



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
mount /dev/sda6 /abc
上面这个命令将/dev/sda6挂载到目录abc
目录结构
Linux 对文件系统中的目录进行了一定的归类
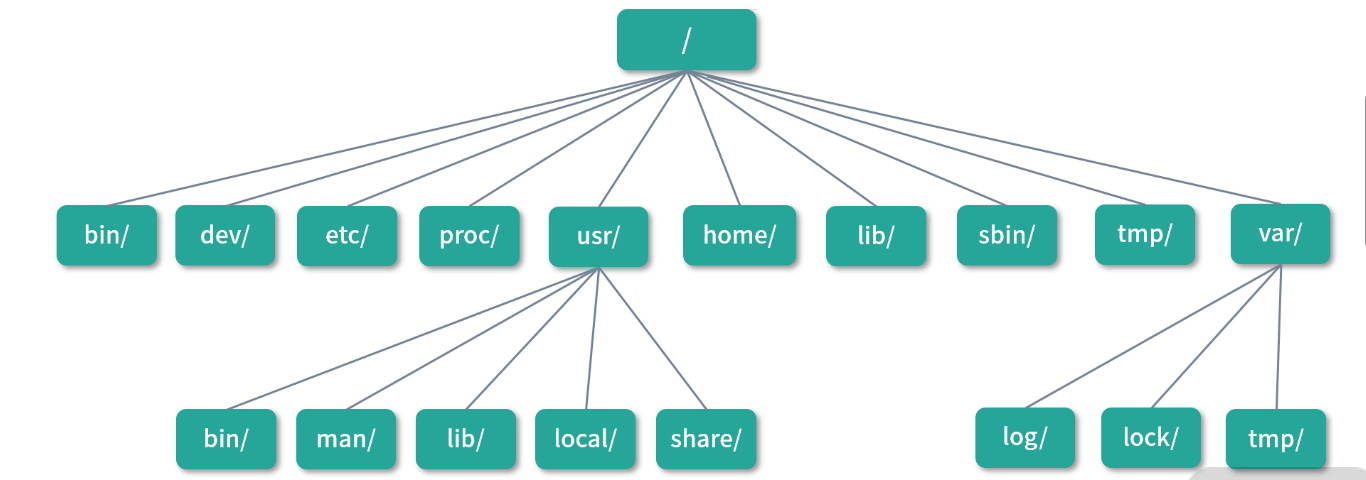
- 最顶层的目录称作根目录, 用
/表示。/目录下用户可以再创建目录,但是有一些目录随着系统创建就 已经存在,接下来我会和你一起讨论下它们的用途。 - **/bin(二进制)**包含了许多所有用户都可以访问的可执行文件,如 ls, cp, cd 等。这里的大多数程序都是 二进制格式的,因此称作bin目录。bin是一个命名习惯,比如说nginx中的可执行文件会在 Nginx 安 装目录的 bin 文件夹下面。
- /dev(设备文件) 通常挂载在devtmpfs文件系统上,里面存放的是设备文件节点。通常直接和内存进 行映射,而不是存在物理磁盘上。值得一提的是其中有几个有趣的文件,它们是虚拟设备。
/dev/null是可以用来销毁任何输出的虚拟设备。你可以用>重定向符号将任何输出流重定向 到/dev/null来忽略输出的结果。/dev/zero是一个产生数字 0 的虚拟设备。无论你对它进行多少次读取,都会读到 0。/dev/ramdom是一个产生随机数的虚拟设备。读取这个文件中数据,你会得到一个随机数。你不停地 读取这个文件,就会得到一个随机数的序列。- /etc(配置文件),/etc名字的含义是and so on……,也就是“等等及其他”,Linux 用它来保管程序的 配置。比如说mysql通常会在/etc/mysql下创建配置。再比如说/etc/passwd是系统的用户配置,存 储了用户信息。
- /proc(进程和内核文件) 存储了执行中进程和内核的信息。比如你可以通过/proc/1122目录找到和 进程1122关联的全部信息。还可以在/proc/cpuinfo下找到和 CPU 相关的全部信息。
- /sbin(系统二进制) 和/bin类似,通常是系统启动必需的指令,也可以包括管理员才会使用的指令。
- /tmp(临时文件) 用于存放应用的临时文件,通常用的是tmpfs文件系统。因为tmpfs是一个内存文 件系统,系统重启的时候清除/tmp文件,所以这个目录不能放应用和重要的数据。
- /var (Variable data file,,可变数据文件) 用于存储运行时的数据,比如日志通常会存放 在/var/log目录下面。再比如应用的缓存文件、用户的登录行为等,都可以放到/var目录下,/var 下的文件会长期保存。
- /boot(启动) 目录下存放了 Linux 的内核文件和启动镜像,通常这个目录会写入磁盘最头部的分区, 启动的时候需要加载目录内的文件。
- /opt(Optional Software,可选软件) 通常会把第三方软件安装到这个目录。以后你安装软件的时 候,可以考虑在这个目录下创建。
- /root(root 用户家目录) 为了防止误操作,Linux 设计中 root 用户的家目录没有设计在/home/root 下,而是放到了/root目录。
- /home(家目录) 用于存放用户的个人数据,比如用户lagou的个人数据会存放到/home/lagou下 面。并且通常在用户登录,或者执行cd指令后,都会在家目录下工作。 用户通常会对自己的家目录拥 有管理权限,而无法访问其他用户的家目录。
- /media(媒体) 自动挂载的设备通常会出现在/media目录下。比如你插入 U 盘,通常较新版本的 Linux 都会帮你自动完成挂载,也就是在/media下创建一个目录代表 U 盘。
- /mnt(Mount,挂载) 我们习惯把手动挂载的设备放到这个目录。比如你插入 U 盘后,如果 Linux 没 有帮你完成自动挂载,可以用mount命令手动将 U 盘内容挂载到/mnt目录下。
- /svr(Service Data,,服务数据) 通常用来存放服务数据,比如说你开发的网站资源文件(脚本、网 页等)。不过现在很多团队的习惯发生了变化, 有的团队会把网站相关的资源放到/www目录下,也有的团队会放到/data下。总之,在存放资源的角度,还是比较灵活的。
/usr(Unix System Resource) 包含系统需要的资源文件,通常应用程序会把后来安装的可执行文件 也放到这个目录下,比如说
- vim编辑器的可执行文件通常会在/usr/bin目录下,区别于ls会在/bin目录下
- /usr/sbin中会包含有通常系统管理员才会使用的指令。
- /usr/lib目录中存放系统的库文件,比如一些重要的对象和动态链接库文件。
- /usr/lib目录下会有大量的
.so文件,这些叫作Shared Object,类似windows下的dll文 件。 - /usr/share目录下主要是文档,比如说 man 的文档都在/usr/share/man下面。
文件系统底层设计 FAT、NTFS 和 Ext3 文件系统有什么区别?
