




在当今快速发展的人工智能领域,大型语言模型(LLM)已经成为无处不在的技术,它们不仅改变了我们与机器交流的方式,还在各行各业中发挥着革命性的影响。
然而,尽管LLM + RAG的能力已经让人惊叹,但我们在使用RAG优化LLM的过程中,还是会遇到许多挑战和困难,包括但不限于检索器返回不准确或不相关的数据,并且基于错误或过时信息生成答案。因此本文旨在提出RAG常见的7大挑战,并附带各自相应的优化方案,期望能够帮助我们改善RAG。
下图展示了RAG系统的两个主要流程:检索和查询;红色方框代表可能会遇到的挑战点,主要有7项:
- Missing Content: 缺失內容
- Missed Top Ranked: 错误排序內容,导致正确答案沒有被成功 Retrieve
- Not in Context: 上限文限制,导致正确答案沒有被采用
- Wrong Format: 格式错误
- Incomplete: 回答不全面
- Not Extracted: 未能检索信息
- Incorrect Specificity: 不合适的详细回答
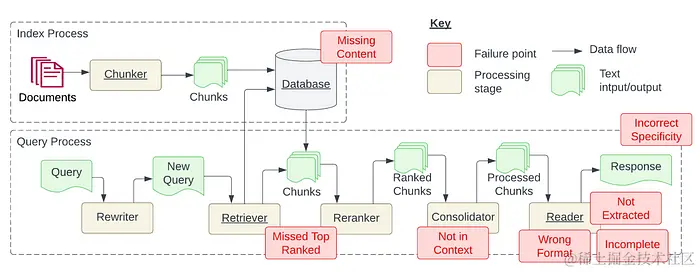
这些挑战不仅关系到系统的可用性和准确性,还直接影响到用户对技术的信任度。为了解决这些问题,以下是针对每个挑战的优化方案:
缺失内容(Missing Content)
当 RAG 系统面对的问题无法从现有文件中得到答案时,就会出现这种情况。在最佳情况下,我们希望 RAG 系统直接回答「我不知道」。然而,实际上RAG 系统常常会编造或错误回答问题。
针对这个问题,目前有两大解决策略:
1. 数据清理
俗话说"吃什么、吐什么"。原始数据质量对信息处理系统的准确性至关重要,若输入数据错误或矛盾,或者预处理步骤不当,则无论检索增强生成(RAG)系统有多先进,也无法从混乱数据中提取有价值信息。这意味着我们必须在数据源选择、数据清洗、预处理等环节投入资源和技术,以确保输入数据尽可能准确和一致。这个策略不仅适用于本文讨论的问题,也适用于所有数据处理流程中,数据质量始终是关键。
2. prompt 工程
在知识库缺乏相关信息、导致系统可能给出看似合理但实际上错误答案的情况下,使用提示工程是一个非常有帮助的解决方式。例如通过设定提示:“如果你对答案不确定,就直接告诉我你不知道”,如此可以鼓励模型采取更谨慎和诚实的回应态度,从而避免误导用户。虽然不能保证系统回答的绝对准确性,但通过这样的提示, 确实能提高回答品质。
未命中排名靠前的内容(Missed Top Ranked)
这个挑战主要在于“答案在文件中,但由于排名靠前而未能提供给用户”。理论上,检索系统会为每个文档分配一个排名,此排名将决定其在后续处理中的使用程度。然而,在实际操作中,受限于性能和资源,通常只有排名最高的前 K 个文档会被选取并展示给用户。这里的 K 是基于性能考虑的参数。
针对该问题,存在两种解决方式:
1. 调整参数以优化搜索效果
该部分提出了两个方面调整以增加 RAG 效率和准确性:chunk_size
如果要直接在 langchain 调整块大小,请使用以下代码:
python复制代码 from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100)
all_splits = text_splitter.split_documents(PDF_data)
k 值涉及到检索器应该返回多少个答案,我们可以选择返回更多的答案,以确保正确答案不会被 LLM 忽略:
python复制代码 retriever = vectordb.as_retriever(search_kwargs={
"k": 8})
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
2. 优化检索文档的排序
在将检索到的文件送到LLM前,先对文件进行最佳化排序,能大幅提升RAG系统的效能,因为初始排序无法反映件与查询的真实相关性。这系列的论文可以看Liu et al.2023,论文中指出,将最相似的文档放在开头或结尾时,效能通常最高,因为模型容易迷失在中间。
在langchain中,我们可以使用langchain原生的Long-Context Reorder或Cohere Reranker来实现,请参考官方文件。
2.1 Long-Context Reorder
python复制代码 retriever = vectordb.as_retriever(search_kwargs={
"k": 8})
query = "What can you tell me about the Celtics?"
# 按相关度分数排序获取相关文档
docs = retriever.get_relevant_documents(query)
# 重新排序文件:
# 列表中不太相关的文件将排在中间位置。开始/结尾处的相关要素。
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
# 确认前后共有4份相关文件。
print(reordered_docs)
2.2 Cohere Reranker
python复制代码 from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
from langchain_community.llms import Cohere
retriever = vectordb.as_retriever(search_kwargs={
"k": 8})
query = "What can you tell me about the Celtics?"
# 按相关性得分排序以获取相关文件
docs = retriever.get_relevant_documents
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









