




大模型部署与商业模式介绍
目录
一、大模型部署介绍
1. 大模型部署流程
(1) 大模型部署流程

①模型转换:使用不同的框架部署模型要求的模型格式不同,如果当前权重文件格式与框架要求的格式不一致,则需要做模型转换,同时根据部署策略,分布式权重与单个权重也需要做转换
②模型压缩:模型压缩可以提高模型推理速度、减少内存占用,但性能会有所降低,可根据实际场景选择
③运行参数配置:配置模型的部署策略(是否并行)、推理参数(推理长度、top_k等) -> 推理长度越长,推理参数越多,需要更多的物理设备
④工程编译:目前有使用纯C++实现的模型推理,这种部署方式需要对工程进行编译后才能执行
⑤编程框架接入:由于大模型存在无法实时联网、幻觉等问题,因此实际部署重会通过框架将大模型与数据库、其余应用配合使用,从而得到更准确、更符合业务的回答
总结
模型转换:权重文件与框架格式不一致,需要进行处理
模型压缩:提供模型推理速度,牺牲部分性能,降低设备需要的方式
运行参数配置:设置大模型参数的信息,批处理量,运行长度
工程编译:转为C++模型进行推理
框架接入:给大模型接入框架,实现联网,知识库等功能
2. 大模型常用压缩方法
(1) 模型压缩的必要性
随着模型参数量的增加,模型部署的成本和推理性能都受影响,部分影响如下:
①推理性能
(1)硬件访存带宽受限时,权重越大,数据搬运开销越大
(2)显存容量不足时,只能CPU部署、推理性能较差
②部署成本
(1)权重越大,对存储容量、计算资源开销、显存容量要求越高,就需要更多的设备来部署
(2)Batch Size、序列长度的增加,KV Cache(KV缓存)也会不断上升,对访存造成较大压力
目前大显存、访存带宽高的设备架构都较高,为了能在消费级设备上部署、推广大模型,模型压缩必不可少
(2) 大模型压缩趋势
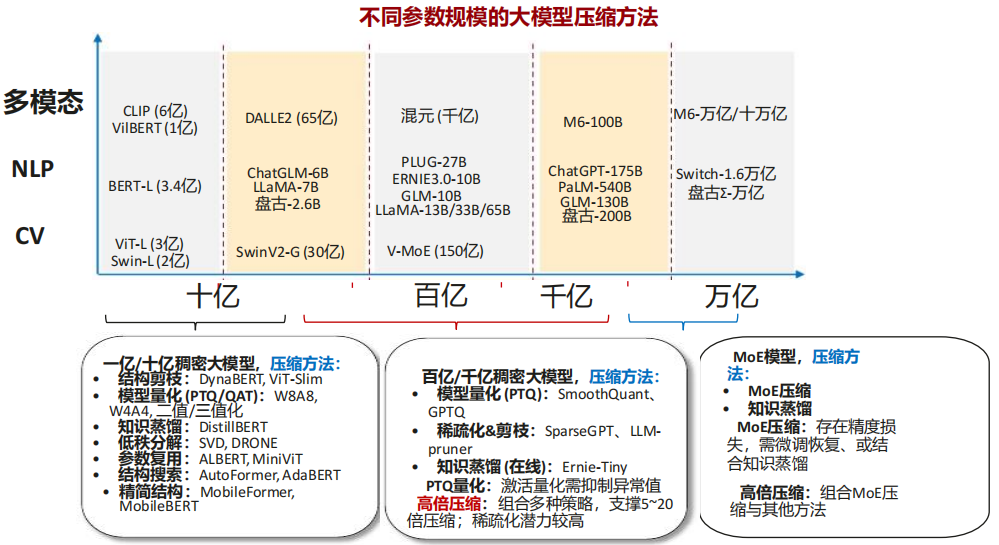
知识蒸馏:让小模型(学生模型)模仿大模型(教师模型)的行为或知识,从而在保持轻量化的同时提升小模型的性能
MoE压缩:通过稀疏化激活专家(Experts)来压缩MoE模型的计算量,保持模型容量的同时大幅降低计算开销
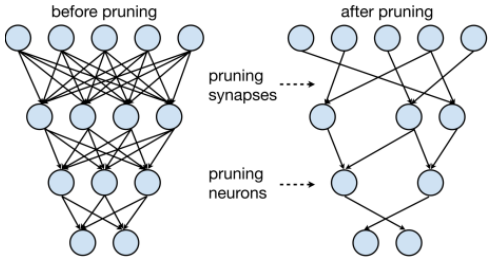
(3) 模型剪枝
是模型压缩重一种重要的技术,其基本思想是将模型中不重要的权重和分支裁剪掉,将网络结构稀疏化,进而得到参数量更小的模型。然而,剪枝也可能导致模型性能的下降,因此需要在模型大小和性能之间找到一个平衡点。神经元在神经网络中的连接在数学上表示为权重矩阵,因此剪枝即是将权重矩阵中一部分元素变为零元素。剪枝过程如下图所使,目的是减去不重要的突触或神经元
(4) 知识蒸馏
是一种带有迁移学习理念的模型压缩技术。较大、较复杂的网络虽然通常具有很好的性能,但是也存在很多的冗余信息,因此运算量以及资源的消耗都非常多。而所谓的Distilling就是将复杂网络中的有用信息提取出来迁移到一个更小的网络上,这样学习来的小网络可以具备和大的复杂网络相接近的性能效果,并且也大大的节省了计算资源。这个复杂的网络可以看成一个教师,而小的网络则可以看成是一个学生
(5) 训练后量化PTQ
训练后量化会量化预训练的浮点模型和使用部分训练数据来校准模型。包含Data-Free和Label-Free算法,这两种训练后量化算法可在昇腾推理平台进行,同时支持有/无校准数据集的PTQ量化场景,可将Float浮点模型转换为定点INT8模型,达到模型压缩、减少计算量、缩短推理时延的目的
①Data-Free量化:无需获取输入数据集,即可对模型进行量化;通过翻转优化权重,多尺度渐进迭代优化的方法在无数据场景实现了有效量化(一对一做映射)
②Label-Free量化:用户需要提供少量数据集做矫正,相比于无数据量化,Label-Free量化的输入数据符合原数据分布,量化精度会更高
(6) 量化感知训练QAT
量化感知训练是在模型中插入伪量化模块模拟量化模型在推理过程中进行的舍入和钳位操作,从而在训练过程中提高模型对量化效应的适应能力,获得更高的量化模型精度。在这个过程中,所有计算(包括模型正反向传播计算和伪量化节点计算)都是以浮点计算实现的,在训练完成后才量化为真正的INT8模型 -> 量化只调整精度,参数量没有改变
总结
剪枝:降低模型参数量,取出一些不重要的模型参数(参数置为0)
蒸馏:降低模型参数量,利用一个小参数的模型,学习大参数模型的知识,从而替换大模型的方式
量化:降低计算精度,将模型从高的计算精度(FP32,FP16)转为低的计算精度(int8)
3. 大模型常用部署工具