硬盘分块
- 使用硬盘和使用内存有一个很大的区别,内存可以支持到字节级别的随机存取,而这种情况在硬盘中通 常是不支持的。
- **为了提高性能,通常会将物理存储(硬盘)划分成一个个小块,**比如每个 4KB。这样做也可以让 硬盘的使用看起来非常整齐,方便分配和回收空间。况且,数据从磁盘到内存,需要通过电子设备,比 如 DMA、总线等,如果一个字节一个字节读取,速度较慢的硬盘就太耗费时间了,因此一次读/写一个块(Block)才是可行的方案。
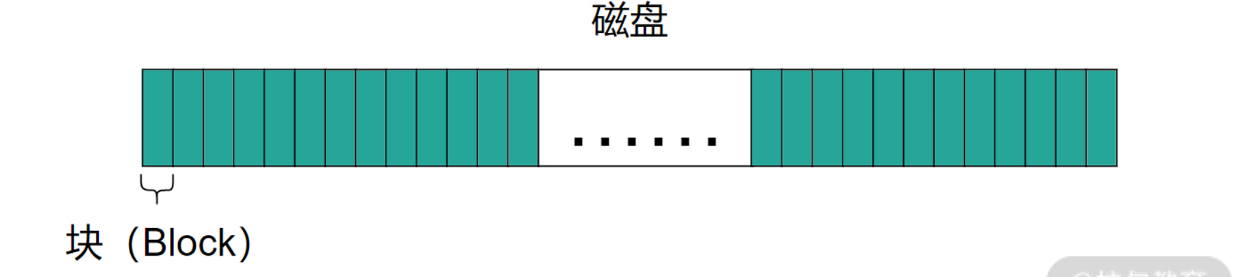
- 这样做还有一个好处就是如果你知道块的序 号,就可以准确地计算出块的物理位置。
文件的描述
如何利用上面的硬盘存储文件,就是文件系统(File System)要负责的事情了
- 3 种文件系统:
- 早期的 FAT 格式
- 基于 inode 的传统文件系统
- 日志文件系统(如 NTFS, EXT2、3、4)
这种文件索引节点(inode)的方式,完美地解决了 FAT 的缺陷,一直被沿用至今。FAT 要把所有的块 信息都存在内存中,索引节点只需要把用到的文件形成数据结构,而且可以使用虚拟内存分配空间,随 着页表置换,这就解决了 FAT 的容量限制问题
目录的实现
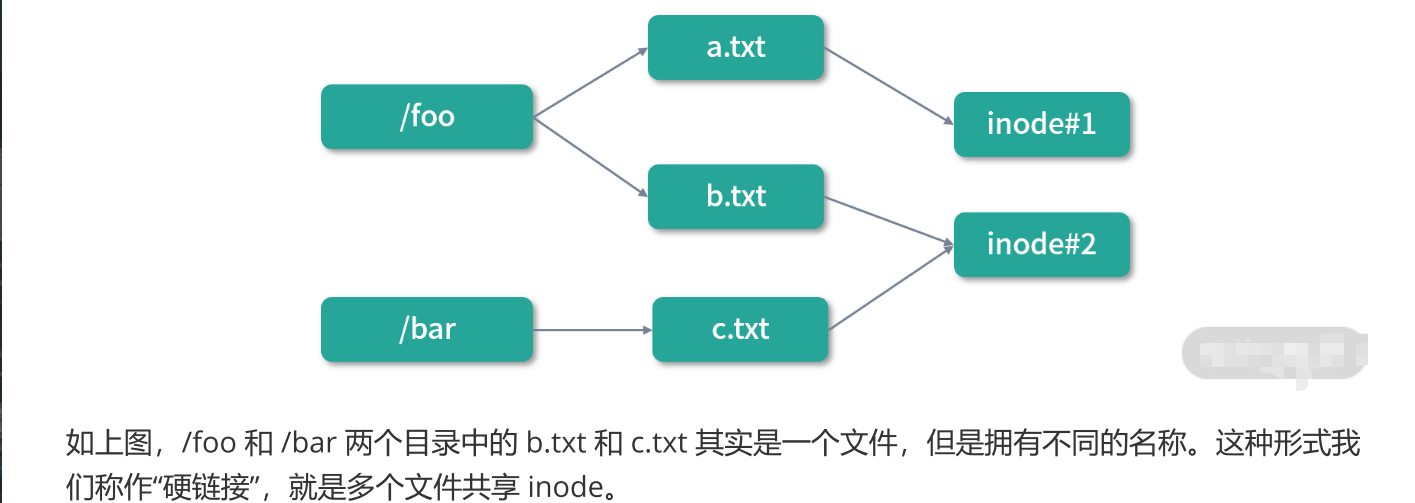
目录是特殊的文件,所以每个目录都有自己的 inode。目录是文件的集合,所以目录的内容中必须有所有其下文件的 inode 指针。
文件名也最好不要放到 inode 中,而是放到文件夹中。这样就可以灵活设置文件的别名,及实现一个文 件同时在多个目录下。

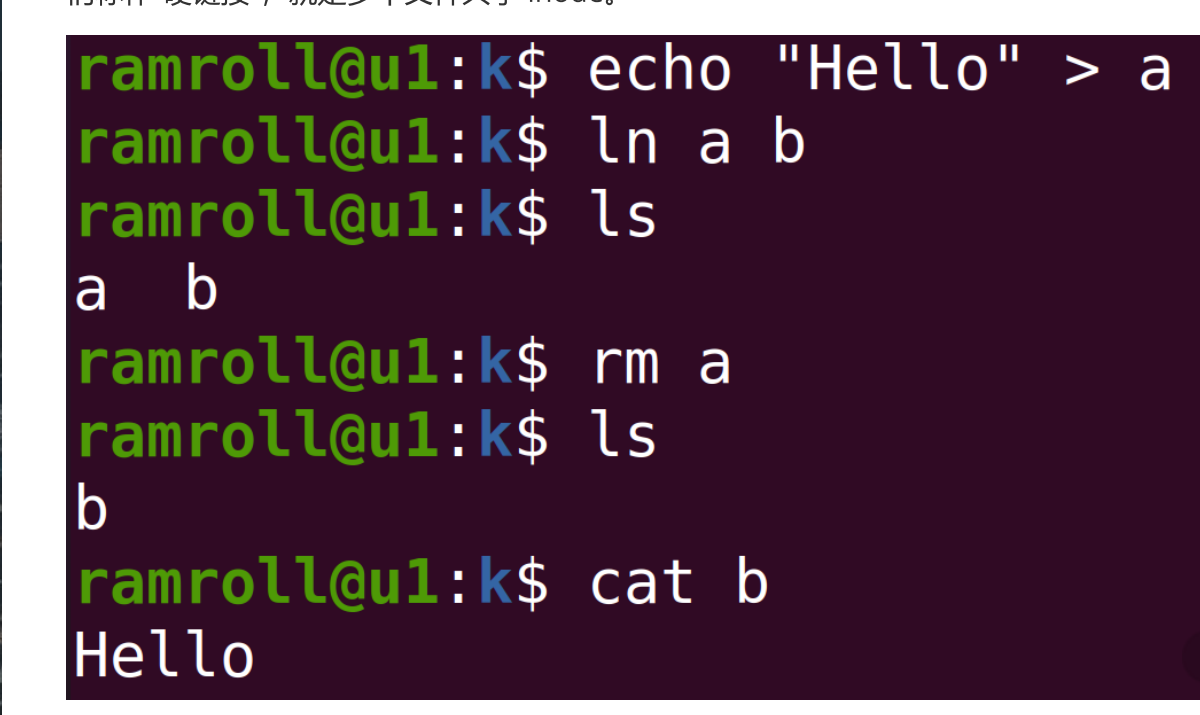
- 硬链接有一个非常显著的特点,硬链接的双方是平等的。上面的程序我们用ln指令为文件 a 创造了一 个硬链接b。如果我们创造完删除了 a,那么 b 也是可以正常工作的。如果要删除掉这个文件的 inode,必须 a,b 同时删除。这里你可以看出 a,b 是平等的。
软链接
软链接的原理如下图:
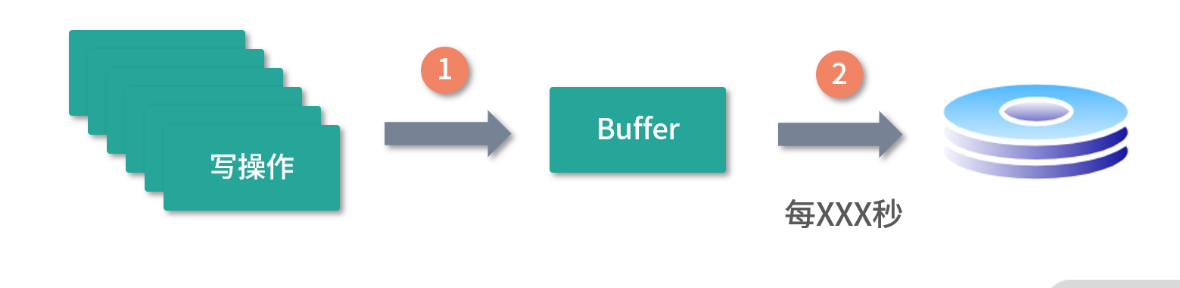
- 所有写操作先存入缓冲区,然后每过一定的秒数,才进行一次持久化。这种设计,是一个很好的 思路,但最大的问题在于容错。 比如上图的步骤 1 或者步骤 2 只执行了一半,如何恢复?如果步骤 2 只 写入了一半,那么数据就写坏了。如果步骤 1 只写入了一半,那么数据就丢失了。无论出现哪种问题, 都不太好处理。更何况写操作和写操作之间还有一致性问题,比如说一次删除 inode 的操作后又发生了 写入……

- 解决上述问题的一个非常好的方案就是利用日志。
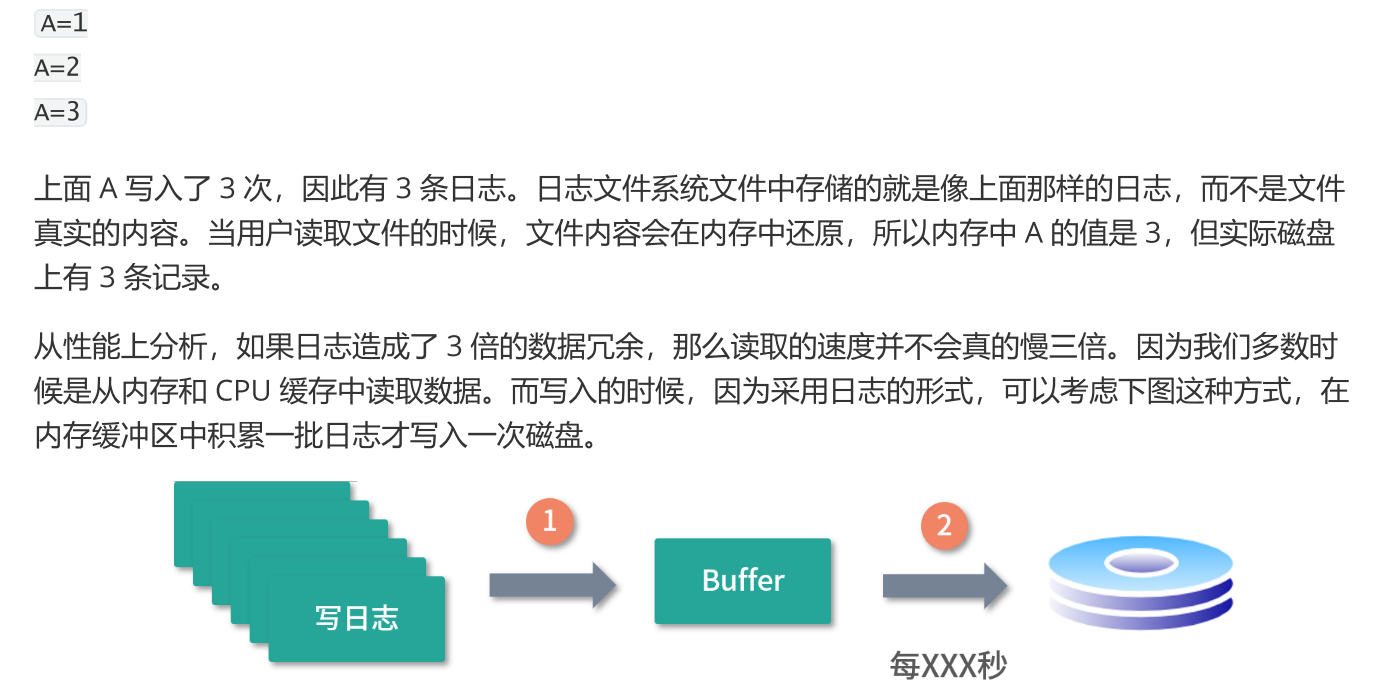
- 上图这种设计可以让写入变得非常快速,多数时间都是写内存,最后写一次磁盘。而上图这样的设计成不成立,核心在能不能解决容灾问题。
