





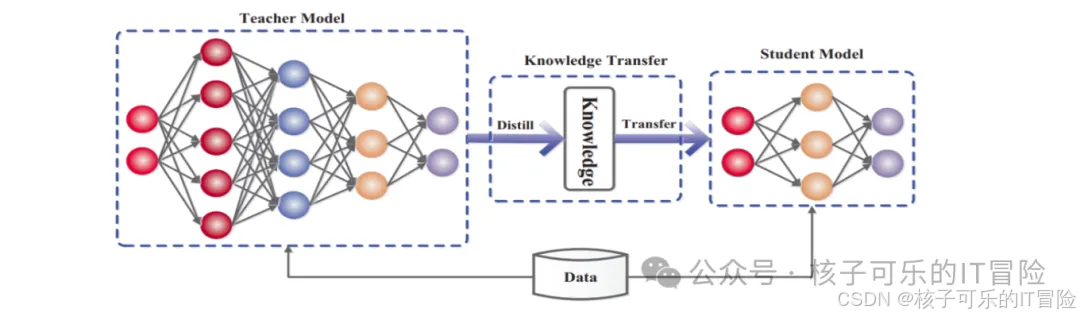
知识蒸馏的实质,是将知识从大模型转移至小模型。这项技术之所以出现,是因为人们发现很多问题只须使用大模型知识容量中的一小部分。因此,知识蒸馏就成为显著降低资源成本、保持性能水平的有效方法。
上图所示,为知识蒸馏中的大型“教师”模型与小型“学生”模型,后者使用教师提供的知识以实现相似甚至更高的回答准确性。
知识蒸馏的意义
神经网络规模巨大,往往包含亿级乃至十亿级参数,其训练和部署必然对基础设施的内存和算力提出极高要求。但在应用端,多数模型又得想办法部署在算力较弱的系统当中(包括移动设备和边缘设备),这就构成了一对核心矛盾。
知识蒸馏的意义就是在保持准确性的前提下,尽可能缩减模型体量,确保其能够在更多场景下发挥作用。
知识蒸馏的实践应用
这里我们以自动驾驶汽车为例。车载图像识别系统中使用的深度学习模型基于卷积神经网络(CNN),虽然准确性极高,但受高昂的计算和内存成本所限而无法直接部署在车辆本体之内。
为了解决这个问题,知识蒸馏能够将CNN学到的知识转移至更小、更高效的模型当中,例如MobileNet或SqueezeNet。蒸馏后的模型还须再经训练,尝试模仿CNN在指定标注训练图像上的输出结果。
在训练过程中,损失函数不仅要考虑蒸馏模型输出与真实标注之间的差异,还会比较蒸馏模型与CNN之间的输出质量。在训练完成后,蒸馏模型即可部署在自动驾驶汽车之内。与原始CNN相比,其消耗的算力资源和内存更少,同时仍能保持较高的物体与交通标志识别准确度。
除汽车之外,移动设备上的语音识别也是蒸馏模型的常见用例之一。
知识蒸馏的几种类型
知识蒸馏模型间亦有结构差异之分,为了明确它们的适用范围,我们结合图表一一解释:
基于响应的知识蒸馏
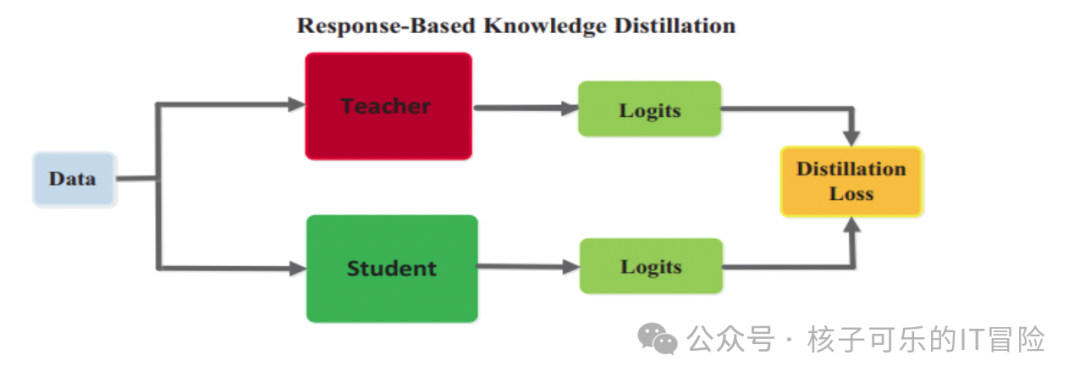
基于响应的知识蒸馏是指从教师网络的输出层(预测)捕捉并传输信息,由学生网络以最小化蒸馏损失直接模仿其最终预测结果。
