




目录
进一步思考: 如果给出结构体的指针,怎么访问这些成员变量呢?
1.知识回顾
2.僵尸进程
首先明确:一个进程退出时,它的资源不会立刻被操作系统释放
僵尸进程(又称僵死进程): 操作系统需要暂时维持该进程的信息等待父进程的回收(可以形象理解为“收尸”),那么处于此状态下的死亡的子进程称为僵尸进程,Linux上标识为Z状态(Zombie)
-->子进程比父进程先死亡,该子进程为僵尸进程
使用exit函数来产生僵尸进程
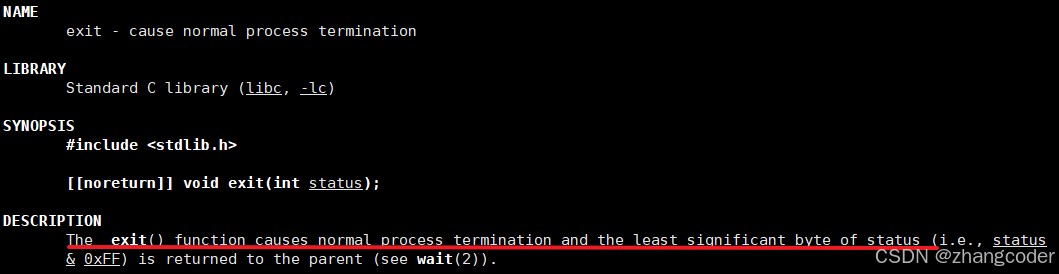
exit函数可以让进程正常退出,需要包含stdlib.h头文件
进一步解释:一般情况下,进程调用exit时,它的绝大多数内存和相关的资源已经被内核释放掉,但在进程表这个进程项中还保留着,等待父进程获取它的退出状态
例如以下代码:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t ret_id = fork();
if (ret_id == 0)
{//子进程
int cnt = 5;
while (cnt--)
{
printf("the child process is running... PPID:%d,PID:%d,cnt:%d\n", getppid(), getpid(), cnt);
sleep(1);
}
exit(0);
}
else
{//父进程,不让其读取子进程的信息
while (1)
{
printf("the parent process is running... PPID:%d,PID:%d\n", getppid(), getpid());
sleep(1);
}
}
return 0;
}注: 父进程没有调用wait或waitpid获取子进程的状态信息
运行结果:
显然子进程比父进程先死亡,看看子进程的状态:
ps ajx | head -1 && ps ajx | grep "a.out"
从PPID和PID来看:

从处于僵尸状态的子进程来看,其处于Z状态,而且有标注defunct n.失效的

僵尸进程无法使用kill命令杀死
僵尸进程是已经退出运行的进程,无法被kill命令杀死
僵尸进程的危害
本身子进程死亡是处于僵尸状态是正常的,因为会有父进程来获取信息,之后子进程处于X状态
但如果操作系统中有大量僵尸进程持续存在,尤其是进程的PCB无法释放,需要一直维护,占用内存资源,导致内存泄漏(如何避免后面会讲),而且操作系统容易负载甚至有崩溃的风险
注意:内存泄漏不一定是没有free()或者delete导致的,还有可能是僵尸进程未被父进程回收
例如该文章提到的:randomascii zombie-processes-are-eating-your-memory

详细解释也可以参见linux后台开发中避免僵尸进程的方法总结文章
3.孤儿进程
孤儿进程: 如果父进程比子进程先死亡,处于此状态的下的子进程被称为孤儿进程
修改上方代码,使得父进程先退出:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t ret_id = fork();
if (ret_id == 0)
{//子进程
while (1)
{
printf("the child process is running... PPID:%d,PID:%d\n", getppid(), getpid());
sleep(1);
}
}
else
{//父进程
int cnt = 5;
while (cnt--)
{
printf("the parent process is running... PPID:%d,PID:%d,cnt:%d\n", getppid(), getpid(), cnt);
sleep(1);
}
exit(0);
}
return 0;
}运行结果:
