



背景
目前的报警指标分为以下三种:
- 单指标单工况报警
- 多指标联合报警(可能区分工况)
- 指标权重预计算(可以利用drools+kiesession)
- 多数据源联合告警的情况(告警服务的高级功能,在完成第一版本后会覆盖)
单指标的情况:
erlang
代码解读
复制代码
oc_key_field("trxvbbb_xxx_yyyy", "rms", "highspeed") > 10
多指标联合告警的情况:
erlang
代码解读
复制代码
oc_key_field("trxvbbb_xxx_yyyy", "rms", "highspeed") > 12 && oc_key_field("trxvbbb_xxx_yyyy", "rms", "lowspeed") = 8
指标权重预计算:
需要支持对已经计算出的指标携带权重计算
多数据源联合告警:
对于两条不同类型的测点数据, 比如声音和电流,开一个滑动窗口进行计算. 从边缘端上送过来的数据都是秒级的。滑动窗口的等待时间目前可以设置为1s滑动检测一次
在目前设计的报警编辑规则阶段, 需要支持九种表达式, "(", ")", "<", ">", "=", "&&", "||"
大致的运算逻辑:

名词解释
工况: 目前在算法配置服务可以配置工况实例,一个工况实例可以配置多个规则,每个规则分别代表不同工况, 比如: 高转速,中转速,低转速
数据字段: 在目前的数据链路当中,分发端会接受到两种类型的数据,边缘端上送的测点数据和算法算出来的算法字段. 测点字段和算法字段可以都作为特征值进行计算,如果工况表达式出现工况,需要在满足工况的条件下进行数据字段的计算, 比如: oc_key_field("trxvbbb_xxx_yyyy", "rms", "highspeed") > 10
阈值线: 仅对于数据字段而言, 设置需要比较的阈值
约束条件
- 对于不分工况
- 只计算数据字段的值 比如 oc_key_field("trxvbbb_xxx_yyyy", "rms") > 10, 只计算rms > 10这个表达式