以自然语言处理(NLP)为例,可以训练大模型根据输入句子生成响应。这种方法往往计算成本高昂,不适合在资源受限的设备上部署。此时可以将大模型的响应输出设为目标,训练学生小模型模仿其预测,确保二者在相同输入句子上具有相似的响应结果。
用例:机器翻译、聊天机器人和问答系统。
基于特征的知识蒸馏
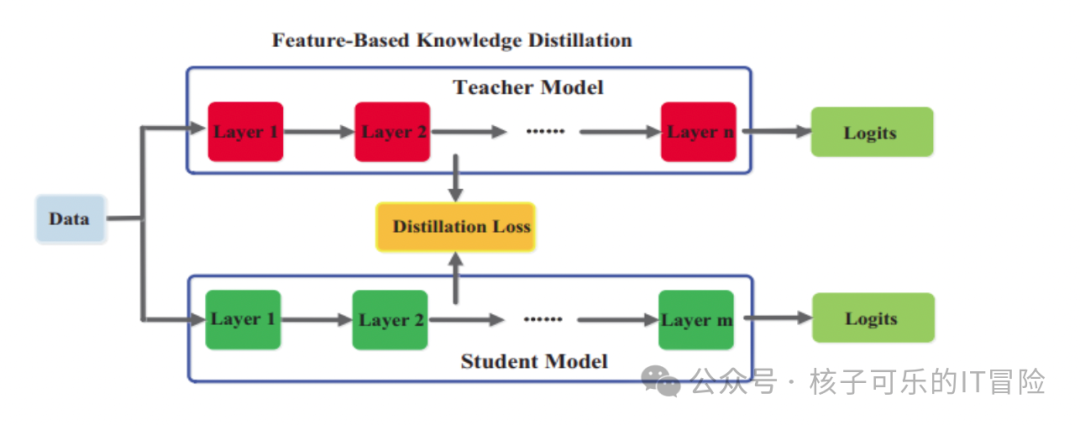
教师模型在训练过程中会通过中间层捕捉数据知识,这也是深度神经网络当中“深度”部分的直接体现。中间层在学会区分特征之后,即可用于训练学生模型。
以图像识别为例,可以通过分析图像中的各个像素训练大模型识别内容。这种方法同样具有极高的计算成本,不适合在资源受限的设备上部署。因此可仅使用输入图像中最重要的特征(例如色彩渐变)来训练学生小模型。
用例:对象检测、自然语言处理和语音识别。
基于关系的知识蒸馏
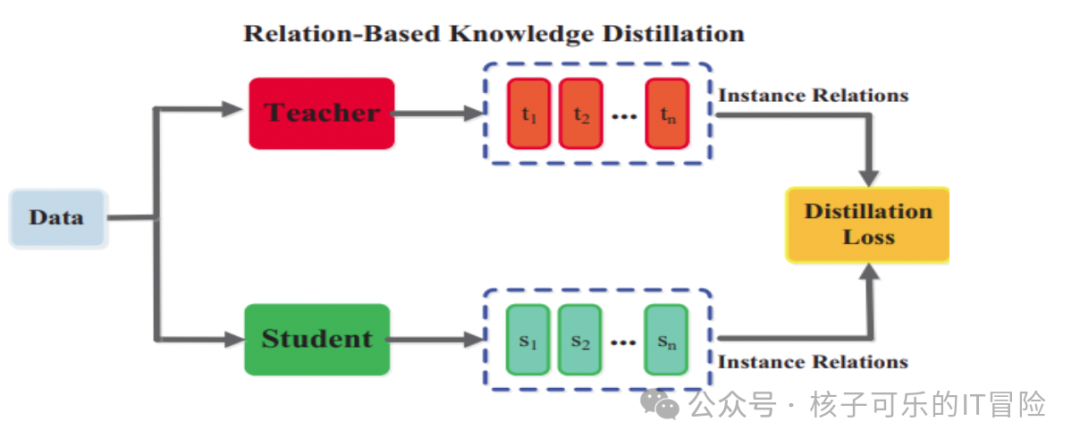
除了神经网络输出层和中间层所表示的知识之外,关于如何捕捉特征图之间关系的知识也可用于训练学生模型,即所谓“基于关系”。我们可以将这种关系建模为特征图、相似性矩阵、特征嵌入或者基于特征的概率分布。
仍以图像识别为例,可以通过分析图像中不同部分(例如边缘、纹理和形状)间的关系来训练大模型识别图中对象。这种方法往往具有极高的计算成本,不适合在资源受限的设备上部署,因此可以训练学生小模型在更低的参数量和计算量下掌握输入数据与输出响应之间的关系。
用例:对象检测和场景分割。
蒸馏模式
知识蒸馏可通过以下方式进行:
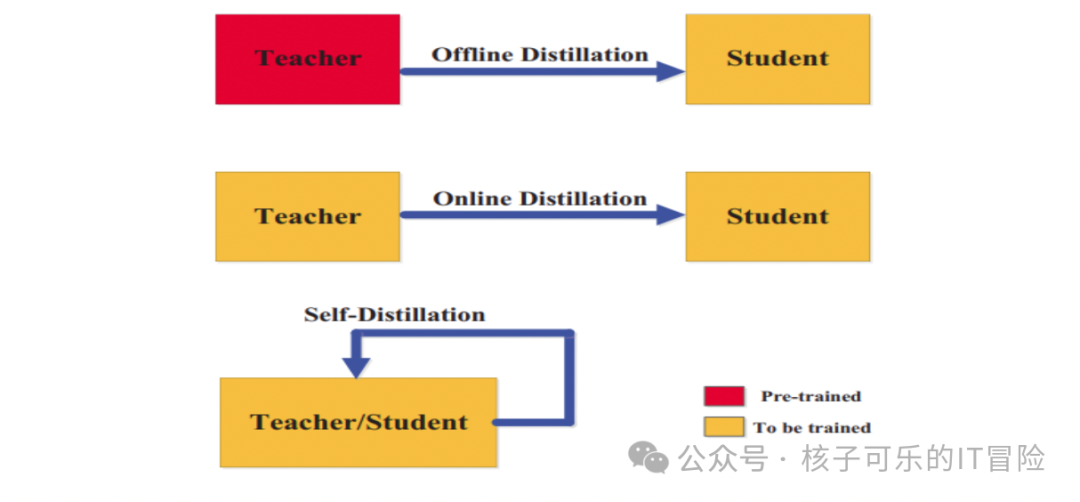
离线蒸馏
作为最常用的蒸馏方法,离线蒸馏使用预先训练的教师模型来指导学生模型。即先在训练数据集上对教师模型进行预训练,再从其中蒸馏出知识以训练学生模型。
随着深度学习技术的发展,目前大量预训练神经网络模型均已开放访问,可结合具体用例充当教师。这也让离线蒸馏成为一种易于实现的成熟技术。
以对象识别为例,教师模型可在大规模图像数据集上接受训练,并针对每张图像存储软目标(即分类标签上的概率分布)。再将这些软目标作为标签,即可在较小图像数据集上训练学生模型。这样哪怕训练数据量有限,学生模型也能继承教师模型的知识、捕捉到对象间的种种细微关系。