你可以思考一下这个问题——丢失一批日志和丢失一批数据的差别大不大。其实它们之间最大的差别在 于,如果丢失一批日志,只不过丢失了近期的变更;但如果丢失一批数据,那么就可能造成永久伤害。 - 为了进一步避免损失,一种可行的方案就是**创建还原点(Checkpoint),**比如说系统把最近 30s 的日志 都写入一个区域中。下一个 30s 的日志,写入下一个区域中。每个区域,我们称作一个还原点。创建还原点的时候,我们将还原点涂成红色,写入完成将还原点涂成绿色。
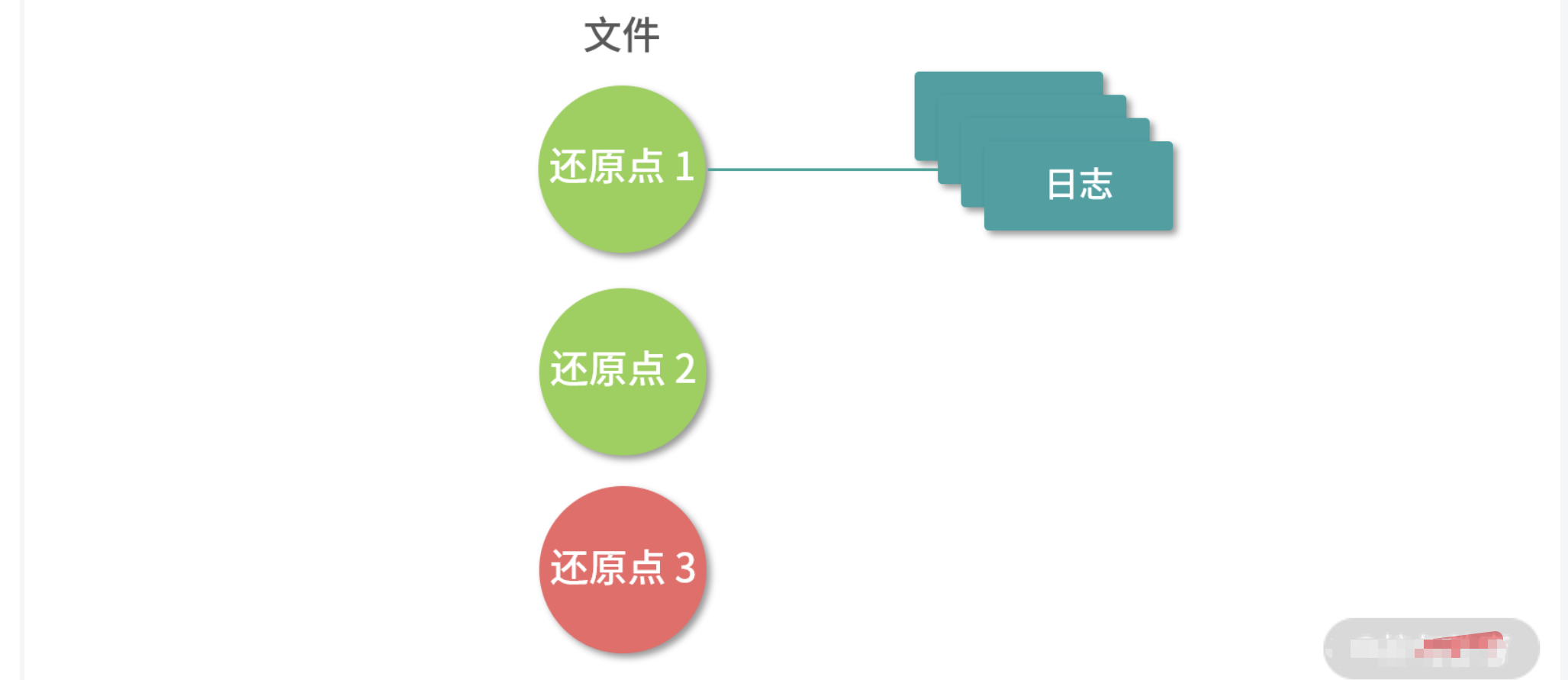
总结
- FAT 的设计简单高效,如果你要自己管理一定的空间,可以优先考虑这种设计。
- inode 的设计在内存中创造了一棵树状结构,对文件、目录进行管理,并且索引到磁盘中的数据。这是一种经典的数据结构,这种思路会被数据库设计、网络资源管理、缓存设计反复利用。
- 日志文件系统——日志结构简单、容易存储、按时间容易分块,这样的设计非常适合缓冲、批量写入和故障恢复。
多分布式系统的设计也是基于日志,比如 MySQL 同步数据用 binlog,Redis 的 AOF,著名的分布式一致性算法 Paxos ,因此 Zookeeper 内部也在通过实现日志的一致性来实现分布式一致性。
FAT、NTFS 和 Ext3 有什么区别?
【解析】FAT 通过内存中一个类似链表的结构,实现对文件的管理。NTFS 和 Ext3 是日志文件系统,它们和 FAT 最大的区别在于写入到磁盘中的是日志,而不是数据。日志文件系统会先把日志写入到内存中一个高速缓冲区,定期写入到磁盘。日志写入是追加式的,不用考虑数据的覆盖。一段时间内的日志内容,会形成还原点。这种设计大大提高了性能,当然也会有一定的数据冗余。
MySQL 的B树 和 B+树
B 树和 B+ 树是两种数据结构,构建了磁盘中的高速索引结构,因此不仅 MySQL 在用,MongoDB、Oracle 等也在用,基本属于数据库的标配常规操作。
行存储和列存储
行存储
行存储本质就是数据一个接着一个排列,一行数据后面 马上跟着另一行数据。如果订单表很大,一个磁盘块(Block)存不下,那么实际上就是每个块存储一定的行数。 类似下图这样的结构:

行存储更新一行的操作,往往可以在一个块(Block)中进行。而查询数据,聚合数据(比如求 4 月份的 订单数),往往需要跨块(Block)。因此, 行存储优点很明显,更新快、单条记录的数据集中,适合事务。但缺点也很明显,查询慢。
列存储(Column Storage)
列存储中数据是一列一列存的。还以订单表为 例,如下图所示:

- 每个列的数据都聚集在一起。
- 特别是更新某一条记录的时候,需要更新多 处,速度很慢。优势其实是在查询和聚合运算。
总结一下,行存储、列存储,最终都需要把数据存到磁盘块。行存储记录一个接着一个,列存储一列接 着一列。
为什么行存储更适合事务?