- 推送的标准取决于两个值: 阈值线和报警间隔
- 对于区分工况
- 分等级配置条件
- 收敛策略 (容忍度,恶化通知,报警间隔)
- 重置策略
- 临时报警tag配置
设计的目的以及折中
目前的设计当中, 每个告警等级需要支持多种优先级的计算, 对于复杂的嵌套优先级计算,目前来说比较困难.
例如:
arduino
代码解读
复制代码
( ( oc\_key\_field("trxvbbb\_xxx\_yyyy", "rms", "highspeed") > 12 && oc\_key\_field("trxvbbb\_xxx\_yyyy", "rms", "lowspeed") = 8 ) || oc\_key\_field("trxvbbb\_xxx\_yyyy", "power", "gongkuang2") < 1 ) ) && oc\_key\_field("trxvbbb\_xxx\_yyyy", "mean", "gongkuang3") > 4
分使用体验,可维护性,可拓展性三个维度阐述
- 使用体验: 虽然灵活的表达式定义解了用户进行优先级计算的顺序,但是一旦用户填错,或者修改规则将会变得很难。
- 可维护性: 在程序的角度看来,有两个基本条件需要满足
- 满足工况(gongkuang2,gongkuang3,highspeed)的条件下才进行数据字段的计算
- 工况表达式本身也存在括号,例如oc_key_field(....), 在字符串匹配的解析方面,无法解析计算优先级括号和表达式的函数括号的不同
目前无法做到多级嵌套括号的优先级
- 可拓展性: 后续如果要做指标归因,或者是基于指标的权重计算将会变得很难维护
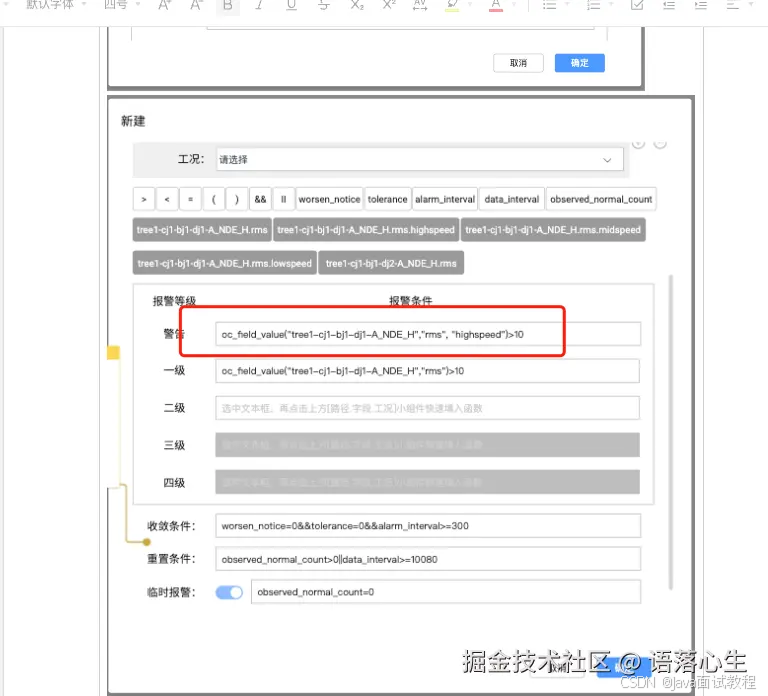
改进后的设计: 指标定义工作流
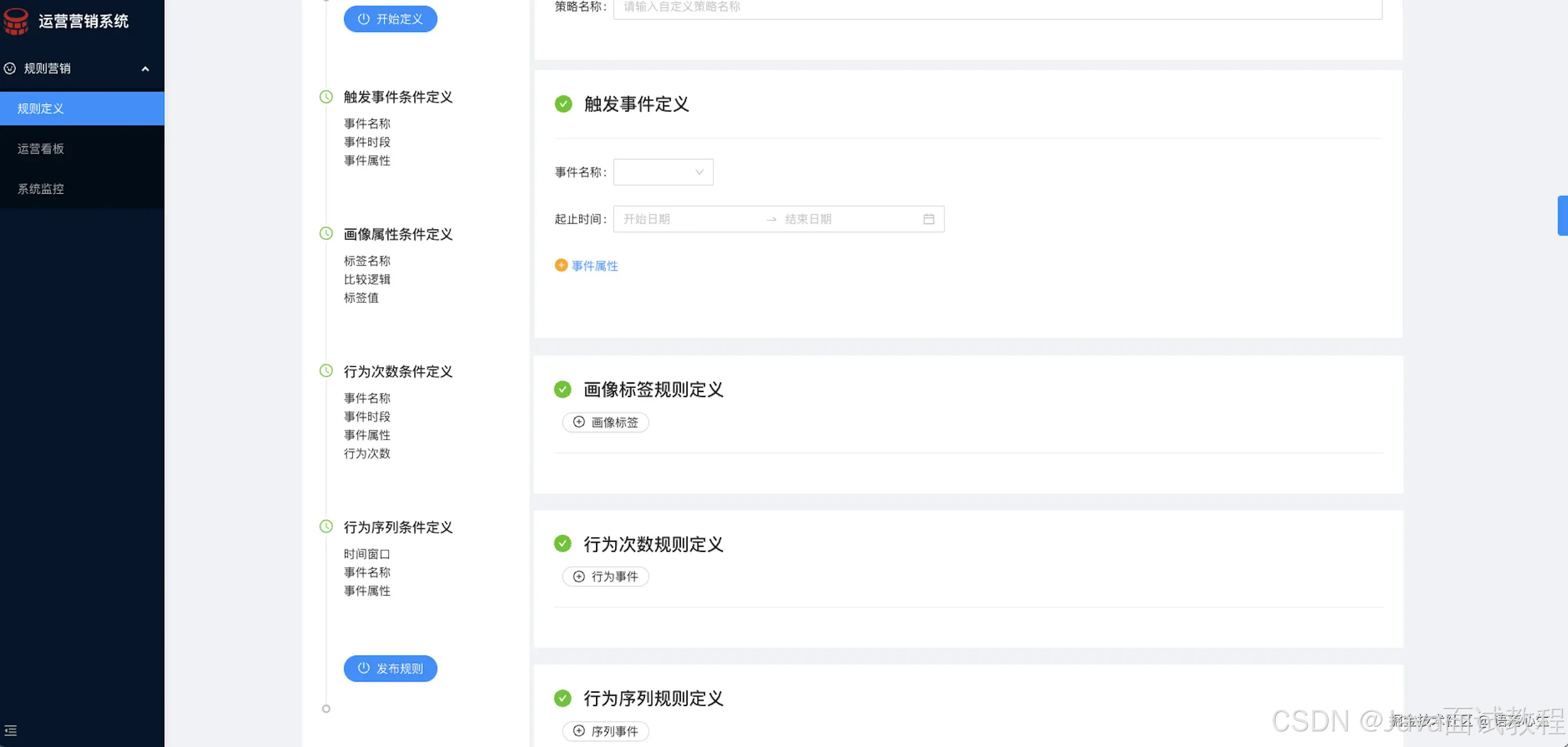
在工作流中,用户可以预先定义需要预先计算出的指标,然后根据约束条件按照顺序定义.
