




AlexNet训练分类猫狗数据集
视频程序以及猫狗数据集:
链接:https://pan.baidu.com/s/1Tqs5bFY2wVvtGeuFBWV1Yg
提取码:3zrd
一、数据集与训练集的划分
可以通过该段程序将数据集进行训练集以及测试集按照一定比例的划分
未划分前的数据集目录结构:
--data_name
-Cat
1.png
2.png
3.png
4.png
5.png
-Dog
6.png
7.png
8.png
9.png
10.png
按照split_rate = 0.2,训练集:测试集 = 8:2,划分后的数据目录结构:
--data
-train
-Cat
1.png
2.png
3.png
4.png
-Dog
6.png
7.png
8.png
9.png
-val
-Cat
5.png
-Dog
10.png
split_data.py:
import os
from shutil import copy
import random
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
# 获取data文件夹下所有文件夹名(即需要分类的类名)
file_path = 'C:/Users/86159/Desktop/AlexNet/data_name'
flower_class = [cla for cla in os.listdir(file_path)]
# 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录
mkfile('data/train')
for cla in flower_class:
mkfile('data/train/' + cla)
# 创建 验证集val 文件夹,并由类名在其目录下创建子目录
mkfile('data/val')
for cla in flower_class:
mkfile('data/val/' + cla)
# 划分比例,训练集 : 验证集 = 8 : 2
split_rate = 0.2
# 遍历所有类别的全部图像并按比例分成训练集和验证集
for cla in flower_class:
cla_path = file_path + '/' + cla + '/' # 某一类别的子目录
images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称
num = len(images)
eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称
for index, image in enumerate(images):
# eval_index 中保存验证集val的图像名称
if image in eval_index:
image_path = cla_path + image
new_path = 'data/val/' + cla
copy(image_path, new_path) # 将选中的图像复制到新路径
# 其余的图像保存在训练集train中
else:
image_path = cla_path + image
new_path = 'data/train/' + cla
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar
print()
print("processing done!")
二、数据增强:
1.归一化处理
data_normalize.py
"""
修改ROOT为数据集的标签的上层目录则可以得到,数据集的均值以及标准差
其中 dog 与 cat 为数据集的标签
目录结构:
-data
-train
-cat
1.jpg
2.jpg
-dog
3.jpg
4.jpg
"""
from torchvision.transforms import ToTensor#用于把图片转化为张量
import numpy as np#用于将张量转化为数组,进行除法
from torchvision.datasets import ImageFolder#用于导入图片数据集
import tqdm
ROOT = r"/home/zxz/Proj/DP/Do/demo_01/data/person_car_dataset/val"
means = [0,0,0]
std = [0,0,0]#初始化均值和方差
transform=ToTensor()#可将图片类型转化为张量,并把0~255的像素值缩小到0~1之间
dataset=ImageFolder(ROOT,transform=transform)#导入数据集的图片,并且转化为张量
num_imgs=len(dataset)#获取数据集的图片数量
# 对图像进行Totensor的变换后,图片为 CHW 格式
for img,a in tqdm.tqdm(dataset,total=num_imgs,ncols = 100):#遍历数据集的张量和标签
for i in range(3):#遍历图片的RGB三通道
# 计算每一个通道的均值和标准差
means[i] += img[i, :, :].mean()
std[i] += img[i, :, :].std()
mean=np.array(means)/num_imgs
std=np.array(std)/num_imgs#要使数据集归一化,均值和方差需除以总图片数量
print(f"mean: {mean}")#打印出结果
print(f"std: {std}")
三、AlexNet网络搭建
网络图片
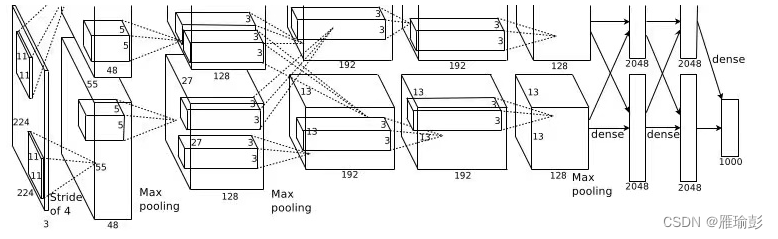
Alexnet.py
from torch import nn
import torch
import torch.nn.functional as F
class MyAlexNet(nn.Module):
def __init__(self):
super(MyAlexNet, self).__init__()
self.c1 = nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4, padding=2)
self.ReLU = nn.ReLU()
self.c2 = nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, stride=1, padding=2)
self.s2 = nn.MaxPool2d(2)
self.c3 = nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=1, padding=1)
self.s3 = nn.MaxPool2d(2)
self.c4 = nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1)
self.c5 = nn.Conv2d(in_channels=192, out_channels=128, kernel_size=3, stride=1, padding=1)
self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5348
5348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