实适合不适合是相对的,说行存储适合是因为列存储非常不适合事务。试想一下,你更新一个表的若 干个数据,如果要在不同块中更新,就可能产生多次更新操作。更新次数越多,保证一致性越麻烦。在 单机环境我们可以上锁,可以用阻塞队列,可以用屏障……但是分布式场景中保证一致性(特别是强一致 性)开销很大。因此我们说行存储适合事务,而列存储不适合。
索引

- 如果我们想查询一个id,一般都会想到二分,但是直接在原始数据上排序,我们可能会把数据弄乱,常规做法是设计冗余数据描述这种排序关系—— 这就是索引
- 订单(10001)是第 2 个订单。但是进行排序后,订单(10001)会到第 1 个位置。这样会弄乱订单 ID(10001)和 金额(100.00)对应的关系。

- 用空间换时间,额外将订单列拷贝一份排序:

- 以上这种专门用来进行数据查询的额外数据,就是索引。索引中的一个数据,也称作索引条目。上面的 索引条目一个接着一个,每个索引条目是 <订单 ID, 序号> 的二元组。
- 所以我们不能用一种线性结构将磁盘排序。那么树呢? 比如二叉搜索树(Binary Serach Tree)行不行 呢?利用磁盘的空间形成一个二叉搜索树,例如将订单 ID 作为二叉搜索树的 Key。
- 复合索引,比如 <订单状态、日期、序号> 作为一个索引条目,其实就是先按照订单状态,再按照日期排序的索引。所以复合索引,无非就是多消耗一些空间,排序维度多一些。而且你可以看出复合索引和单列索引完全 是独立关系,所以我们可以认为每创造一组索引,就创造了一份冗余的数据。也创造了一种特别的查询 方式。
- 核心的问题:**上面的索引是一个连续的、从小到大的索引,**那么应不应该使用 这种从小到大排序的索引呢?? 应该 , 因为无论是单索引还是复合索引查询的时候都是继续二分查找.
二叉搜索树
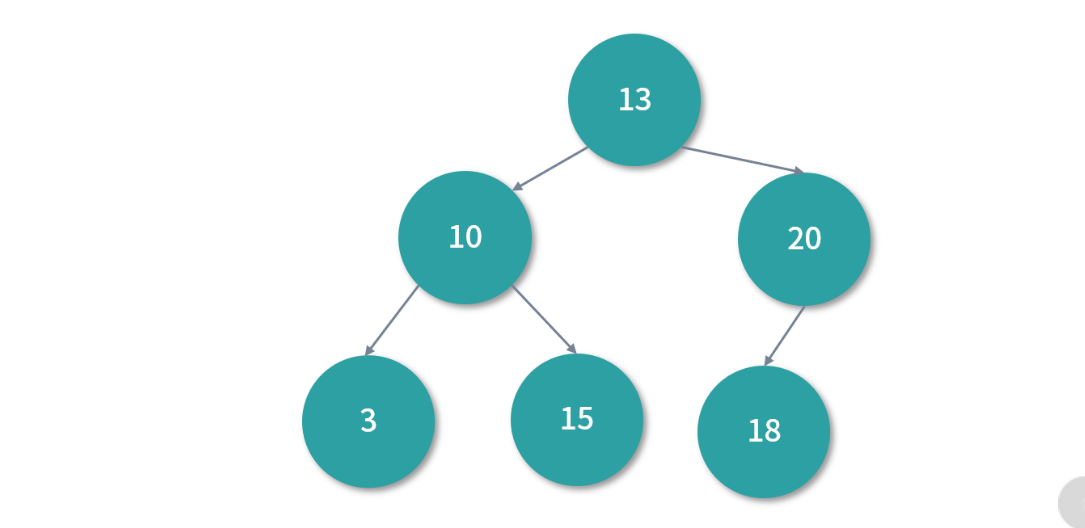
- 二叉搜索树的特点是一个节点的左子树的所有节点都小于这个节点,右子树的所有节点都 大于这个节点。而且,因为索引条目较少,确实可以考虑在查询的时候,先将足够大的树导入内存,然 后再进行搜索。搜索的算法是递归的,与二分查找非常类似,每次计算可以将问题规模减半。当然,具 体有多少数据可以导入内存,受实际可以使用的内存数量的限制。
- 每个节点的数 据分成 Key 和 Value ,
Key就是索引值. - 二叉搜索树是一个天生的二分查找结构,每次查找都可以减少一半的问题规模。而且二叉搜索树解决了 插入新节点的问题,因为二叉搜索树是一个跳跃结构,不必在内存中连续排列。这样在插入的时候,新节点可以放在任何位置,不会像线性结构那样插入一个元素,所有元素都需要向后排列。
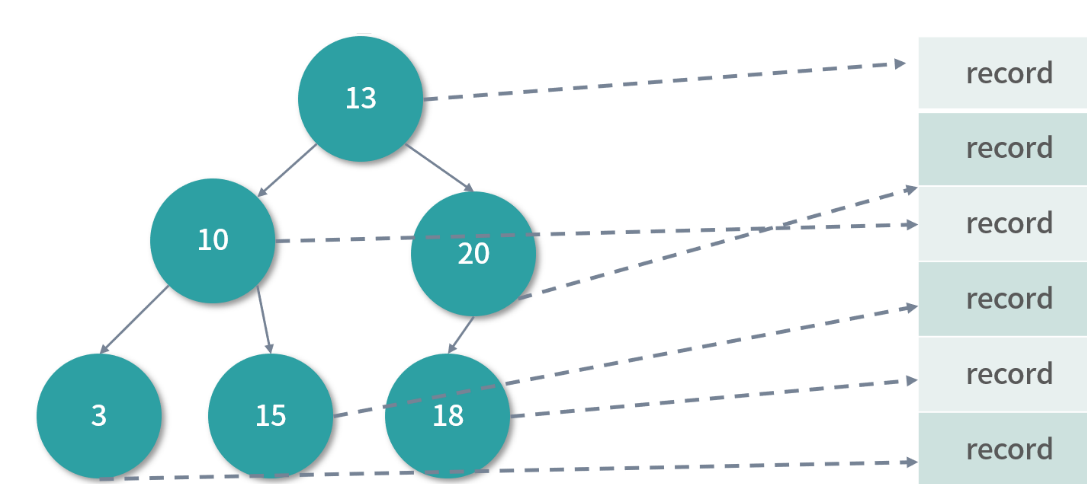
- 在使用磁盘的时候,二叉搜索树是不是一种合理的查询结构?
