




一、基本逻辑
1.看源码前须知
Node<K,V>[ ] table 哈希表结构中数组的名字
DEFAULT_INITIAL_CAPACITY: 数组默认长度16
DEFAULT_LOAD_FACTOR: 默认加载因子0.75
HashMap里面每一个对象包含以下内容:
1.1 链表中的键值对对象
包含:
int hash; //键的哈希值
final K key; //键
V value; //值
Node<K,V> next; //下一个节点的地址值
1.2 红黑树中的键值对对象
包含:
int hash; //键的哈希值
final K key; //键
V value; //值
TreeNode<K,V> parent; //父节点的地址值
TreeNode<K,V> left; //左子节点的地址值
TreeNode<K,V> right; //右子节点的地址值
boolean red; //节点的颜色
2.添加元素
HashMap<String,Integer> hm = new HashMap<>();
hm.put("aaa" , 111);
hm.put("bbb" , 222);
hm.put("ccc" , 333);
hm.put("ddd" , 444);
hm.put("eee" , 555);
添加元素的时候至少考虑三种情况:
2.1数组位置为null
2.2数组位置不为null,键不重复,挂在下面形成链表或者红黑树
2.3数组位置不为null,键重复,元素覆盖
参数一:键
参数二:值
//返回值:被覆盖元素的值,如果没有覆盖,返回null
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//利用键计算出对应的哈希值,再把哈希值进行一些额外的处理
//简单理解:返回值就是返回键的哈希值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
putVal
//参数一:键的哈希值
//参数二:键
//参数三:值
//参数四:如果键重复了是否保留
// true,表示老元素的值保留,不会覆盖
// false,表示老元素的值不保留,会进行覆盖
整体代码和分析思路如下:
//参数一:键
//参数二:值
//返回值:被覆盖元素的值,如果没有覆盖,返回null
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//利用键计算出对应的哈希值,再把哈希值进行一些额外的处理
//简单理解:返回值就是返回键的哈希值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//参数一:键的哈希值
//参数二:键
//参数三:值
//参数四:如果键重复了是否保留
// true,表示老元素的值保留,不会覆盖
// false,表示老元素的值不保留,会进行覆盖
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
//定义一个局部变量,用来记录哈希表中数组的地址值。
Node<K,V>[] tab;
//临时的第三方变量,用来记录键值对对象的地址值
Node<K,V> p;
//表示当前数组的长度
int n;
//表示索引
int i;
//把哈希表中数组的地址值,赋值给局部变量tab
tab = table;
if (tab == null || (n = tab.length) == 0){
//1.如果当前是第一次添加数据,底层会创建一个默认长度为16,加载因子为0.75的数组
//2.如果不是第一次添加数据,会看数组中的元素是否达到了扩容的条件
//如果没有达到扩容条件,底层不会做任何操作
//如果达到了扩容条件,底层会把数组扩容为原先的两倍,并把数据全部转移到新的哈希表中
tab = resize();
//表示把当前数组的长度赋值给n
n = tab.length;
}
//拿着数组的长度跟键的哈希值进行计算,计算出当前键值对对象,在数组中应存入的位置
i = (n - 1) & hash;//index
//获取数组中对应元素的数据
p = tab[i];
if (p == null){
//底层会创建一个键值对对象,直接放到数组当中
tab[i] = newNode(hash, key, value, null);
}else {
Node<K,V> e;
K k;
//等号的左边:数组中键值对的哈希值
//等号的右边:当前要添加键值对的哈希值
//如果键不一样,此时返回false
//如果键一样,返回true
boolean b1 = p.hash == hash;
if (b1 && ((k = p.key) == key || (key != null && key.equals(k)))){
e = p;
} else if (p instanceof TreeNode){
//判断数组中获取出来的键值对是不是红黑树中的节点
//如果是,则调用方法putTreeVal,把当前的节点按照红黑树的规则添加到树当中。
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
//如果从数组中获取出来的键值对不是红黑树中的节点
//表示此时下面挂的是链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//此时就会创建一个新的节点,挂在下面形成链表
p.next = newNode(hash, key, value, null);
//判断当前链表长度是否超过8,如果超过8,就会调用方法treeifyBin
//treeifyBin方法的底层还会继续判断
//判断数组的长度是否大于等于64
//如果同时满足这两个条件,就会把这个链表转成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
//e: 0x0044 ddd 444
//要添加的元素: 0x0055 ddd 555
//如果哈希值一样,就会调用equals方法比较内部的属性值是否相同
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){
break;
}
p = e;
}
}
//如果e为null,表示当前不需要覆盖任何元素
//如果e不为null,表示当前的键是一样的,值会被覆盖
//e:0x0044 ddd 555
//要添加的元素: 0x0055 ddd 555
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null){
//等号的右边:当前要添加的值
//等号的左边:0x0044的值
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
//threshold:记录的就是数组的长度 * 0.75,哈希表的扩容时机 16 * 0.75 = 12
if (++size > threshold){
resize();
}
//表示当前没有覆盖任何元素,返回null
return null;
}
二、底层代码分析
1.定义一个局部变量,用来记录哈希表中数组的地址值。 Node<K,V>[ ] tab;
