




目录
概念及定义
哈希表,也成为散列表,在C++中unordered_set和unordered_map的底层实现依靠的都是哈希表。
map和set的底层是红黑树。unordered_set和unordered_map的底层是哈希表,unordered说明其数据的存储时没有顺序的。
哈希表是通过将插入数据的大小和位置建立联系,从而缩短查找数据的时间。
哈希表在进行数据的删除,查找,插入的时候不需要进行循环,其时间复杂度平均是O(1)。但是实际在使用的时候,其效率与红黑树差不多。
常见的哈希函数有:直接定值法,除留余数法,平方取中法....
此篇博客将会采用除留余数法进行哈希表的实现。
哈希表底层使用数组实现,除留余数法:将插入的整数模上数组大小得到的余数就是其对应的下标位置。
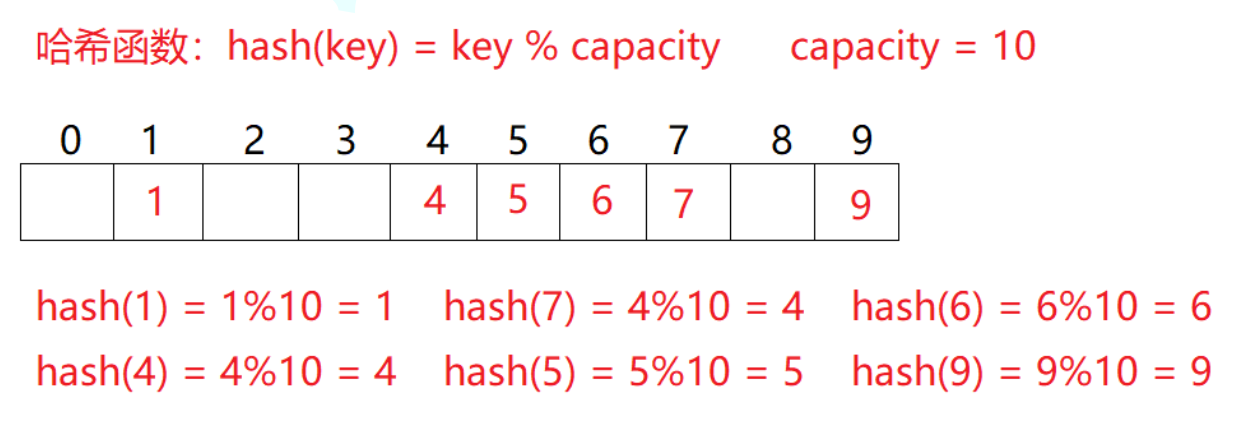
哈希冲突:对于哈希表来说必定会出现不同的数据映射到相同位置,值和位置就出现了多对一的关系,将这种现象称为哈希冲突。
解决哈希冲突的方法:1)闭散列(线性探测,二次探测);2)开散列(链地址法);3)多次散列。
此篇文章将对闭散列的实现方式进行分析。
闭散列的介绍
闭散列,也叫开放定值法,当出现哈希冲突的时候,即需要插入数据的位置被占用时,按规则去找下一个空位置,即去占别人的位置。
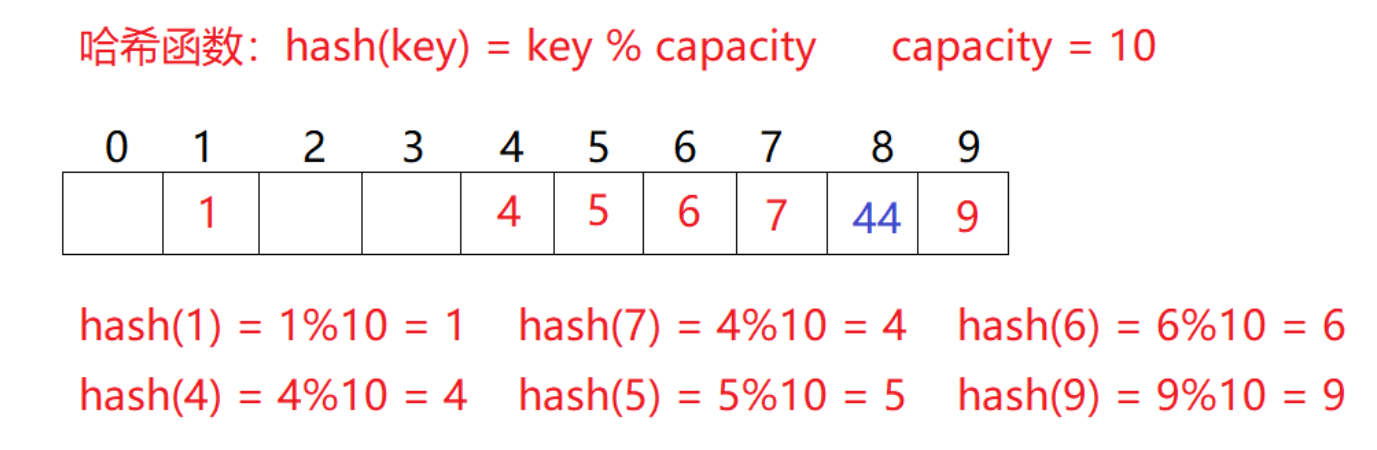
可以看到插入44的时候,下标为4的位置已经被占的,所以先后找空位置进行插入。
闭散列底层实现
依据除留余数法来确定数据的地址,再用开放定址法解决哈希冲突。
通过除留余数法得出数据对应的插入位置,如果该位置已经被占用,则先后找,直到找到空位置后停止。同理在查找数据是否存在的时候,也是先找到对应位置,如果不是再向后查找,直到找到或到空位置停止。
思考:在查找数据时,如果一个数据被删除,则该位置是空,那还继续向后查找吗???
