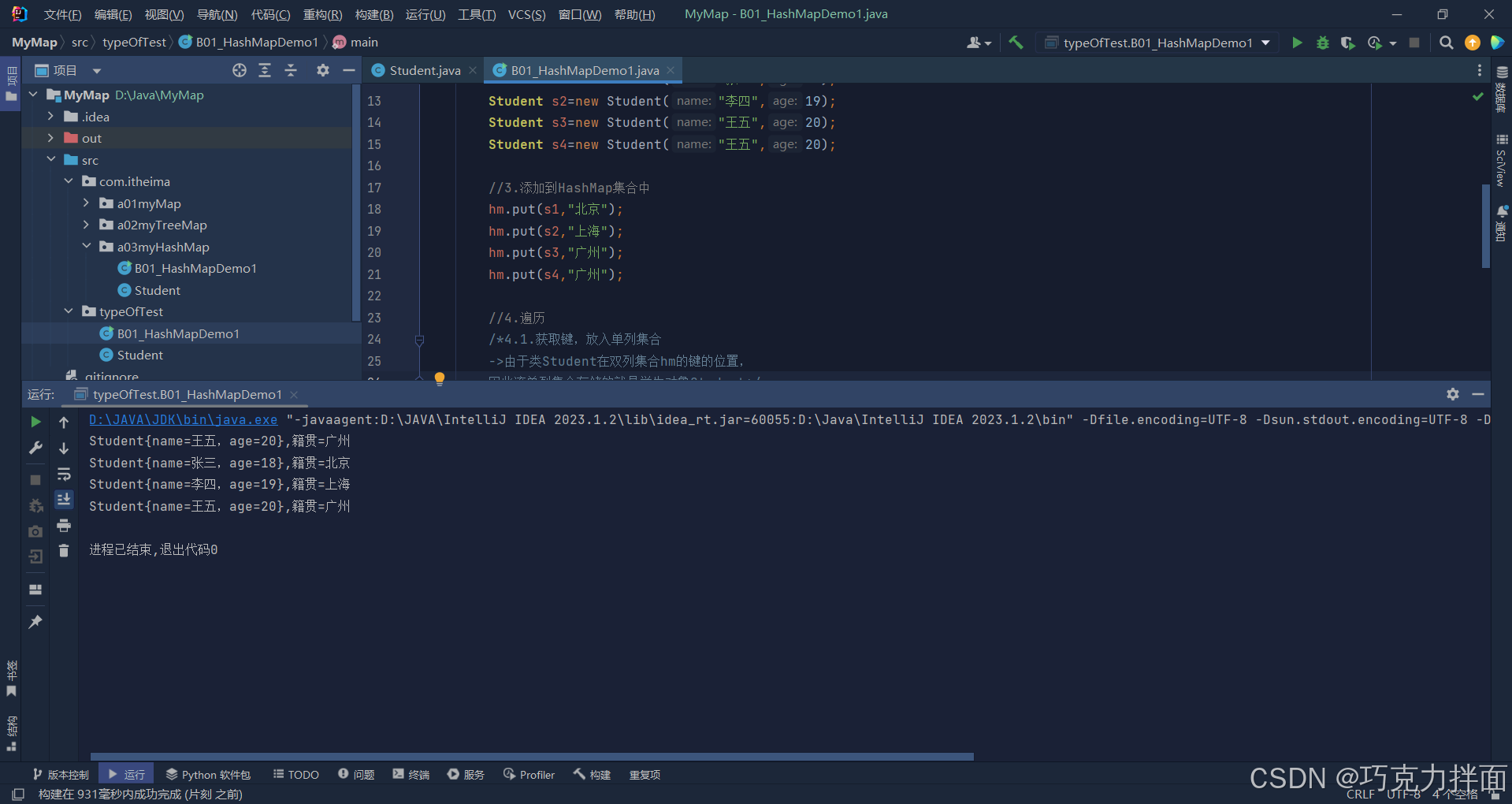
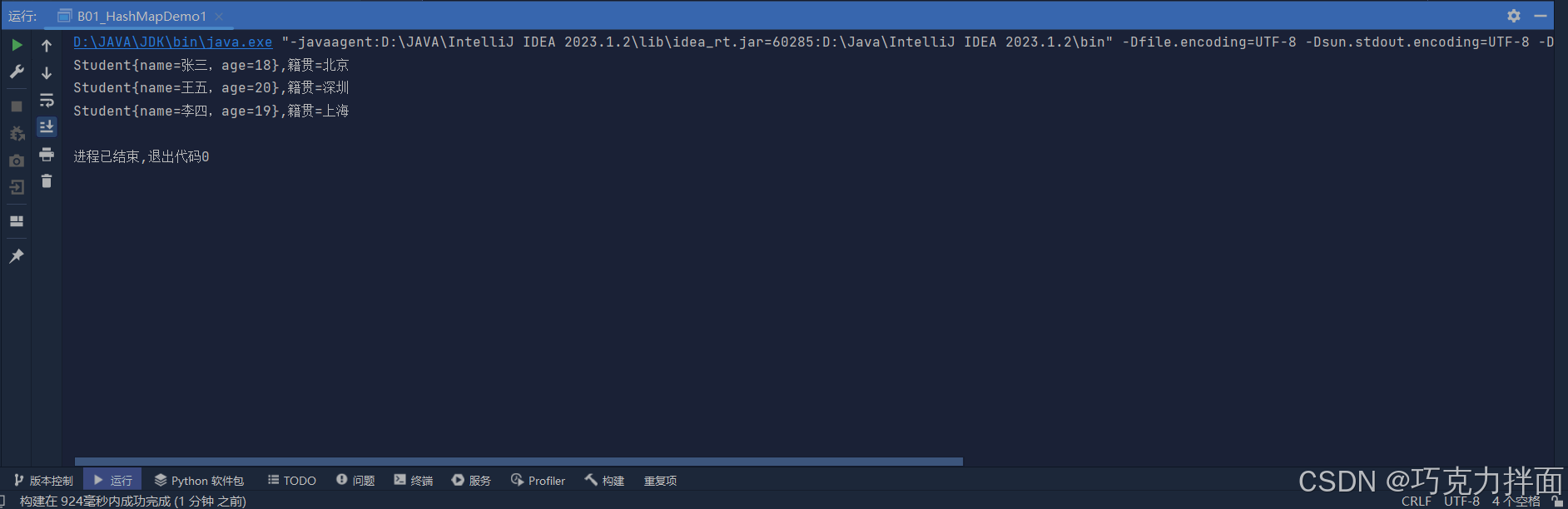
运行结果:
注:键的位置上s3和s4重复了,但由于s4比s3后添加,所以s4会覆盖s3,因此s3和s4中最终打印的是s4的数据,其他同理。
例二:Map集合案例-统计投票人数

1.分析:
本题设计到了统计,因此可以利用计数器,由于有4个景点,因此可以给4个景点分别定义一个计数器进行各自统计,最终得出哪个景点去的人数最多即可
->但这样的方案并不合理,因为如果景点有几千个乃至上万个,难不成要定义几万个计数器吗?再如果景点个数未知,那又如何定义计数器呢?
->所以当要统计的数据比较多或者要统计的数据不知道有多少种时,可以利用Map集合进行统计
2.解答:
解法1:计数器统计(但效率低,因为只适用于统计数据少的场景)
package a33MyMap;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Test {
public static void main(String[] args) {
//1.创建集合数组对象
Map<String,String>[] hm=new HashMap[5];
//HashMap<String,char>[] hm= new java.util.HashMap<String, char>()[5];是错误的
//2.输入属性值
hm[0]=new HashMap<>();
hm[0].put("张三","A");
hm[1]=new HashMap<>();
hm[1].put("李四","B");
hm[2]=new HashMap<>();
hm[2].put("王五","C");
hm[3]=new HashMap<>();
hm[3].put("赵六","D");
hm[4]=new HashMap<>();
hm[4].put("李七","B");
//定义数组记录值出现的个数
int[] count={0,0,0,0};//0到3索引依次记录A到D的个数,初始都为0
//3.遍历进行获取不同值的个数
//hm为数组名,不能直接hm.keySet(),因为hm此时代表地址值
//需要遍历数组里的对象再调用keySet方法
for (int i = 0; i < hm.length; i++) {
//3.1 获取键
Set<String> keys = hm[i].keySet();
//3.2 键找值
for (String key : keys) {
String value = hm[i].get(key);
//3.3 调用记录不同值出现的个数的方法
method(value,count);
}
}
//4.调用方法得出最大数对应的索引
int numberIndex=maxElementIndex(count);
//5.打印结果
switch (numberIndex){
case 0 -> System.out.println("去A的最多");
case 1 -> System.out.println("去B的最多");