4. 大模型推理加速技术
(1) 大模型推理加速技术介绍
大模型推理加速技术众多,但是关注的指标和优化方向基本类似,具体如下:
①推理重点关注指标:吞吐量,时延
②推理优化方向:资源调度方向,模型压缩,使用专用芯片
MoE混合专家:一种基于Gating Function的稀疏模型架构,在增加模型参数的同时,保持FLOPs基本不变,实现sub-linear的模型规模增长模型 -> 通过门控机制在每层仅激活少量专家(子模型),实现“大模型容量,小模型计算”的高效训练与推理
K/V Cache:将推理过程中先前迭代中的K、V矩阵缓存下来,避免重复计算,用内存换时间
Attention算子优化:Flash Attention(通过算子融合节省Attention中间结构访存开销),Paged Attention(借鉴操作系统内存管理的思路,建立logic kv block和physical kb block的映射,通过block table存储索引)
专用芯片Groq:消除不确定性硬件、Data locality优化、降低通信开销、提高资源利用率等
5. 大模型应用开发
(1) 为什么需要大模型编程框架接入工具
虽然目前大模型在语言理解、问答等方面表现了优秀的能力,但还存在一些问题:
①时效性问题:目前大模型迭代周期长,无法快速获取最新数据
②“幻觉”现象:问答中会出现杜撰、编造的事实、数据等
为了解决大模型上述存在的问题,研究人员通过让大模型外挂知识库、调用其他工具(如联网模块)等来输出更准确、有效的问答,在大模型应用开发时,如果有一个工具可以很方便把大模型和知识库等结合起来,那将大大提高大模型相关应用开发效率,其中LangChain就是典型的代表
(2) LangChain
LangChain框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。可以将LLM模型(对话模型、embedding模型等)、向量数据库、交互层Prompt、外部知识、外部代理工具整合到一起,进而可以自由构建LLM应用
LangChain核心组件:
①模型输入/输出(Model I/O):与语言模型交互的接口
②数据连接(Data connection):与特定应用程序的数据进行交互的接口
③链(Chains):将组件组合实现端到端应用
④记忆(Memory):用于链的多次运行之间持久化应用程序状态
⑤代理(Agents):扩展模型的推理能力,用于复杂的应用的调用序列
⑥回调(Callbacks):扩展模型的推理能力,用于复杂的应用的调用序列
(3) Gradio
Gradio可以直接在Python中通过友好的Web界面演示机器学习模型,能够以一个富有视觉效果的界面呈现融合后的知识库和LLM
(4) FastAPI
为了方便大模型应用项目的管理,现有的项目通常采用前后端分离的方式搭建,前后端数据通过json格式进行传输
FastAPI是一个用于构建API的现代、快速(高性能)的Web框架,非常方便用于搭建前后端分离的应用,通过定义相关参数和请求方式,即可通过本地端口来使用相关服务
6. 大模型本地部署展望