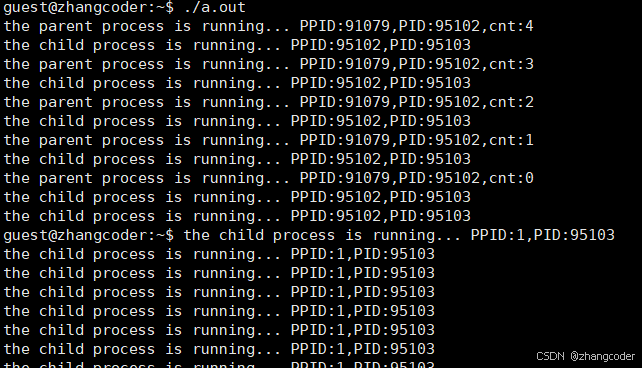
一开始两个进程正常运行:

父进程死亡后:

会发现子进程的PPID=1,下面查找PID=1 的进程:
ps ajx1号进程为system,是操作系统本身,也被称为init进程,负责系统的初始化和进程管理

结论
1.父进程比子进程先死亡,子进程为孤儿进程,孤儿进程会被1号进程(新的父进程init)领养,父进程需要对子进程负责
2.领养的原因:因为孤儿进程未来也会退出,也要被释放
3.孤儿进程运行在系统后台(孤儿进程的产生一般都会带有目的性,比如需要一个程序运行在后台或者不想一个进程退出后成为僵尸进程之类的需要)
4.特殊的孤儿进程: 守护进程和精灵进程
这两种是同一种进程的不同翻译,是特殊的孤儿进程,父进程是1号进程.
守护进程和精灵进程不但运行在后台,最主要的是脱离了与终端和登录会话的所有联系,也就是默默的运行在后台不想受到任何影响
5.进程优先级
前置知识
1.一个父进程可以有多个子进程
2.进程可以用多种数据结构来维护:可以是在树中的节点,也可以是在双向链表中的节点-->一个进程既可以属于多叉树,也可以属于双向链表
例如在双向链表中的进程:
Linux内核有双向链表的源代码,头文件位于/include/linux/list.h中,在线查看:https://github.com/torvalds/linux/blob/master/include/linux/list.h
调试文件位于lib/list_debug.c中,在线查看:https://github.com/torvalds/linux/blob/master/lib/list_debug.c
linux内核获取PCB中所有属性的原理
对于一个多进程的操作系统而言,运行队列的所有进程的PCB都是串在一起的,可以通过指针来遍历PCB
而对于linux,PCB是task_struct,其简化版为:
struct task_struct
{
//......(省略属性的详细内容)
struct task_struct* next;
};假设task_struct有这样一些属性(不全,也不规范):
struct task_struct
{
char* process_state;
struct task_struct* next;
int Process_ID;
struct cpu* ptr_cpu;
char* memory_management;
};如何获取成员变量的偏移量?
查看结构体各个成员变量的偏移量可以用VS的内存布局:
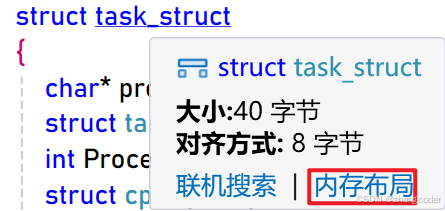
x86:

思路:如果task_struct结构体存储在地址为0的地方(实际上不可能,下面只是利用这个特性获取偏移量),那么成员变量的地址就等于成员变量在结构体在的偏移量
即0号地址存不存在task_struct是不重要的,重要的是取得每个成员变量的偏移
如果直接使用printf打印成员变量会发生段错误:
printf("next's disp==%d", ((struct task_struct*)(NULL))->next);运行结果:虽然报错,但VS给出的是正确的偏移量 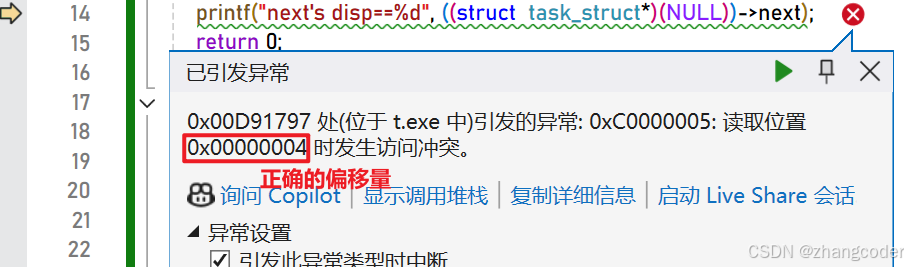
解决方法:->访问成员变量,如果再前面加一个&,就能打印出成员变量的地址而并没有访问成员变量
(->是访问,而&只要地址)
printf("next's disp==%d", &(((struct task_struct*)(NULL))->next));运行结果:给出的偏移量是正确的
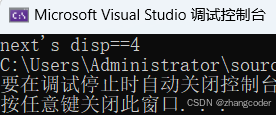
打印所有成员变量的偏移:
int main()
{
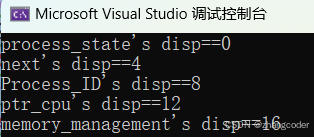