在线蒸馏
在某些场景下,预训练模型可能受体量所限而无法用于离线蒸馏。为了解决这一限制,可以使用在线蒸馏,即教师与学生模型在同一端到端训练过程中同时更新。在线蒸馏可使用并行计算实现,因此具有突出的效率优势。
以在线推荐系统为例,教师模型可在大规模用户偏好数据集上接受预训练,用于为每位新用户生成推荐。学生模型则使用教师模型的建议配合用户实际偏好进行训练,实时学习知识并提高推荐准确性。
自我蒸馏
自我蒸馏是指教师与学生使用相同模型。例如,利用来自深度神经网络中较深层的知识来训练较浅层,可以看作是在线蒸馏的一种特殊用例。其中,教师模型在早期轮次中获得的知识可转移至后期轮次,用以训练学生模型。
以图像识别为例,模型可以在数据集及真实标签上接受训练,再尝试对同一数据集进行预测。由此产生的预测结果可作为软目标以重新训练该模型,实现对同一数据集的更佳预测效果。整个过程重复多轮,即模型使用自己的早期预测来提高当前准确性。
一点个人想法
DeepSeek的出现,无疑给每个人带来一份丰厚的新年礼物。在AI成本急剧降低的新时代下,最大的赢家一定是那些几乎能免费享受到顶尖AI产品和服务的消费者与企业。
DeepSeek更为中国的AI力量崛起奠定了基础。除了让生成式AI在这片土地上更加深入人心之外,这位后起之秀与美国AI竞争中取得的相对领先,也必然会进一步激发中国的创新能力,让更多从业者意识到自己完全有机会参与这场决定全人类命运的科技竞赛。
至于美国,则是时候做出艰难的决定了。到底是继续推动禁令、用盘外招遏制他国技术探索;还是放下架子,在承认自己丧失绝对领先地位的同时全身心投入新一轮竞争。拒绝竞争带来的只有慢性死亡,而主动参与至少还有一半获胜机会。如果曾经的科技灯塔有勇气选择正确的道路,相信他们终有一天会感谢DeepSeek这家来自中国、此前寂寂无名的公司。
最后,期待您关注并留下评论,这个年轻的个人栏目将持续为您带来IT领域的更多干货、资讯与趣闻。明天见!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