当然还不算,因此还需要继续优化我们的算法。二叉搜索树,在内存中是一个高效的数据结构。这是因 为内存速度快,不仅可以随机存取,还可以高频操作。注意 CPU 缓存的穿透率只有 5% 左右,也就是 95% 的操作是在更快的 CPU 缓存中执行的。而且即便穿透,内存操作也是在纳秒级别可以完成。
B 树和 B+ 树
B树
- 二叉搜索树解决了连续结构插入新元素开销很大的问题,同时又保持着天然的二分结构。**但是,**当需要 索引的数据量很大,无法在一个磁盘 Block 中存下整棵二叉搜索树的时候。每一次递归向下的搜索,实际都是读取不同的磁盘块。这个时候二叉搜索树的开销很大。
- 一个更好的方案,就是继续沿用树状结构,利用好磁盘的分块让每个节点多一些数据,并且允许子节点 也多一些,树就会更矮。因为树的高度决定了搜索的次数。
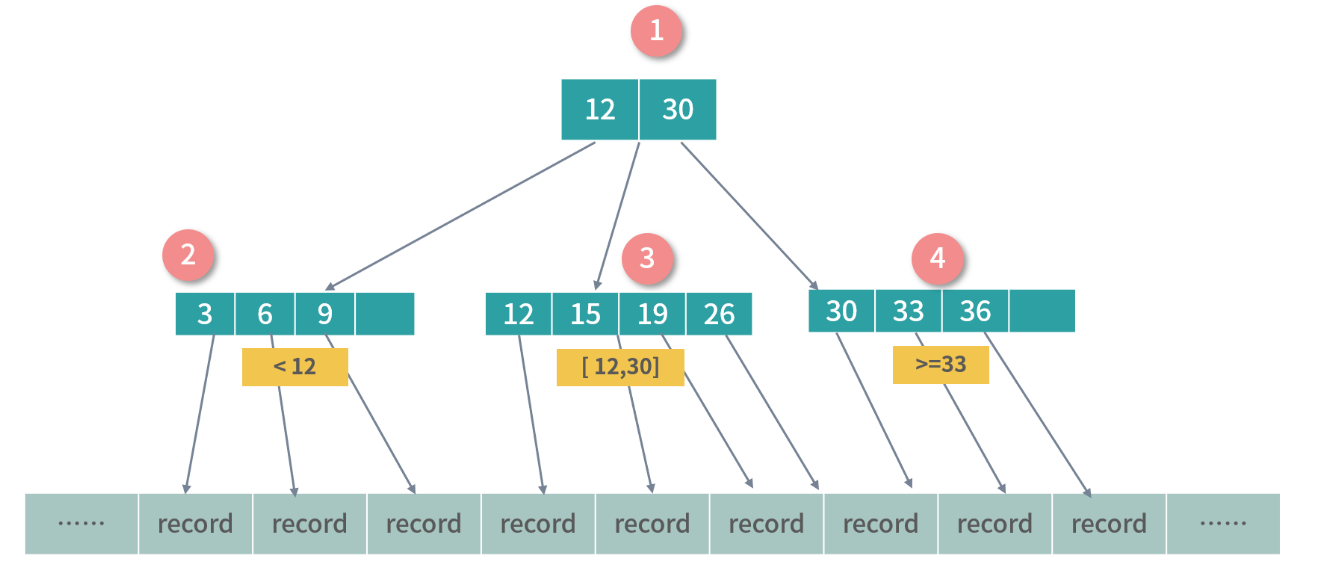
- B 树(B-Tree)
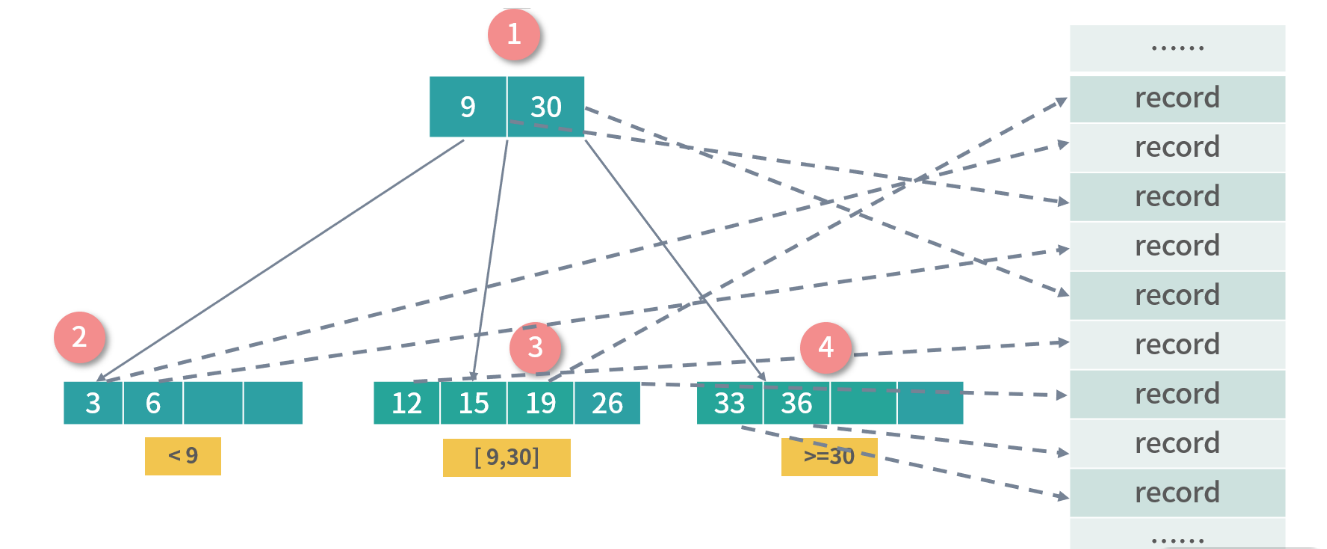
- 上图中的 B 树是一个 3-4 B 树,3 指的是每个非叶子节点允许最大 3 个索引,4 指的是每个节点最多允 许 4 个子节点,4 也指每个叶子节点可以存 4 个索引。
- B-Tree 是一种递归的搜索结构,与二叉搜索树非常类似。不同的是,B 树中的父节点中的数据会对子树 进行区段分割。
继承 B 树:B+ 树
- **B+ 树只有叶子节点才映射数据,**下图中是对 B 树设计的一种改进,节点 1 为冗余节点,它不存储数据,只划定子树数据的范围。你可以看到节点 1 的索引 Key:12 和 30,在节点 3 和 4 中也有一份。
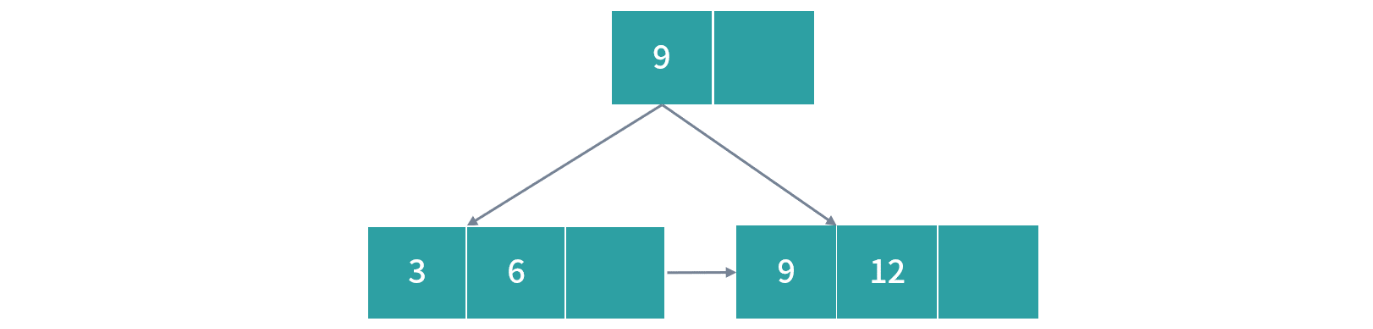
树的形成:插入
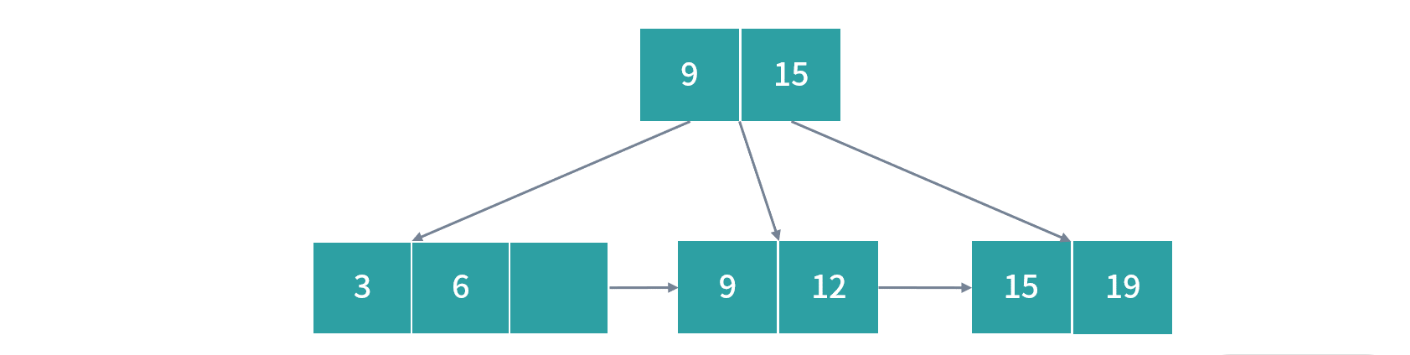
- 在 2-3 B+ 树中依次插入 3,6,9,12,19,15,26,8,30
- 插入 3,6,9 过程很简单,都写入一个节点即可,因为叶子节点最多允许每个 3 个索引。接下来我们插入 12,会发生一次过载,然后节点就需要拆分,这个时候按照 B+ 树的设计会产生冗余节点。

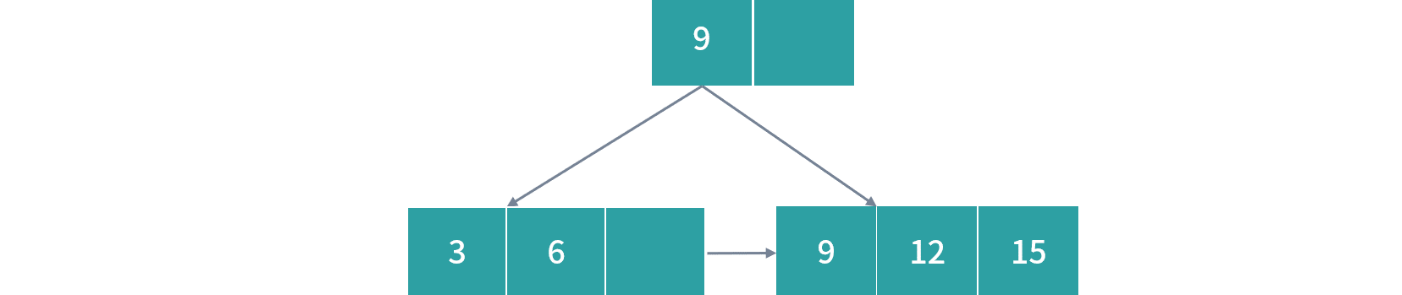
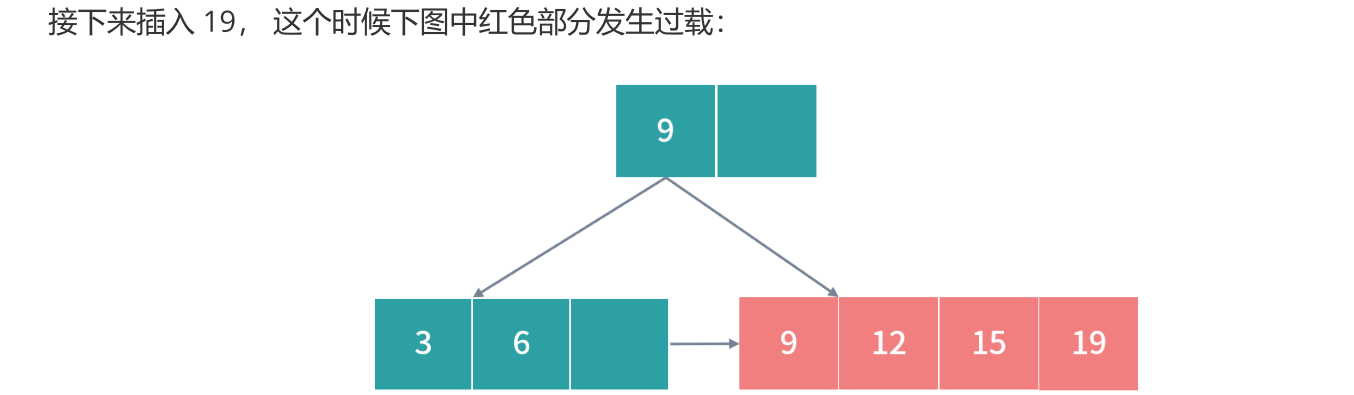
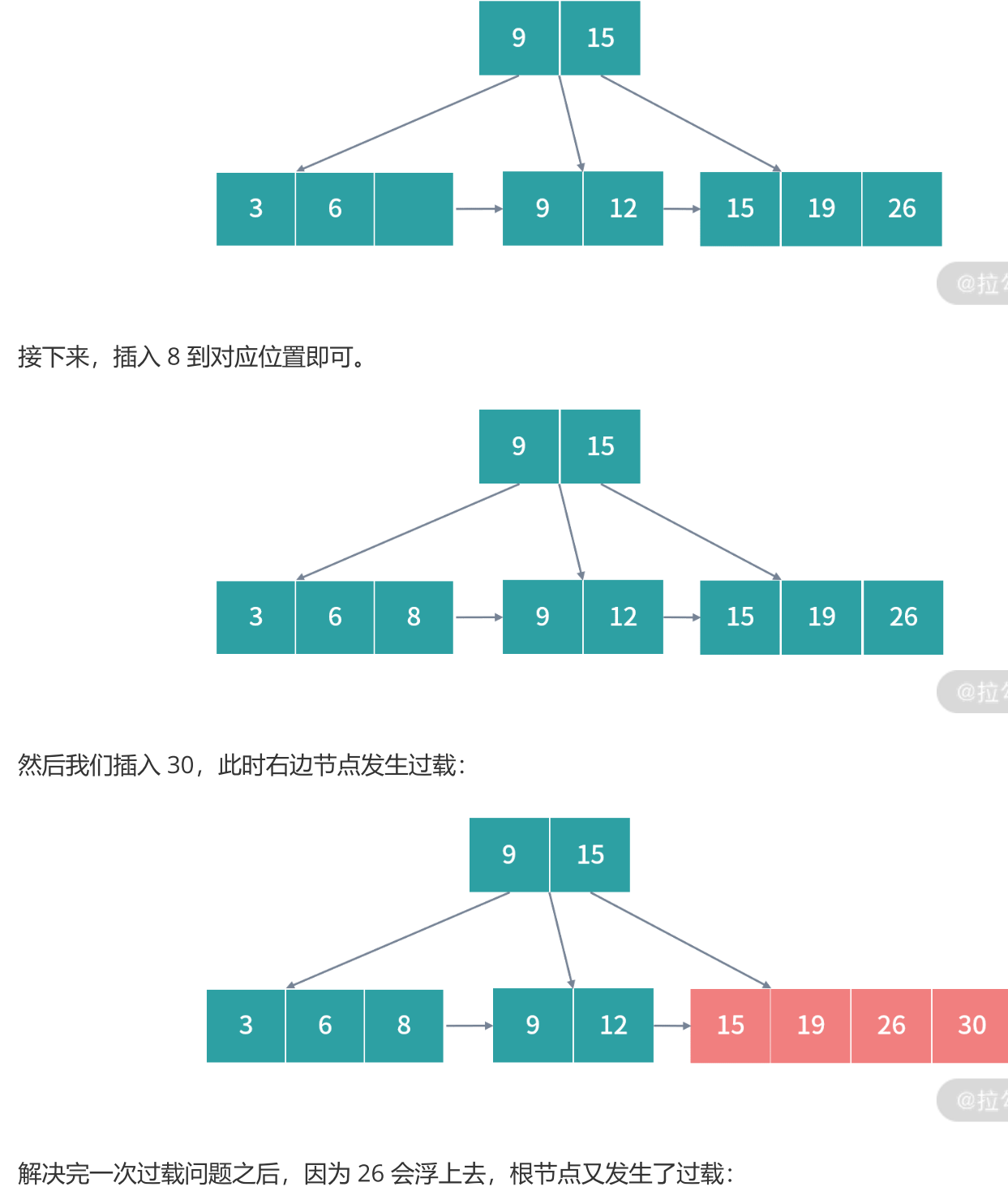
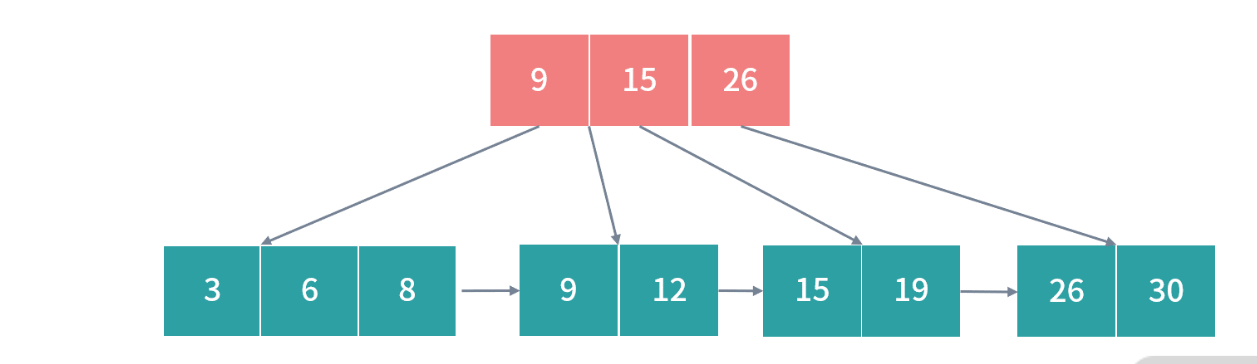
再次解决过载,拆分红色部分,得到最后结果:
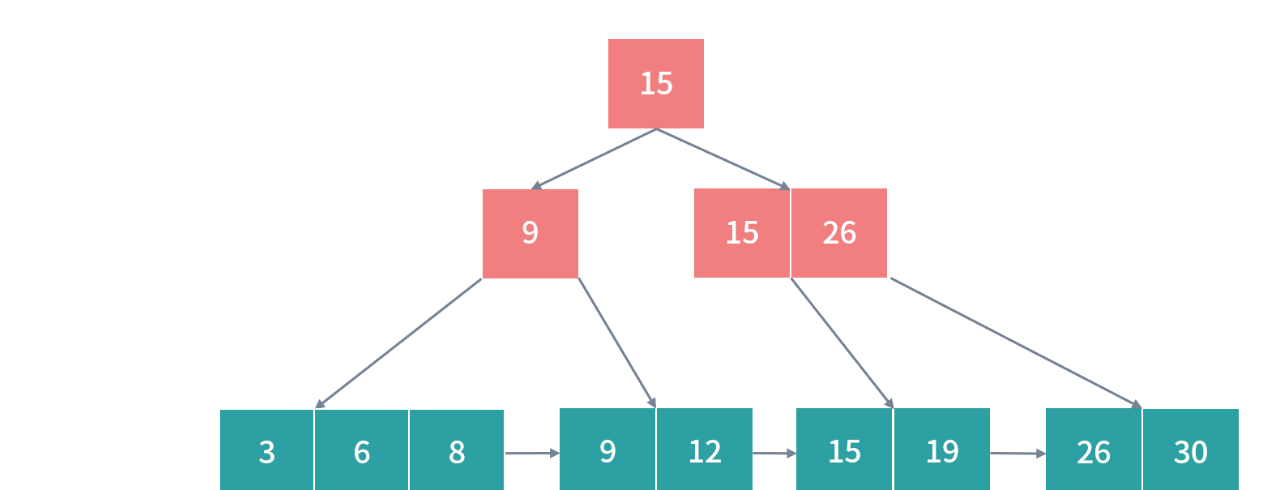