printf("process_state's disp==%d\n", &(((struct task_struct*)(NULL))->process_state));
printf("next's disp==%d\n", &(((struct task_struct*)(NULL))->next));
printf("Process_ID's disp==%d\n", &(((struct task_struct*)(NULL))->Process_ID));
printf("ptr_cpu's disp==%d\n", &(((struct task_struct*)(NULL))->ptr_cpu));
printf("memory_management's disp==%d\n", &(((struct task_struct*)(NULL))->memory_management));
return 0;
}运行结果:
进一步思考: 如果给出结构体的指针,怎么访问这些成员变量呢?
要想访问结构体其他的成员变量,需要取得结构体地址
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
struct node
{
struct node* prev;
struct node* next;
};
struct task_struct
{
char* process_state;
struct node* link;//用于串联task_struct
int Process_ID;
struct cpu* ptr_cpu;
char* memory_management;
};
int main()
{
struct task_struct* s_ptr = (struct task_struct*)malloc(sizeof(struct task_struct));//假设s_ptr无法直接取得
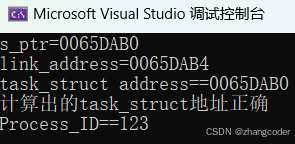
printf("s_ptr=%p\n", s_ptr);
s_ptr->Process_ID = 123;
//假设只知道link的地址link_address,任务是访问task_struct结构体的其他成员变量,例如Process_ID
struct task_struct* link_address = (struct task_struct*) & (s_ptr->link);
//取得task_struct的地址
int link_disp = (int) & (((struct task_struct*)(NULL))->link);
printf("link_address=%p\n", link_address);
struct task_struct* task_struct_address = (struct task_struct*)((unsigned int)link_address - link_disp);//一定要视为纯数字相减,否则+1意味着跳过一个结构体
printf("task_struct address==%p\n", task_struct_address);
if (task_struct_address == s_ptr)
printf("计算出的task_struct地址正确\n");
else
printf("计算出的task_struct地址错误\n");
//借助task_struct_address访问Process_ID
printf("Process_ID==%d\n", task_struct_address->Process_ID);
return 0;
}运行结果:
结论
只需要结构体某个成员变量的地址就能访问该结构体其他的成员变量,因为结构体的每个成员变量的偏移量都能算出来
进程优先级
为什么有优先级?