case 2 -> System.out.println("去C的最多");
case 3 -> System.out.println("去D的最多");
}
}
//定义记录某个值出现的个数的方法
private static void method(String value,int[] count){
switch (value){
case "A" -> count[0]++;
case "B" -> count[1]++;
case "C" -> count[2]++;
case "D" -> count[3]++;
}
}
//查找数组最大元素对应的索引的方法
private static int maxElementIndex(int[] count){
//1.先认为最大为第一个元素,还需要记录索引
int maxNumber=count[0];
int index=0;
//2.遍历数组
for (int i = 1; i < count.length; i++) {
if(count[i]>maxNumber) {
maxNumber=count[i];
index=i;
}
}
//3.返回索引
return index;
}
}
解法2:利用Map集合(适用于要统计的内容比较多或者不知道要统计多少内容的时候)

思路:
创建一个Map集合,键存储景点的名称,值统计该景点被投票的次数,接下来就可以依次得到80名学生每一个人的投票信息:
如果第一名学生投A景点,此时就需要到Map集合中键的位置判断A景点是否存在,显然不存在,表示A景点是第一次出现,此时就把景点A添加到键处,值为1->表示第一名学生统计完毕之后,A景点被投了一次票;
如果第二名学生投A景点,此时就需要到Map集合中键的位置判断A景点是否存在,显然景点A已经存在了,因此键不变,景点A对应的值加1->表示第二名学生统计完毕之后,A景点被投了两次票;
如果第三名学生投B景点,此时就需要到Map集合中键的位置判断B景点是否存在,显然不存在,表示B景点是第一次出现,此时就把景点B添加到键处,值为1->表示第三名学生统计完毕之后,B景点被投了一次票;
以此类推。
package com.itheima.a01myMap;
import java.util.*;
public class A06_HashMapDemo2 {
public static void main(String[] args) {
//1.需要先让同学们投票
//定义一个数组,存储4个景点
String[] arr = {"A", "B", "C", "D"};
//利用随机数模拟80个同学的投票,并把投票的结果存储起来
/* 用于不知道每个景点被投了几次,所以用集合存储*/
ArrayList<String> list = new ArrayList<>();//该集合用来存储投票的结果
Random r = new Random();
for (int i = 0; i < 80; i++) {
int index = r.nextInt(arr.length);//arr长度为4,则随机数范围为[0,4),结果为随机索引