- B+ 树始终可以保持平衡状态,而且所有叶子节点都在同一层级。
插入和删除效率
- B+ 树有大量的冗余节点,比如删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点。这样删除非常快。B 树则不同,B 树没有冗余节点,删除节点的时候非常复杂。比如删除根节点 中的数据,可能涉及复杂的树的变形。
- B+ 树的插入也是一样,有冗余节点,插入可能存在节点的拆分(如果节点饱和),但是最多只涉及树的 一条路径。而且 B+ 树会自动平衡。
因此,B+ 树的插入和删除效率更高。
搜索:链表的作用
- B 树和 B+ 树搜索原理基本一致。先从根节点查找,然后对比目标数据的范围,最后递归的进入子节点 查找。
你可能会注意到,B+ 树所有叶子节点间还有一个链表进行连接。这种设计对范围查找非常有帮助,比如 说我们想知道 1 月 20 日和 1 月 22 日之间的订单,这个时候可以先查找到 1 月 20 日所在的叶子节点, 然后利用链表向右遍历,直到找到 1 月22 日的节点。这样我们就进一步节省搜索需要的时间。
总结
- 如果是存储海量数据的数据库,我们的思考点需要放在 I/O 的效率上。如果把今天的知识放到分布式数据库上,那除了需要节省磁盘读写还需要节省网络 I/O。
MySQL 中的 B 树和 B+ 树有什 么区别?
【解析】 B+ 树继承于 B 树,都限定了节点中数据数目和子节点的数目。B 树所有节点都可以映射数据, B+ 树只有叶子节点可以映射数据。
单独看这部分设计,看不出 B+ 树的优势。为了只有叶子节点可以映射数据,B+ 树创造了很多冗余的索 引(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,而且可以自 动平衡,因此 B+ 树的所有叶子节点总是在一个层级上。所以 B+ 树可以用一条链表串联所有的叶子节点,也就是索引数据,这让 B+ 树的范围查找和聚合运算更快。
分布式文件系统和数据库
分布式文件系统通过计算机网络连接大量物理节点,将不同机器、不同磁 盘、不同逻辑分区的数据组织在一起,提供海量的数据存储(一般是 Petabytes 级别,1PB = 1024TB)。分布式数据库则在分布式文件系统基础上,提供应对具体场景的海量数据解决方案。
存储所有的网页
- 作为搜索引擎最核心的一个能力,就是要存储所有的网页。
- 搜索引擎不单单要存下这些页面,而且搜索引擎还需要存储这些网页的历史版本。
模型的选择
- 应该用何种模型存下这个巨大的网页表?
- 网页的历史版本,可以用 URL+ 时间戳进行描述。但是为了检索方便,网页不仅有内容,还有语言、外 链等。在存储端可以先不考虑提供复杂的索引,比如说提供全文搜索。但是我们至少应该提供合理的数 据读写方式等等等