CPU的资源是有限的,而多任务的操作系统是有多个进程的,那么进程相互之间必定会竞争CPU的资源,那就需要优先级来控制哪个进程先访问资源,哪个进程后访问资源,确保进程之间是良性竞争的
如果进程长时间得不到CPU资源,那么该进程的代码长时间无法得到推进,产生该进程饥饿的问题,在用户层面上来看: 进程”卡”了
简单理解优先级:
1.控制进程对于资源的访问
2.给出让某个进程先访问,其他进程后访问的理由
3.分配CPU资源的先后顺序就是进程的优先级
4.如果是多核CPU,可以把重要进程运行到指定的核心上,把不重要的进程安排到其他核心,这样可以改善系统整体性能
注:非特殊情况不建议更改优先级,优先级是为了保证进程之间公平地调度
查看进程优先级的命令
1.ps
ps l或者ps al都可以

2.top
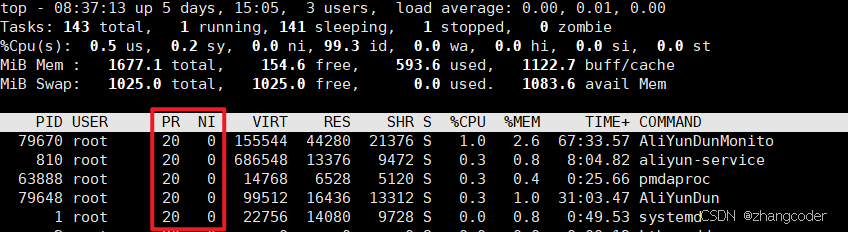
UID代表执行者的身份(User ID),PRI是priority的缩写,而NI是nice值的缩写,是进程优先级的修正数据
PRI和NI
1.PRI表示进程优先级,值越小,进程的优先级别越高,越早被执行