list.add(arr[index]);//arr[index]为投票结果即景点
}
//2.统计投票个数
/*如果要统计的东西比较多,不方便使用计数器思想。
此时可以定义Map集合,利用集合进行统计
*/
HashMap<String, Integer> hm = new HashMap<>();//键为景点名,值为景点被投的次数
//遍历list集合依次得到投票信息
for (String name : list) { //list集合记录的是投票结果即景点名,是字符串型,name表示景点名
//判断当前的景点名在Map集合中是否存在
if (hm.containsKey(name)) { //注:景点名name位于键的位置
/*此时代表景点已存在*/
/*先获取当前景点已经被投票的次数即获取值-->get方法通过键获取值,
count的值是由hm.get(name)决定的*/
Integer count = hm.get(name);//也可以用int型,因为有自动拆箱功能
//表示当前景点又被投了一次
count++;
//把新的次数再次添加到集合当中
hm.put(name, count);
} else {
/*此时代表景点不存在
-->添加该景点名,并且出现个数为第一次*/
hm.put(name, 1);
}
}
//3.打印hm集合,即可看到键和值的结果
System.out.println(hm);
//4.求值的最大值
/* 需要先设一个第三方变量作为参照物,但参照物以A,B,C,D都不合适,
因为如果A景点没有人投,集合中就会没有A景点,不符合题意
-->但每个景点投票次数最小都为0,因此可以把0作为参照物
*/
int max = 0;
//遍历hm-->只需要值,因此键找值的遍历方式更好一些
Set<Map.Entry<String, Integer>> entries = hm.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
Integer count = entry.getValue();
if (count > max) max = count;
}
System.out.println(max);
//5.判断哪个景点的投票次数跟最大值一样,如果当前景点的投票次数和最大值一样,打印该景点
for (Map.Entry<String, Integer> entry : entries) {
Integer count = entry.getValue();
if (count == max) System.out.println(entry.getKey());
//遇到和最大值一样的值不能立刻停止循环,因为和最大值一样的值可能不止一个
}
/*注:第四步和第五步是不能同步进行的,因为只有得到了值的最大值,才能找出值的最大值对应的景点*/
}
}

















 1387
1387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









