






定义

问题引入(重要)
Q1:思考一下给你一个图 我们怎么遍历一个图呢?
回想起我们前面所学习的数据结构,例如链表我们通过它的头结点就能遍历出整条链表,但是图这种数据结构是做不到的,这是因为我们知道链表中元素之间的关系,他们是具有先后关系的,假如给每个节点编个号,他们的编号是唯一的,但是反观图,都不要说遍历了,连我们从图中哪个顶点开始遍历都不晓得
A1:

Q2:我们之前在图的章节介绍过非连通图,也就是说每个顶点不一定是连通的,那么我们一次遍历不完所有的顶点,这时候该怎么办?
A1:
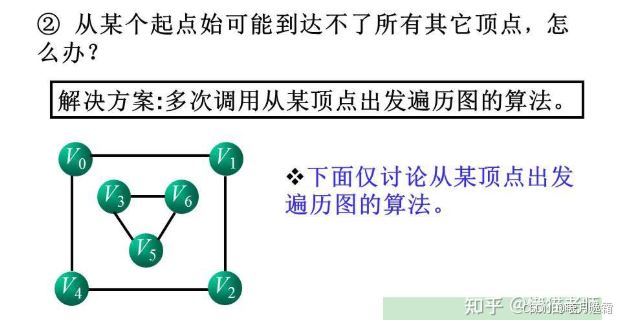
Q3:回忆一下,我们在之前解决的走迷宫问题的时候,每次走到死胡同,都会回到上一次走到的路口继续做选择,通常会给这个迷宫设置一个flag,这里也是类似的,由于图中是非常有可能出现回路的,所以我们需要用类似的手段来去解决以免走入死胡同
A3:

Q4:想一下如果某个顶点是吴彦祖他有多个老婆,他应该先跟谁结婚呢?这就是后续我们学习到deep first和breadth first在优先级上的最大区别
A4:

深度优先遍历(DFS)
铺垫
其实我可以告诉你 我们在前面就学过了深度优先遍历,只不过当时你还不知道而已,深度优先遍历其实核心上还是递归,还是走迷宫的问题,我们走的过程是递推的过程,走到死胡同回退到上一个路口是回归的过程 这里贴上我之前文章 迷宫问题详解
我这个是之前还没学习递归时写的,我是用自己手动创建栈 进行压栈出栈操作来模拟系统栈来实现的,因为一般递归是需要用到堆栈空间的,先压栈保存现场,然后回退的时候,弹栈,回到上一次选择的时候,这么说可能有一些抽象,但是后面其实就后知后觉了,还是建议大家去看懒猫老师的视频,真是通俗易懂!懒猫老师视频课程链接
基本思想
其实简单来说就是一条路走到黑,然后这条路走到头,再回过头看看别的路

对于下面这张图长得样子 其实已经很大程度上给我们减少负担了,仔细观察一下这跟树的遍历是不是有99%的相似度啊,其实我现在就能跟你说广度优先遍历其实跟树的层序遍历99%相似
这样我们用我们的已知去解决未知的问题,这是非常关键的,减少了很多负担 建议大家还是看到就动手用草稿纸上画一下就很明了是怎么回事了
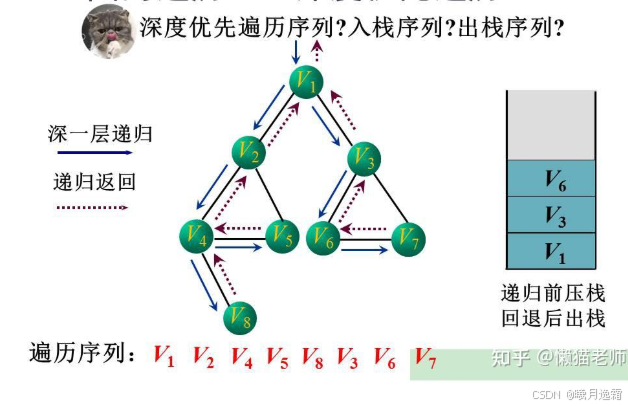
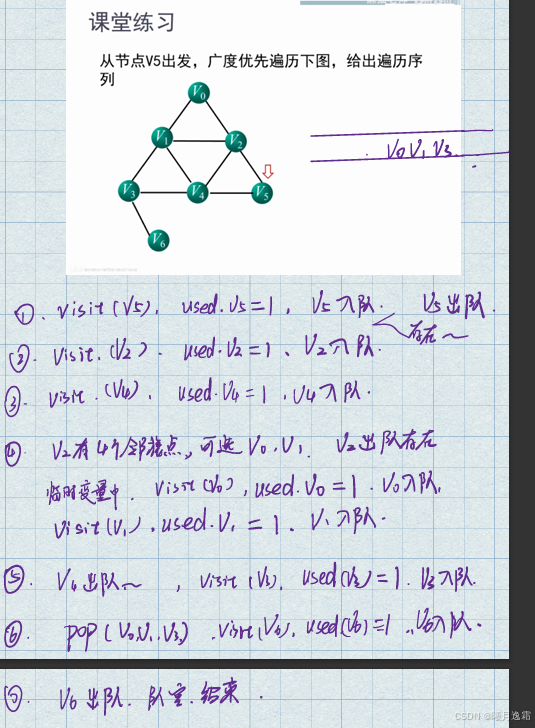
小练习:

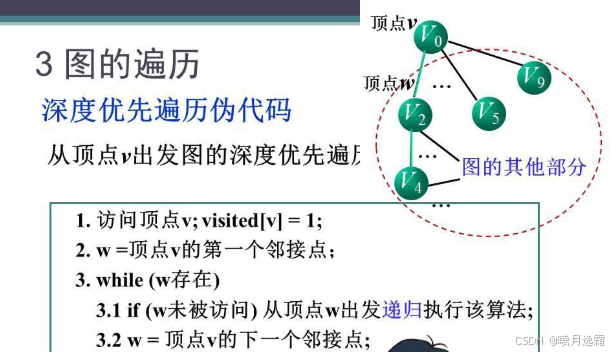
伪代码实现
广度优先遍历(BFS)
基本思想
建议还是对照上面的DFS更好能理解一些

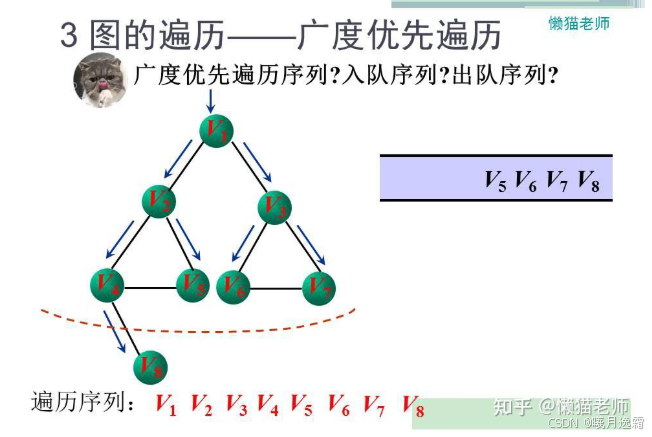
小练习
伪代码

结语
建议大家先三连一下 后续(不一口气更完实际上是懒)我会边学边完善包括但不限于这篇文章,包括具体上代码如何实现(包含C和C++),以及这两种方式遍历的很多不同点如何去形象生动的理解他等等,那么,希望看到这里的你有美好的一天!
*********************************************************************************signed by 曦月逸霜


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









