




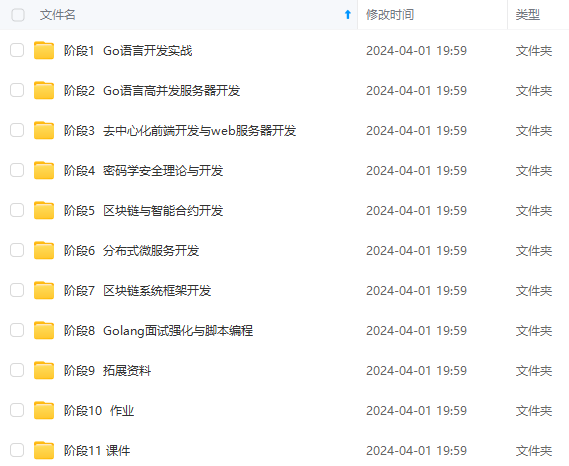
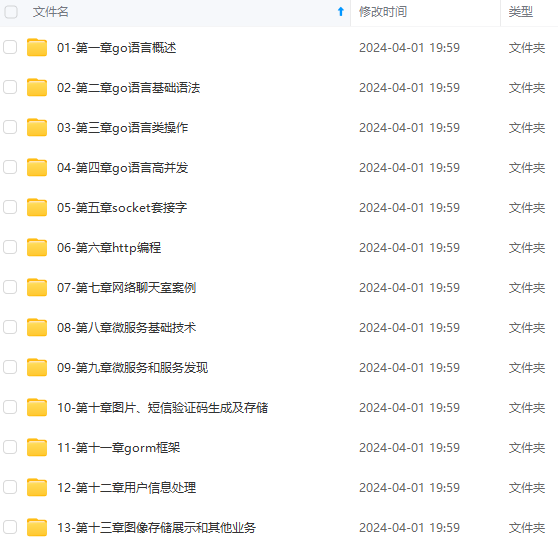
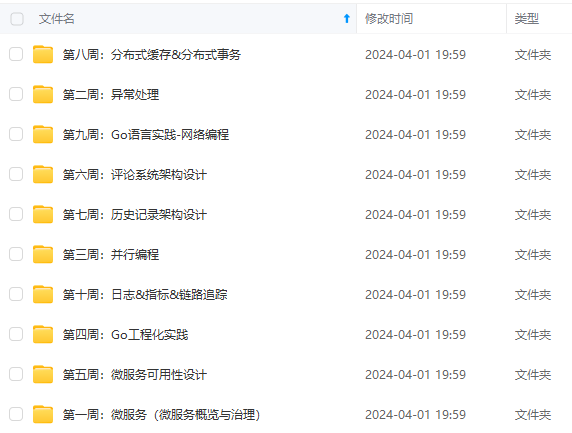
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
// @syscall
type EpollEvent struct {
Events uint32
Fd int32
Pad int32
}
// @runtime
type epollevent struct {
events uint32
data [8]byte // unaligned uintptr
}
我们看到,runtime 使用的 epollevent 是系统层 epoll 定义的原始结构;而对外版本则对其做了封装,将 epoll_data(epollevent.data) 拆分为固定的两字段:Fd 和 Pad。那么 runtime 又是如何使用的呢?在源码里我们看到这样的逻辑:
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
pd := *(**pollDesc)(unsafe.Pointer(&ev.data))
显然,runtime 使用 epoll_data(&ev.data) 直接存储了 fd 对应结构体(pollDesc)的指针,这样在事件触发时,可以直接找到结构体对象,并执行相应逻辑。而对外版本则由于只能获得封装后的 Fd 参数,因此需要引入额外的 Map 来增删改查结构体对象,这样性能肯定相差很多。
所以我们果断抛弃了 syscall.EpollWait,转而仿照 runtime 自行设计了 EpollWait 调用,同样采用 unsafe.Pointer 存取结构体对象。测试表明,该方案下 吞吐量 ↑10%,TP99 ↓10%,获得了较为明显的收益。
Thrift 序列化/反序列化优化
序列化是指把数据结构或对象转换成字节序列的过程,反序列化则是相反的过程。RPC 在通信时需要约定好序列化协议,client 在发送请求前进行序列化,字节序列通过网络传输到 server,server 再反序列进行逻辑处理,完成一次 RPC 请求。Thrift 支持 Binary、Compact 和 JSON 序列化协议。目前公司内部使用的基本都是 Binary,这里只介绍 Binary 协议。
Binary 采用 TLV 编码实现,即每个字段都由 TLV 结构来描述,TLV 意为:Type 类型, Lenght 长度,Value 值,Value 也可以是个 TLV 结构,其中 Type 和 Length 的长度固定,Value 的长度则由 Length 的值决定。TLV 编码结构简单清晰,并且扩展性较好,但是由于增加了 Type 和 Length,有额外的内存开销,特别是在大部分字段都是基本类型的情况下有不小的空间浪费。
序列化和反序列的性能优化从大的方面来看可以从空间和时间两个维度进行优化。从兼容已有的 Binary 协议来看,空间上的优化似乎不太可行,只能从时间维度进行优化,包括:
-
减少内存操作次数,包括内存分配和拷贝,尽量预分配内存,减少不必要的开销;
-
减少函数调用次数,比如可调整代码结构和 inline 等手段进行优化;
调研
根据 go_serialization_benchmarks 的压测数据,我们找到了一些性能卓越的序列化方案进行调研,希望能够对我们的优化工作有所启发。
通过对 protobuf、gogoprotobuf 和 Cap’n Proto 的分析,我们得出以下结论:
-
网络传输中出于 IO 的考虑,都会尽量压缩传输数据,protobuf 采用了 Varint 编码在大部分场景中都有着不错的压缩效果;
-
gogoprotobuf 采用预计算方式,在序列化时能够减少内存分配次数,进而减少了内存分配带来的系统调用、锁和 GC 等代价;
-
Cap’n Proto 直接操作 buffer,也是减少了内存分配和内存拷贝(少了中间的数据结构),并且在 struct pointer 的设计中把固定长度类型数据和非固定长度类型数据分开处理,针对固定长度类型可以快速处理;
从兼容性考虑,不可能改变现有的 TLV 编码格式,因此数据压缩不太现实,但是 2 和 3 对我们的优化工作是有启发的,事实上我们也是采取了类似的思路。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