(局部变量记录数组的地址值,便于每次操作不用每次都去堆里找,成员变量在堆里)
2.临时的第三方变量,用来记录键值对对象的地址值 Node<K,V> p;
3.表示当前数组的长度 int n;
4.表示索引 int i;
5.把哈希表中数组的地址值,赋值给局部变量tab tab = table;
2.1数组位置为null
一、(1)如果当前是第一次添加数据,tab == null
去执行resize()
底层会创建一个默认长度为16(DEFAULT INITIAL CAPACITY),
加载因子为0.75(DEFAULT LOAD FACTOR)的数组
(2)如果没有达到扩容条件,底层不会做任何操作
如果达到了扩容条件,底层会把数组扩容为原先的两倍,并把数据全部转移到新的哈希表中
(3)表示把当前数组的长度赋值给n=16 n = tab.length;
if (tab == null || (n = tab.length) == 0){
tab = resize();
n = tab.length;
}
二、
1.拿着数组的长度跟键的哈希值进行计算,计算出当前键值对对象,在数组中应存入的位置
i = (n - 1) & hash;//index
//获取数组中对应元素的数据 p = tab[i];
2.newNode就是创建了键值对对象(一个节点),直接放到数组当中
3.threshold:记录的就是数组的长度 * 0.75,哈希表的扩容时机 16 * 0.75 = 12
添加了之后,size先加加,再比较扩容时机,判断是否需要扩容(即resize()方法)
4.返回null(没有被覆盖的值则返回null)
i = (n - 1) & hash;
p = tab[i];
if (p == null){
//底层会创建一个键值对对象,直接放到数组当中
tab[i] = newNode(hash, key, value, null);
}else {....}
if (++size > threshold){
resize();
}
//表示当前没有覆盖任何元素,返回null
return null;
}
2.2数组位置不为null,键不重复,挂在下面形成链表或者红黑树
先拿着键去计算哈希值,找到应存入的位置
1.putVal
2.tab != null n = tab.length
if (tab == null || (n = tab.length) == 0){
tab = resize();
n = tab.length;
}
1. i = (n - 1) & hash;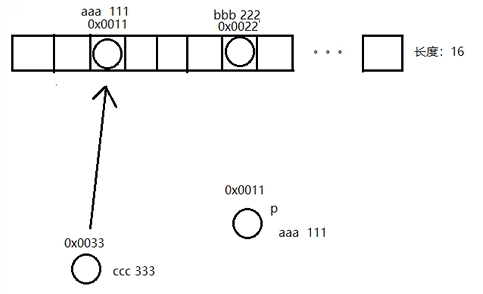
2. p = tab[i];
(记录了原先位置上的人p的地址值) 0x0011
3. boolean b1 = (p.hash == hash);
判断要添加的键值对的哈希值是否相同,键不重复所以b1这里是flase
4. p instanceof TreeNode判断是不是红黑树中的结点
①是 创建红黑树
②不是,按照链表
看原本的位置后面是不是空的,空的就会创建一个结点挂在他的下面
还会判断长度是否超过8,进一步判断是否超过64
if (binCount >= TREEIFY_THRESHOLD - 1)
如果同时满足这两个条件,就会把这个链表转成红黑树
5.e是null(e = p.next)
if (e != null) {....这里是覆盖的代码实现} return null;
数组位置不为null,键不重复,挂在下面形成链表或者红黑树:
if (p == null){....}
else {
Node<K,V> e;
K k;
boolean b1 = (p.hash == hash);
if (b1 && ((k = p.key) == key || (key != null && key.equals(k)))) {.....}
else if (p instanceof TreeNode){
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){
break;
}p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null){
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
if (++size > threshold){
resize();
}
return null;
}
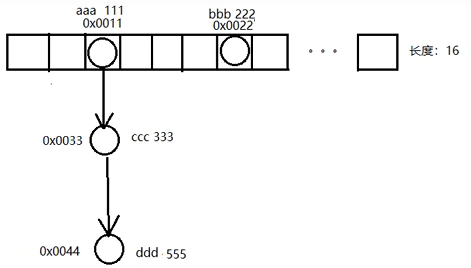
2.3数组位置不为null,键重复,元素覆盖
1.putVal
2.p记录0x0011
p.hash == hash还是不一样
e = p.next一直往下面找p = e
e: 0x0044 ddd 444
要添加的元素: 0x0055 ddd 555
直到哈希值一样为止,再比较内部属性值是否一样,一样就break;
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){
break;
}
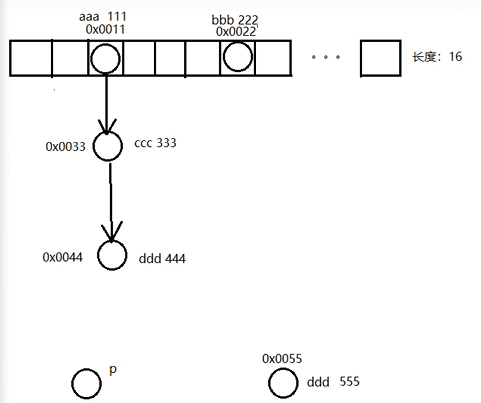
开始走覆盖的代码,这里e是0x0044
onlyIfAbsent true保留重复元素 false 覆盖(本文是false)
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null){
e.value = value; (把要添加的值覆盖给老的)
}
afterNodeAccess(e);
return oldValue;
}
添加前 添加后
数组位置不为null,键重复,元素覆盖的代码:
i = (n - 1) & hash;
p = tab[i];
if (p == null){
tab[i] = newNode(hash, key, value, null);
}else {
Node<K,V> e;
K k;
boolean b1 = p.hash == hash;
if (b1 && ((k = p.key) == key || (key != null && key.equals(k)))){
e = p;
} else if (p instanceof TreeNode){
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){
break;
}p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null){
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
if (++size > threshold){
resize();
}
return null;
}
以上就是全部的HashMap的底层源码分析了,十分详细理解,不懂的可以收藏起来多看两遍,建议搭配着代码来逐一理解。
三、下期预告
下期带来TreeMap的源码分析!

















 1921
1921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









