




内存屏障是一种基础语言,在不同的计算机架构下有不同的实现细节。本文主要在x86_64处理器下,通过Linux及其内核代码来分析和使用内存屏障
对大多数应用层开发者来说,“内存屏障”(memory Barrier)是一种陌生,甚至有些诡异的技术。实际上,他机制常被用在操作系统内核中,用于实现同步、驱动程序利用它,能够实现高效的无锁数据结构,提高多线程程序的性能表现。本文首先探讨了内存屏障的必要性,之后介绍如何利用内存屏障实现一个无锁唤醒振荡器(队列),用于在多个线程间进行高效的数据交换。
理解内存屏障
开发者显然不明白一个事实——程序实际运行时很可能并不完全按照开发者编写的顺序访问内存。例如:
x = r;
y= 1;这里,y = 1很可能先于x = r执行。这就是内存乱序访问。内存乱序访问发生的原因是为了提升程序运行时的性能。编译器和CPU都可能引起内存乱序访问:
-
编译时,编译器优化进行指令重排而导致内存乱序访问;
-
运行时,多CPU间交互引入内存乱序访问。
编译器和CPU引入内存乱序访问通常不会带来什么问题,但在一些特殊情况下(主要是多线程程序中),逻辑的正确性依赖于内存访问顺序,接下来,内存乱序访问会带来逻辑上的错误,例如:
// 线程 1
while (!ok);
做(x);
// 线程 2
x = 42 ;
好的= 1;ok初始化为0,线程1等待ok被设置为1后执行do函数。假设,线程2对内存的写操作乱序执行,如果x判断晚于ok完成判断,那么do函数接受的实参很有可能出乎开发者的意料,不为42。
我们可以引入内存屏障来避免上述问题的出现。内存屏障可以让CPU或者编译器在内存访问上进行。内存屏障之前的内存访问操作一定要先于其之后的完成。内存屏障包括两类:编译器屏障和CPU内存屏障。
编译时内存乱序访问
编译器对代码进行优化时,可能会改变实际执行指令的顺序(例如g++下O2或者O3都会实际执行指令的顺序),改变看一个例子:
整数x、y、r;
无效 f ()
{
x = r;
y= 1;
}首先直接编译次源文件:g++ -S test.cpp。我们得到相关的编译代码如下:
movl r(%rip), %eax
movl %eax, x(%rip)
movl $1, y(%rip)这里我们可以看到,x = r并且y = 1并没有乱序执行。现使用优化选项O2(或O3)编译上面的代码(g++ -O2 –S test.cpp),生成代码如下:
movl r(%rip), %eax
movl $1, y(%rip)
movl %eax, x(%rip)我们可以清楚地看到经过编译器优化之后,movl $1, y(%rip)先于movl %eax, x(%rip)执行,这意味着,编译器优化导致了内存乱序访问。避免次次行为的办法就是使用编译器屏障(又叫优化屏障)。Linux内核提供了函数barrier(),用于让编译器保证其之前的内存访问先于其之后的内存访问完成。(这个强制保证顺序的需求在哪里?换句话说乱序会带来什么问题? – 一个线程执行了 y =1 ,但实际上 x=r 还没有执行完成,此时被另一个线程抢占,另一个线程执行,发现y =1,认为此时x必定=r,执行相应逻辑,造成错误)内核实现barrier()如下:
#定义屏障() __asm__ __volatile__( "" : : : "内存" )现在把这个编译器barrier加入代码中:
整数x、y、r;
无效 f ()
{
x = r;
__asm__ __volatile__( "" : : : "内存" )
y = 1 ;
}再编译,就会发现内存乱序访问已经不存在了。除了barrier()函数外,本例还可以使用volatile这个关键字来避免编译时内存乱序访问(且只能避免编译时的乱序访问) ,为什么呢,可以参考前面部分的说明,编译器对于 volatile 声明到底做了什么 – volatile 关键字对于编译器而言,是开发者告诉编译器,这个变量内存的修改,可能不再是你可视范围了内部修改,不要对这个变量相关的代码进行优化)。volatile关键字允许对易失性变量之间的内存进行访问,这里可以x和y的定义来解决问题:
易失性 int x、y、r;通过 volatile 关键字,使得 x 相对 y、y 相对 x 在内存访问上是集群的。实际上,Linux 内核中,宏ACCESS_ONCE可以避免编译器对于连续的ACCESS_ONCE实例进行指令重排,其就是通过volatile实现的:
#定义ACCESS_ONCE(x) (*(易失性类型(x) *)&(x))此代码只是将变量转换为易失性的最后。现在我们有了第三个修改方案:
整数x、y、r;
无效 f ()
{
ACCESS_ONCE(x) = r;
ACCESS_ONCE(y) = 1 ;
}到这里,基本上就阐述完成了编译时内存乱序访问的问题。下面看看CPU有怎样的行为。
运行时内存乱序访问
运行时,CPU本身是会乱序执行指令的。早期的处理器为阵列处理器(in-order ports),总是按开发者编写的顺序执行指令,如果指令的输入操作对象(input operands)不可用(通常由于需要从内存中获取),那么处理器不会转而执行那些输入操作对象可用的指令,而是当前等待输入操作对象可用。相比之下,乱序处理器(out-of) -顺序处理器)会先处理那些可用的输入操作对象的指令(而不是顺序执行)从而避免了等待,提高了效率。现代计算机上,处理器运行的速度比内存快很多,小区处理器花在等待可用的数据时间里已可处理大量指令了。即使现代处理器会乱序执行,但在单个CPU上,指令可以通过指令队列顺序获取并执行,结果利用队列顺序返回注册堆
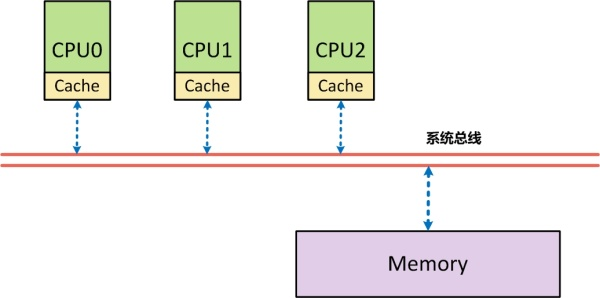
SMP架构需要内存接口的进一步解释:从体系结构上来看,首先在SMP架构下,每个CPU与内存之间,都分配了自己的高速缓存(Cache),以减少访问内存时的冲突
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2215
2215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