- 先看看行存储,可不可以满足需求。比如每个网页( URL) 的数据是一行。 看似这个方案可行, 可惜列不是固定。比如外链可能有很多个,如下表:

列不固定,不仅仅是行的大小不好确定,而是表格画不出来。何况每一列内容还可能有很多版本,不同 版本是搜索引擎的爬虫在不同时间收录的内容,再加上内容本身也很大,有可能一个磁盘 Block都存不下
- 因为列是不确定的,这种情况下只能考虑用
Key-Value结构,也就是 Map 存储。Map 是一种抽象的数 据结构,本质是 Key-Value 数据的集合。 作为搜索引擎的支撑,Key 可以考虑设计为 <URL, Column, 时间戳> 的三元组,值就是对应版本的数据。 - 列名(Column)可以考虑分成两段,用:分隔开。列名包括列家族(Family) 、列标识(Qualifier)。 这样设计是因为有时候多个列描述的是相似的数据,比如说外链(Anchor),就是一个列家族。然后百度、搜狐是外链家族的具体的标识(Qualifier)。比如来自百度页面 a 外链的列名是 anchor:baidu.com/a。分成家族还有一个好处就是权限控制,比如不同部门的内部人员可以访问不同 列家族的数据。当然有的列家族可能只有一个列,比如网页语言;有的列家族可能有很多列,比如外 链。
这个巨大的 Map(Key-Value)的集合应该用什么数据结构呢?
- 设计想法一 : 通过 B+ 树,这样即便真的有海量的数据,也可以在少数几次、几十次查询内完成找到 URL 对应的数据。况且,我们还可以设计缓存, B+ 树需要一种顺序,比较好的做法是 URL 以按照字典序排列。这是因为,相同域名的网页资源同时被 用到的概率更高,应该安排从物理上更近,尽量把相同域名的数据放到相邻的存储块中(节省磁盘操作), 可以考虑分列存储。那么行内用什么数据结构呢?如果列非常多,也 可以考虑继续用 B+ 树。还有一种设计思路,是先把大表按照行拆分,比如若干行形成一个小片称作 Tablet,然后 Tablet 内部再使用列存储
查询和写入
当客户端查询的时候,请求参数中会包含 <URL, 列名>,这个时候我们可以通过 B+ 树定位到具体的行 (也就是URL对应的数据)所在的块,再根据列名找到具体的列。然后,将一列数据导入到内存中,最后在内存中找到对应版本的数据。客户端写入时,也是按照行→列的顺序,先找到列,再在这一列最后面追加数据。 对于修改、删除操作可以考虑不支持,因为所有的变更已经记录下来了。
分片(Tablet)的抽象