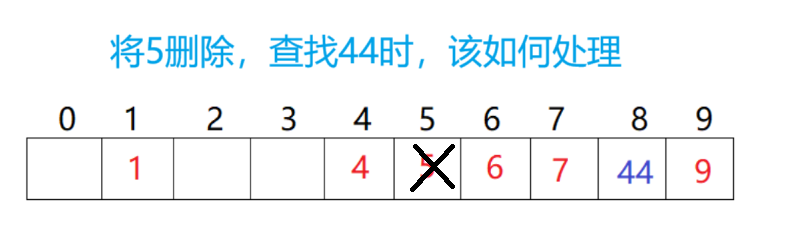
如图,当将5删除后,查找44时,到5位置为空就停止了,不再继续往后走了。这是不符合预期的,所以对每个数据要有三个状态:存在数据,不存在数据,数据被删除。
哈希表的定义
哈希表底层的数组,此处直接使用vector来代替。
enum STATE
{
EXIST, //存在数据
DELETE, //数据被删除
EMPTY //不存在数据
};
template<class K,class V>
struct HashDate
{
pair<K, V> _kv; //存放数据
STATE _state; //存储状态
};
template<class K, class V>
class HashTable
{
typedef HashDate<K, V> HashDate;
private:
vector<HashDate> _table;
size_t _n; //存储数组中有效个数
};哈希表的构造
使用vector的resize函数为vector开初始空间;实现HashDate的构造,在每次插入新数据的时候,其HashDate的状态都是EXIST存在。
template<class K,class V>
struct HashDate
{
//默认构造函数
HashDate()
:_state(EMPTY)
{ }
HashDate(const pair<K,V>& kv) //构造函数
:_kv(kv)
,_state(EXIST)
{ }
}
template<class K, class V>
class HashTable
{
typedef HashDate<K, V> HashDate;
public:
HashTable()
{
_table.resize(10); //vector初始有10个数组空间
_n = 0;
}
}哈希表扩容
当对哈希表插入数据,发生哈希冲突时,要向后找空位置进行插入。所以如果数组空间比较满就会出现一直向后找空位置的现象,这也导致插入效率降低。
所以哈希表不能太满,太满会导致查找和插入的效率降低。当哈希表满时,需要对哈希表进行及时扩容。
哈希表中引入载荷因子来控制哈希表是否扩容。
载荷因子 = 填入数据/哈希表的长度。
对于开放开放定址法:载荷因子需要控制在0.7~0.8左右。此处在代码实现时,我们会严格控制在0.7以下。
当对哈希表进行扩容时,也就意味着数据的映射位置会发生改变。原本冲突的数据可能扩容后不再冲突,原本不冲突的数据扩容后可能会出现冲突。所以在每次扩容时,需要对数据进行重新插入。
//对哈希表进行扩容
void More()
{
//此处需要强转为double类型,否则无法得到小数
if ((double)_n / _table.size() >= 0.7)
{
//进行扩容
//采用创建新的哈希表的方法
HashTable newtable;
newtable._table.resize(_table.size() * 2); //扩容时,直接扩为原数据的2倍
//将数据进行插入
for(auto e:_table)
{
newtable.Insert(e);
}
//将两个数组进行交换
_table.swap(newtable._table);
}
}哈希表插入
bool Insert(const pair<K, V> kv)
{
//判断是否需要扩容
More();
size_t hashi = kv.first % _table.size();
while (_table[hashi]._state == EXIST)
{
if (_table[hashi]._kv.first == kv.first)
{
//哈希表中已经存在,不能再插入
return false;
}
++hashi;
hashi = hashi % _table.size();
}
//找到空位置,进行插入
_table[hashi] = kv;
_n++;
return true;
}哈希表删除
哈希表的删除:在找到数据后,世界将该数据的状态改变即可,将EXIST改为DELETE。
//删除
bool Erase(const K& key)
{
size_t hashi = key % _table.size();
while (_table[hashi] == EXIST)
{
if (_table[hashi]._kv.first == key)
{
//找到了,将该位置进行删除,直接改变状态即可
_table[hashi]._state = DELETE;
return true;
}
++hashi;
hashi = hashi % _table.size();
}
//没找到
return false;
}哈希表查找
根据开头分析:哈希表的查找,在遇到DELETE和EXIST状态的数据时,均不停止,在遇到EMPTY状态的时候才会停止。
bool Find(const K& key)
{
size_t hashi = key % _table.size();
while (_table[hashi]._state != EMPTY)
{
if (_table[hashi]._kv.first == key && _table[hashi]._state == EXIST)
{
return true;
}
++hashi;
hashi = hashi % _table.size();
}
//没找到
return false;
}到此哈希表的基本功能已经实现,但是会发现:但是存储string类型的时候,string是不能取模的,关于该问题将会在后面《哈希表的封装》中进行详细分析。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











