




分区表
1.了解什么是分区表
2.了解分区表的好处
3.熟悉分区表的几种类型
4.掌握分区表的操作【重点】
提醒:
分区是应用在百万千万级或亿级数据库
一般的数十万信息不用用到分区,索引优化已经够用
什么是分区表?

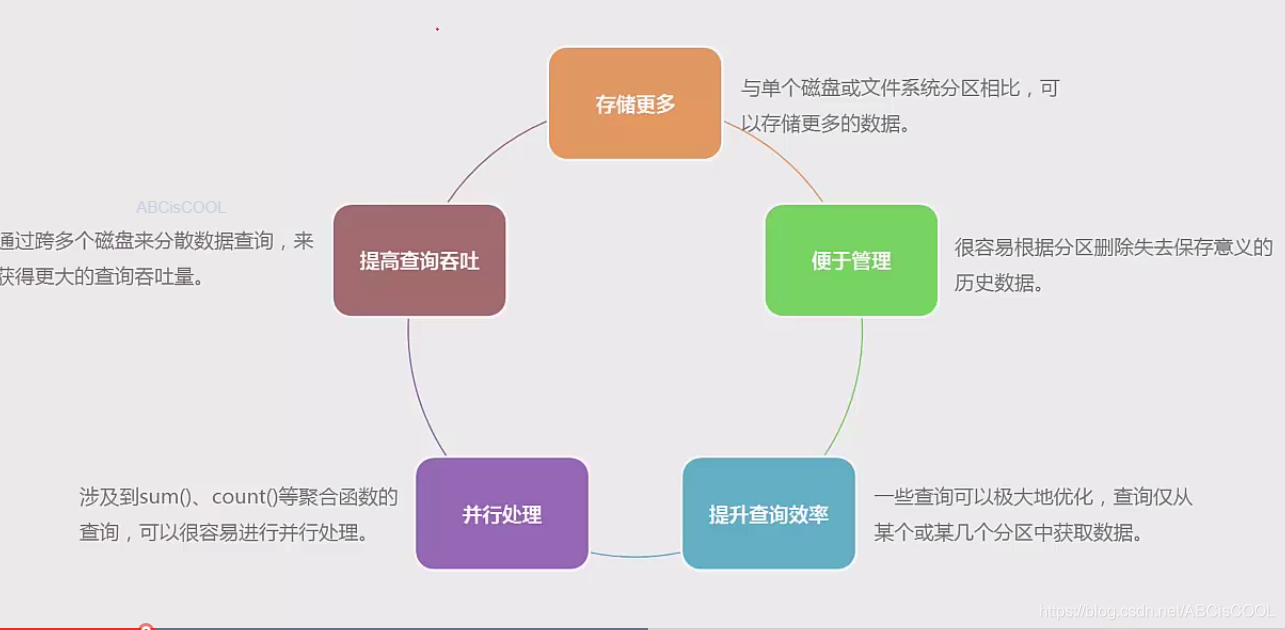
分区表的好处
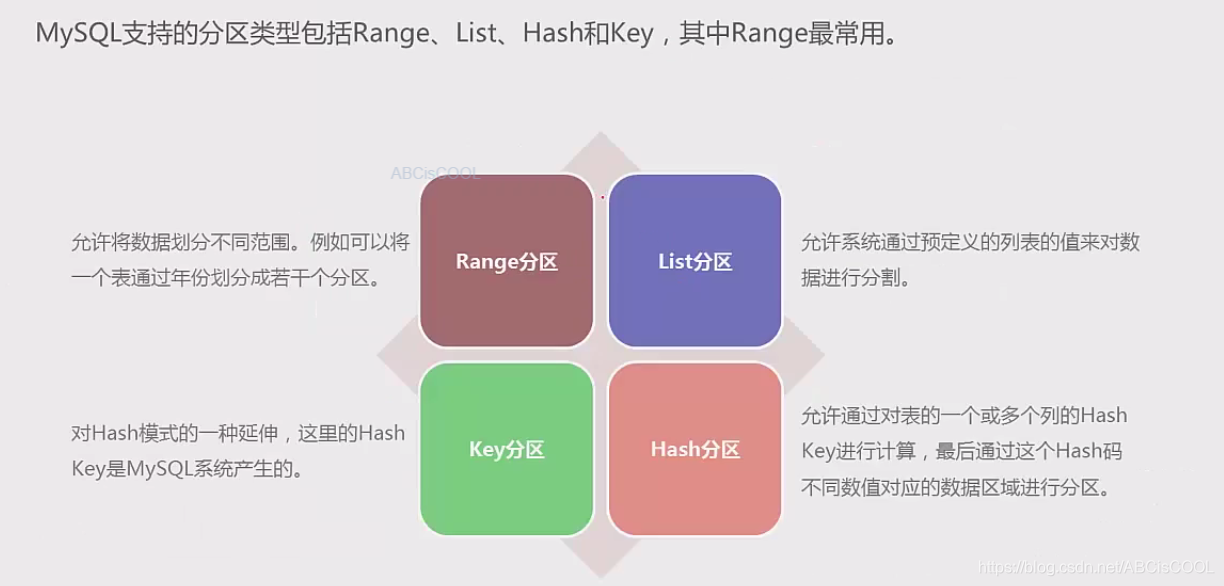
分区表的四种类型
用的最多的Range分区
Range分区是基于属于一个给定连续区间的列值,把多行分配给分区
#Range分区示例
create table user_range(
id int not null auto_increment,
name varchar(30),
age int ,
birthday date,
province int,
primary key(id , age)
)
partition by RANGE(age)(
partition p1 VALUES LESS THAN(20) DATA DIRECTORY = 'c:/data/p1',
partition p2 VALUES LESS THAN(40) DATA DIRECTORY = 'c:/data/p2',
partition p3 VALUES LESS THAN(60) DATA DIRECTORY = 'c:/data/p3',
partition p4 VALUES LESS THAN MAXVALUE DATA DIRECTORY = 'c:/data/p4'
);
list 分区
List分区是基于列值匹配一个离散值集合的某个值来进行选择。
#List分区示例
create table user_list(
id int not null auto_increment ,
name varchar(30),
age int,
birthday date,
province int,
primary key(id,province)
)
partition by List(province)(
partition p1 VALUES IN (1,3,5,7,9,11,13,15,17,19,21)
partition p2 VALUES IN (2,4,6,8,10,12,14,16,18,20,22)
partition p3 VALUES IN (23,24,25,26,27,28,29,30,31,32,33,34)
);
Hash分区
Hash分区是基于用户定义的表达式的返回值来进行选择的分区
#Hash分区示例
create table user_hash(
id int not null auto_increment,
name varchar(30),
age int,
birthday date,
province int,
primary key(id,birthday)
)
partition by Hash(YEAR(birthday))
partition 5;
Key分区
Key分区类似于Hash分区,但这里的Hash Key 是由MySQL系统产生的。
#Key分区示例
create table user_key(
id int not null auto_increment,
name varchar(30),
age int,
birthday date,
province int,
primary key(id,birthday)
)
partition by Key(age)
partition 5;
分区的其他操作
#新增分区
alter table 'user' add partition(partition p5 VALUES LESS THAN MAXVALUE);
#对已存在的表进行分区
alter table 'user' partition by RANGE(age)(