假设存储网页的表有几十个 PB,那么先水平分表,就是通过行(URL) 分表。URL 按照字典排序,相邻的 URL 数据从物理上也会相近。水平分表的结果,字典序相近的行(URL)数据会形成分片(Tablet), Tablet 这个单词类似药片的含义。
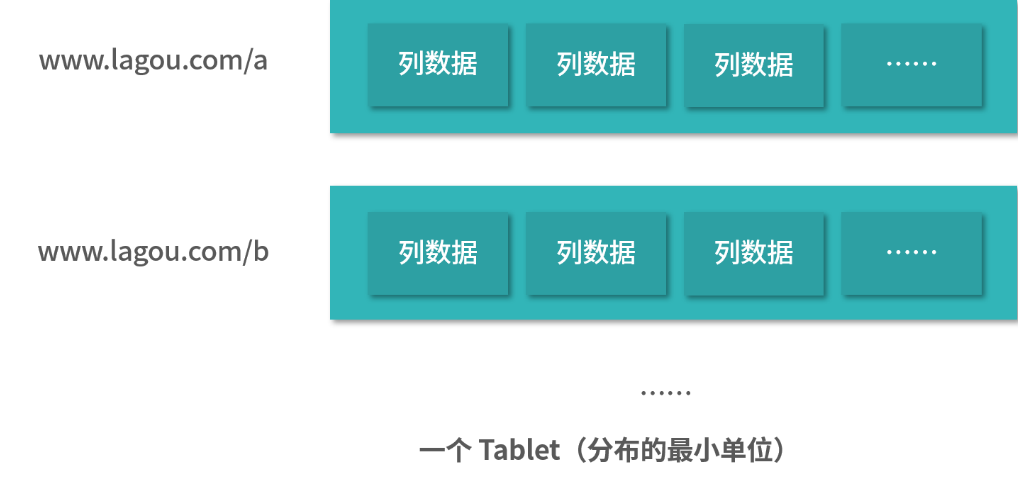
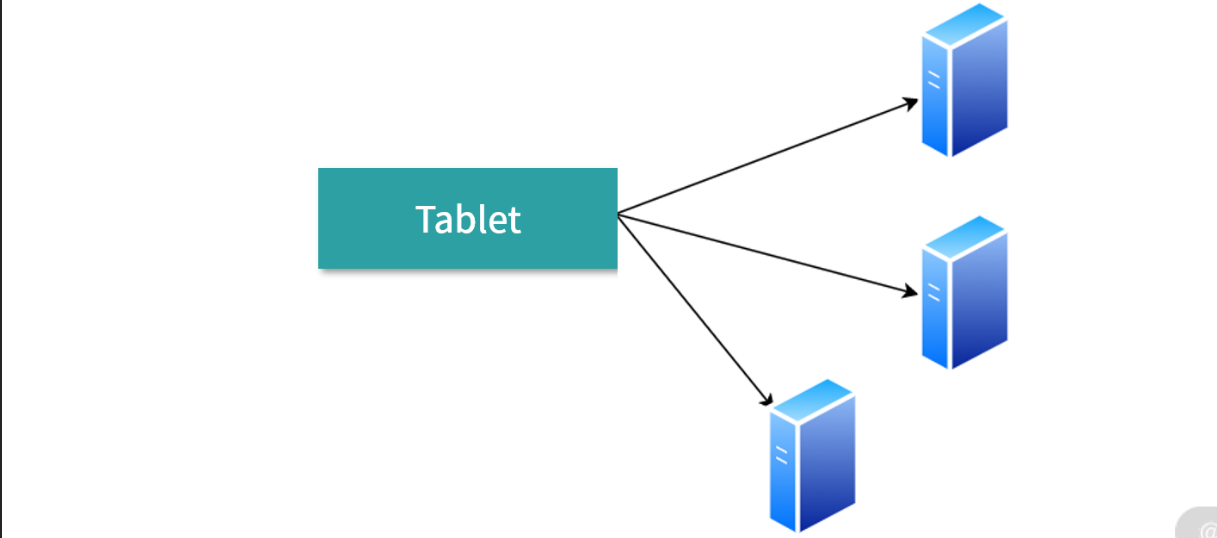
分片(Tablet),可以作为数据分布的最小单位。分片内部可以考虑图上的行存储,也可以考虑内部是一个 B+ 树组织的列存储。为了实现分布式存储,每个分片可以对应一个分布式文件系统中的文件。假设这个分布式文件系统接入 了 Linux 的虚拟文件系统,使用和操作会同 Linux 本地文件并无二致。其实不一定会这样实现,这只是 一个可行的方案。
为了存储安全,一个分片最少应该有 2 个副本,也就是 3 份数据。
块(Chunk)的抽象
- 比分片更小的单位是块(Chunk),这个单词和磁盘的块(Block)区分开。Chunk 是一个比 Block 更 大的单位。eg.Google File System 把数据分成了一个个 Chunk,然后每个 Chunk 会对应具体的磁盘块 (Block)
- 如下图,Table 是最顶层的结构,它里面含有许多分片(Tablets)。从数据库层面来看,每个分片是一 个文件。数据库引擎维护到这个层面即可,至于这个文件如何在分布式系统中工作,就交给底层的文件 系统——比如 Google File System 或者 Hadoop Distributed File System。
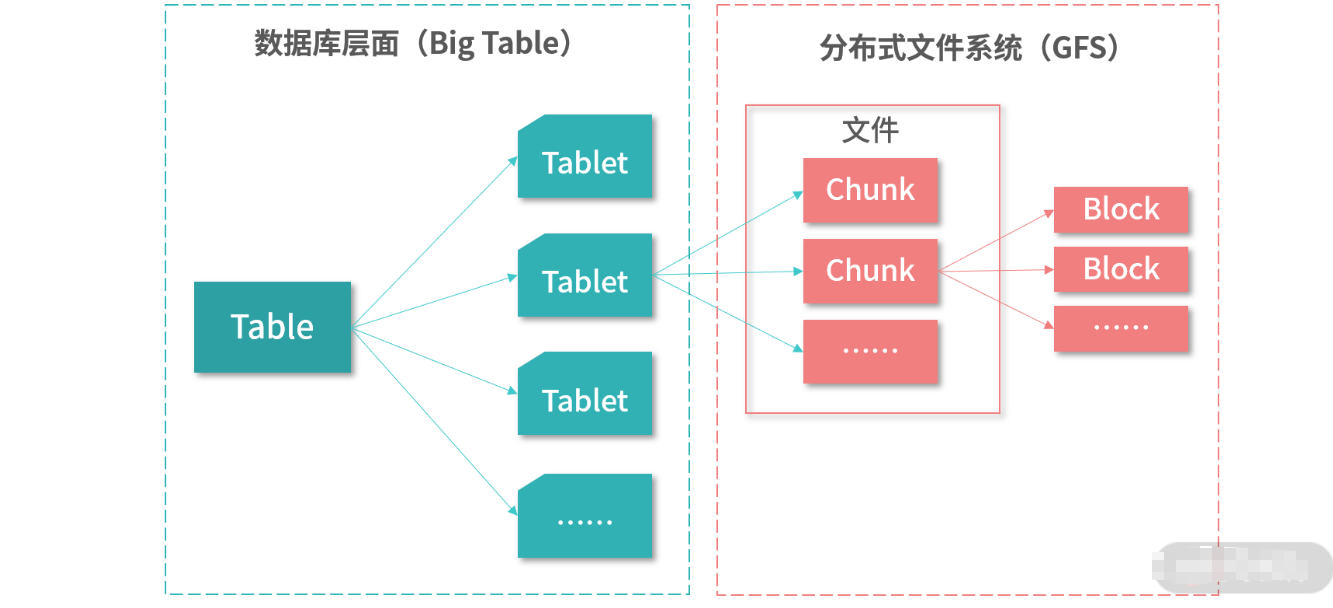
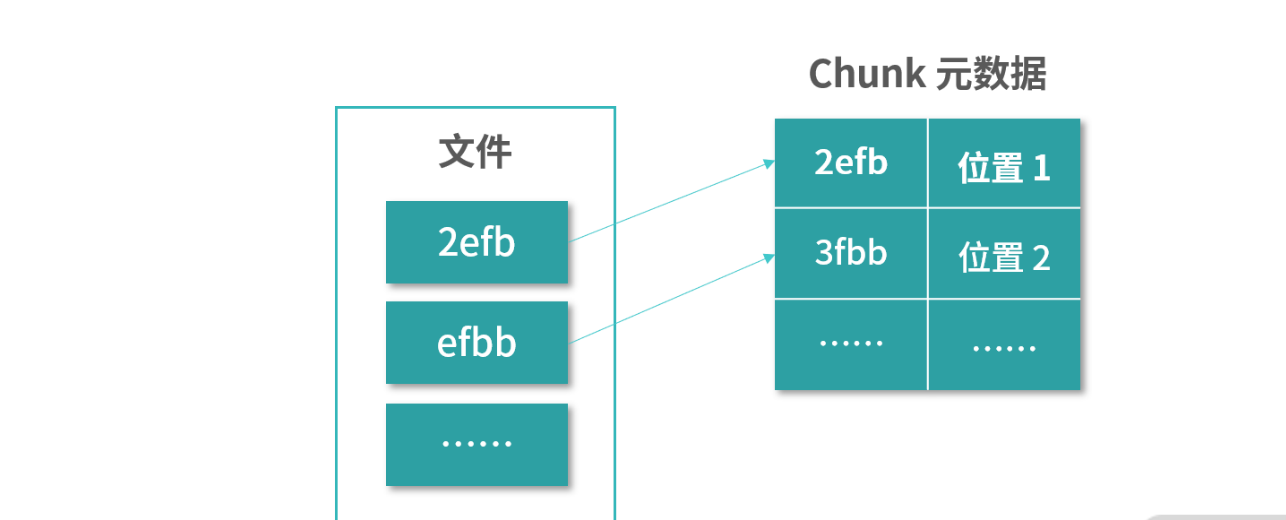
- 分布式文件系统通常会在磁盘的 Block 上再抽象一层 Chunk。一个 Chunk 通常比 Block 大很多,比如 Google File System 是 64KB,而通常磁盘的
Block大小是4K;HDFS则是128MB。这样的设计是为了 减少I/O操作的频率,分块太小I/O频率就会上升,分块大I/O频率就减小。 比如一个 Google 的爬虫 积攒了足够多的数据再提交到 GFS 中,就比爬虫频繁提交节省网络资源。
分布式文件的管理(待补充)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
文件的管理(待补充)
[外链图片转存中…(img-R8zctzpI-1715789572070)]
[外链图片转存中…(img-mUQZ2qqE-1715789572070)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