2.NI表示进程可被执行的优先级的修正数值nice,取值范围为[-20,19],一共40个级别
3.加入nice值后,将会使得PRI变为: PRI(new)=PRI(old)+nice,结论: 调整进程的优先级就是调整nice值,因此更改优先级只会修改NI,不会改PRI
特别强调:进程的nice值不是进程的优先级!
修改进程的NI值
可以修改进程的NI值来达到修改进程的优先级
1.nice命令
使用-n选项来为启动的程序设置初始的优先级,不是设置正在运行的进程!
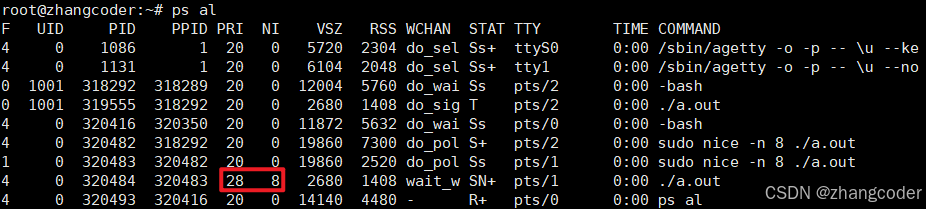
例如运行./a.out程序,其初始的NI值为8:
sudo nice -n 8 ./a.out #建议加上sudo,如果不加,可能NI值是改不掉的运行结果:
可知:PRI(old)=20,nice=8,则PRI(new)=PRI(old)+nice=28
2.renice命令
作用:修改正在运行的进程的优先级
可以使用-n修改