partition p1 VALUES LESS THAN(20) DATA DIRECTORY = 'c:/data/p1',
partition p2 VALUES LESS THAN(40) DATA DIRECTORY = 'c:/data/p2',
partition p3 VALUES LESS THAN(60) DATA DIRECTORY = 'c:/data/p3',
partition p4 VALUES LESS THAN MAXVALUE DATA DIRECTORY = 'c:/data/p4'
);
#删除分区(分区下的数据也会被删除)
alter table 'user' drop partition p5;
#移除分区(数据不会被删除)
alter table 'user' remove partition;
实操
创建表格并分区
create table user_range(
id int not null auto_increment,
name varchar(30),
age int ,
birthday date,
province int,
primary key(id , age)
)
partition by RANGE(age)(
partition p1 VALUES LESS THAN(20) DATA DIRECTORY = 'c:/data/p1',
partition p2 VALUES LESS THAN(40) DATA DIRECTORY = 'c:/data/p2',
partition p3 VALUES LESS THAN(60) DATA DIRECTORY = 'c:/data/p3',
partition p4 VALUES LESS THAN MAXVALUE DATA DIRECTORY = 'c:/data/p4'
);
插入两条数据
insert into user_range(name,age,province) values ('张三',18,1);
insert into user_range(name,age,province) values ('李四',30,1);
18岁应该在p1区,30岁在p2区
查询,可以看到如果没有使用分区字段age,所查询的分区还是用了四个,即全表查询
mysql> explain select * from user_range where name='张三'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_range
partitions: p1,p2,p3,p4
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2
filtered: 50.00
Extra: Using where
1 row in set, 1 warning (0.01 sec)
如果是使用age查询,验证了是通过单一分区来查询
mysql> explain select * from user_range where age=18\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_range
partitions: p1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.04 sec)
mysql> explain select * from user_range where age=30\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_range
partitions: p2
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)

















 3280
3280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