二、大模型商业介绍
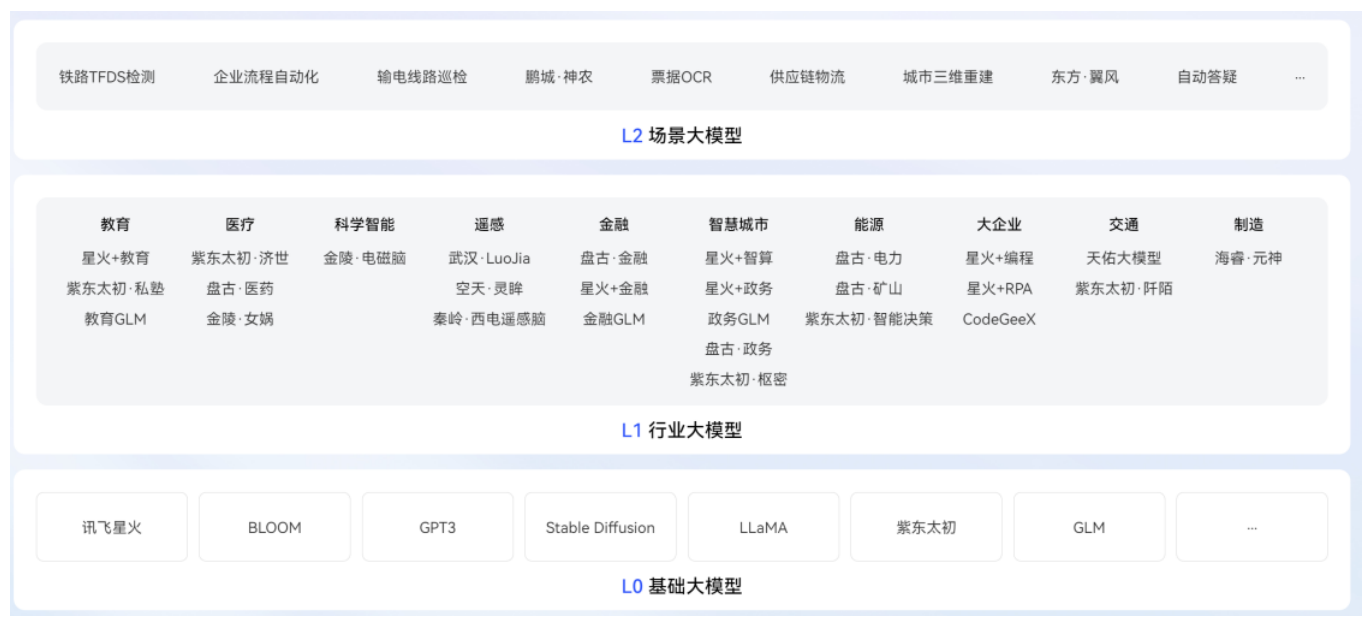
(1) 大模型应用场景


















 2700
2700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