sudo renice -n 新的NI值 -p 进程的PID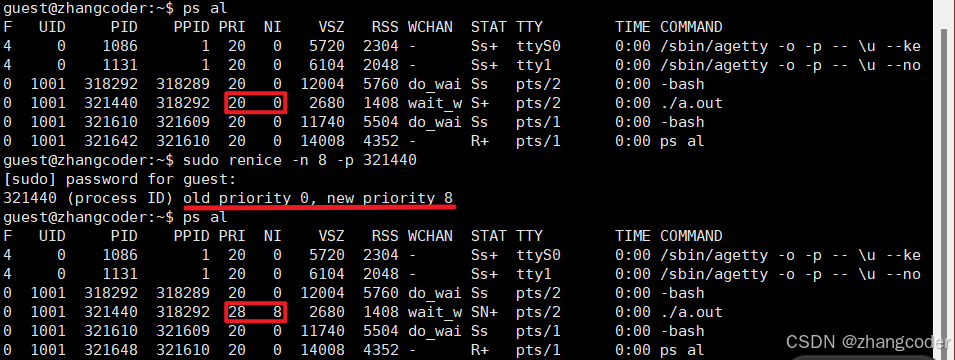
3.top命令
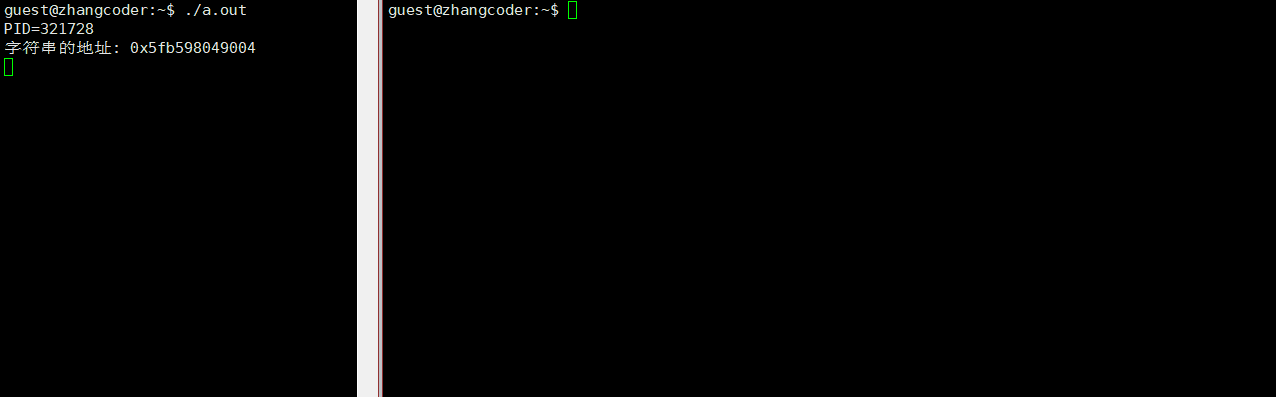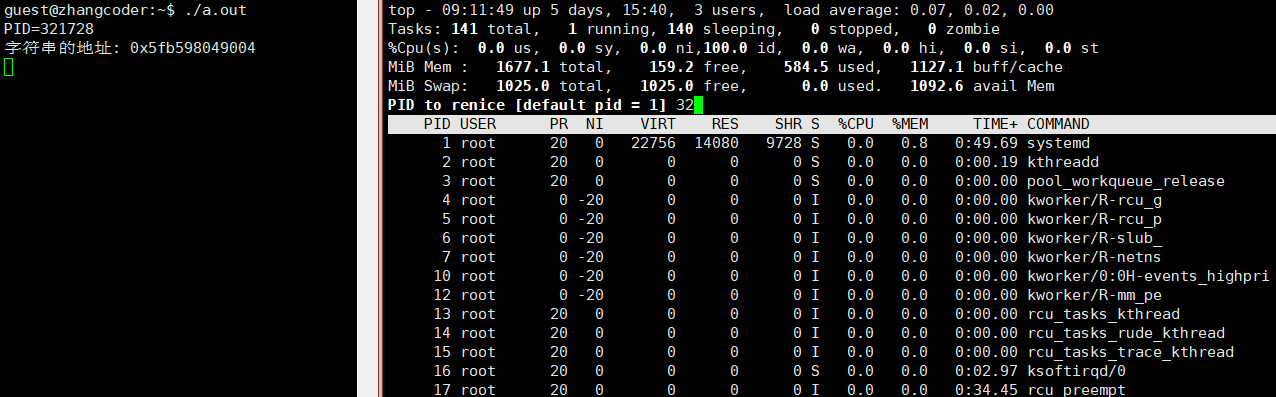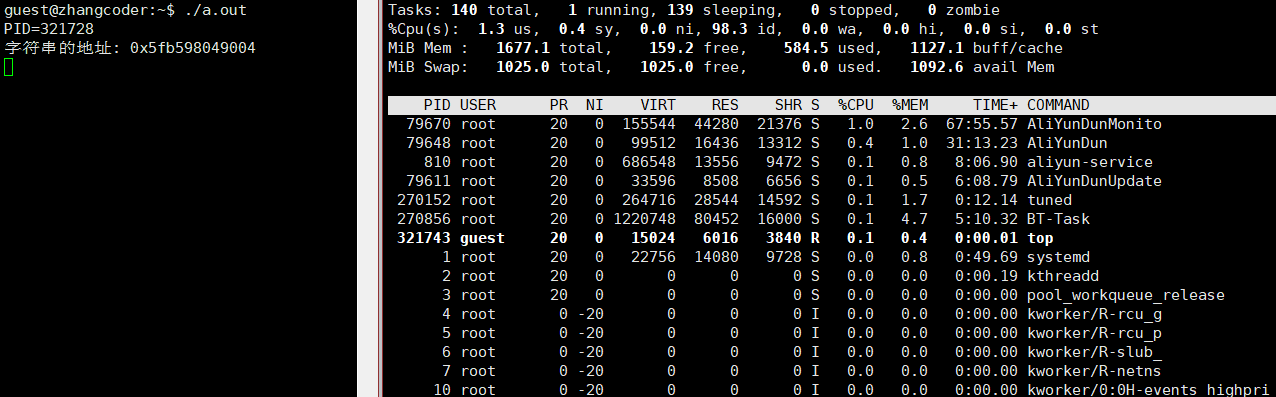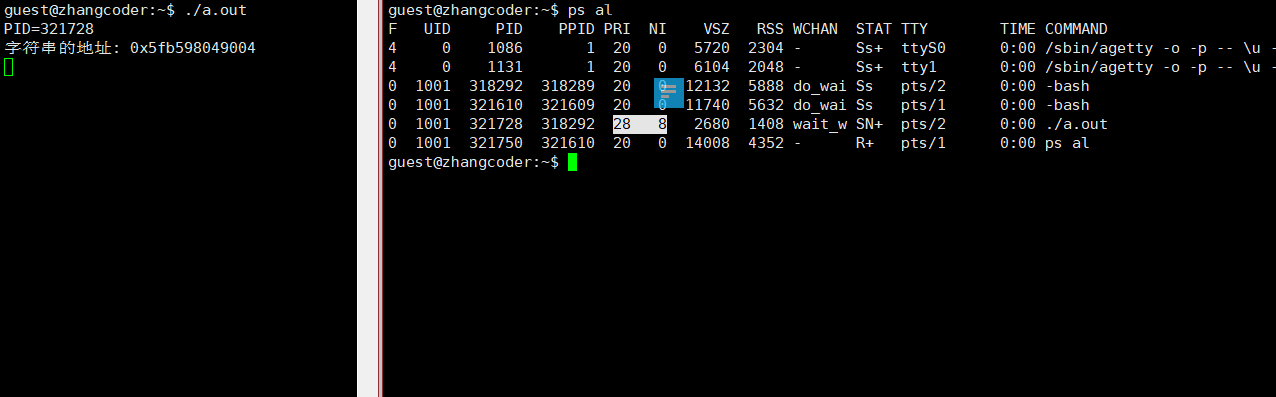
步骤:
1.打开 top
2.按下 r 键(代表 renice)
3.输入要调整的进程 PID
4.输入新的 nice 值
演示动图:
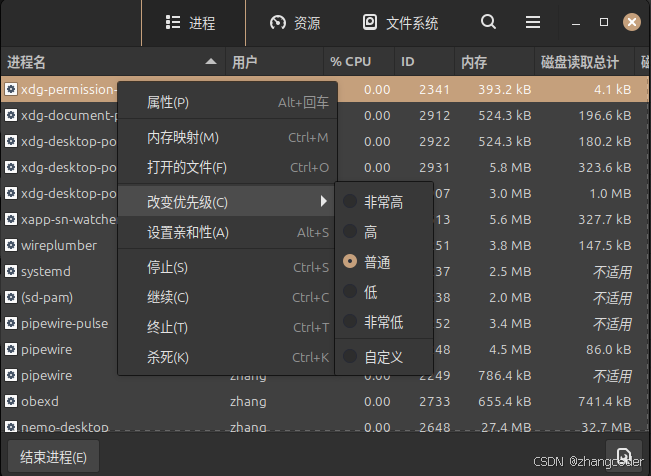
4.Linux桌面版进程优先级的设置
以Linux mint为例.在系统监视器中右击进程选择"改变优先级(C)"


















 2375
2375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