定义流程: 定义基本使用工况 -> 定义需要计算的一级指标,并定义计算出的一级指标名称 -> 定义以一级指标的表达式组成的二级指标,并定义计算出的二级指标名称
用改造前的表达式举例:
arduino
代码解读
复制代码
(( ( oc\_key\_field("trxvbbb\_xxx\_yyyy", "rms", "highspeed") > 12 && oc\_key\_field("trxvbbb\_xxx\_yyyy", "rms", "lowspeed") = 8 ) ) || oc\_key\_field("trxvbbb\_xxx\_yyyy", "power", "gongkuang2") < 1 )&& oc\_key\_field("trxvbbb\_xxx\_yyyy", "mean", "gongkuang3") > 4
按照如上逻辑,用户先计算出优先级最里面的表达式,再依次向外层计算
步骤如下:
- 1.定义待计算的工况指标
- highspeed, lowspeed, gongkuang2, gongkuang3
- 2.定义一级指标
- oc_key_field("trxvbbb_xxx_yyyy", "rms", "highspeed") > 12 , 定义指标metric1, 并将表达式记为 metric1 > 12
- oc_key_field("trxvbbb_xxx_yyyy", "rms", "lowspeed") = 8 , 定义指标metric2, 并将表达式记为 metric2 = 8
- oc_key_field("trxvbbb_xxx_yyyy", "power", "gongkuang2") < 1 , 定义指标metric3, 并将表达式记为 metric3 < 1
- oc_key_field("trxvbbb_xxx_yyyy", "mean", "gongkuang3") > 4 , 定义指标metric4, 并将表达式记为 metric4 > 4
- 定义二级指标
- metric1 > 12 && metric2 = 8 定义指标 metric5 记为 metric5 = true
- 定义三级指标
- metric5 = true || metric3 < 1 定义指标 metric6 记为 metric6 = true
- 定义四级指标
- metric6 = true && metric4 > 4, 定义指标metric7, 将计算出的指标记为result_metric, 并将表达式记为result_metric = true
分使用体验,可维护性,可拓展性三个维度阐述
- 使用体验: 用户也可以理解指标之间的血缘关系,下游报警出现问题能够更好的向上追溯定位问题。不必通过人工的方式比对.
- 可维护性: 在程序的角度看来,指标的依赖关系清晰明了,可以知道按什么顺序组织计算指标依赖
- 可拓展性: 后续如果要做指标归因,或者是基于指标的权重计算将可以在工作流当中,对每个指标单独定义
存在的问题以及改进
目前告警指标工作流第一版的做法是先考虑一级括号优先级的情况
例如:
arduino
代码解读
复制代码
(( oc\_key\_field("trxvbbb\_xxx\_yyyy", "rms", "highspeed") > 12 && oc\_key\_field("trxvbbb\_xxx\_yyyy", "rms", "lowspeed") = 8 )) || oc\_key\_field("trxvbbb\_xxx\_yyyy", "power", "gongkuang2") = 1
做四次语义切割
- 用自己写的token词法解析遇到&&或者||时,解析出一级括号所关联的表达式,操作符
- 逆波兰表达式(后缀数组转中缀数组)分别解析操作符左右两边的表达式,二次解析到本地缓存, 恢复常量,变量, 操作符
- 用KMP匹配每个工况表达式当中工况字段的位置, 从每个单表达式的工况最末尾字符出发,获取相关的阈值,
- 用双指针的方式组织单告警等级下工况表达式两两之间的依赖关系
暂时不支持多级括号优先级计算.
解析完后,根据各个告警等级,优先计算工况是否命中,然后用双重循环分别抽取数据字段以及对应的阈值,判断在绑定工况的数据字段情况下,该工况表达式是否符合<工况,数据字段>的两级命中策略。
再通过双指针组织得到的依赖关系,做各个原子级别工况表达式的组合计算。从而得到各个告警等级的最终计算结果
改进: 应用上述指标定义工作流的方式, 改善使用体验,可维护性,可拓展性三方面存在的问题.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









